




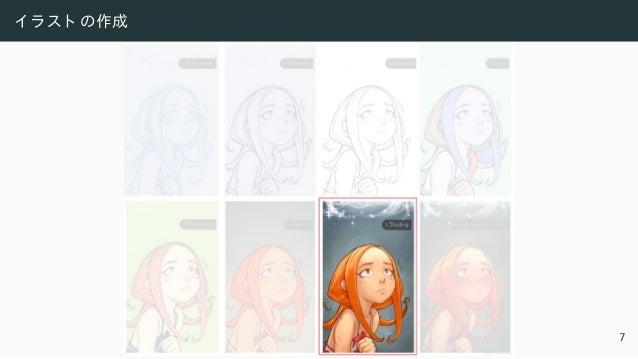
![AI で生成さ れたアート
• Computers Do Not Make Art [Hertzmann 2020]
• アート はソ ーシャ ルアク ティ ビティ
• コ ード やデータ は人間が集める
• AI はアート を 作れずにただのツ ール
• Christie で$432,500 の GAN を 売買
4](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-6-638.jpg)
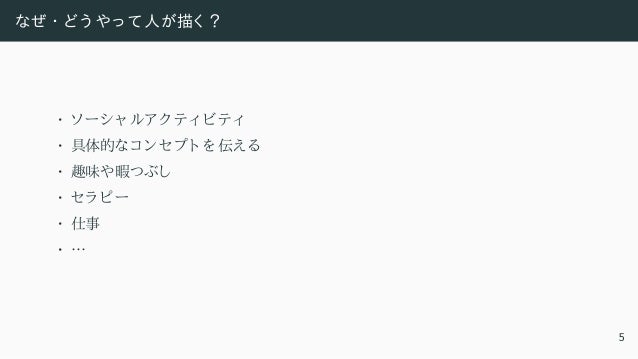

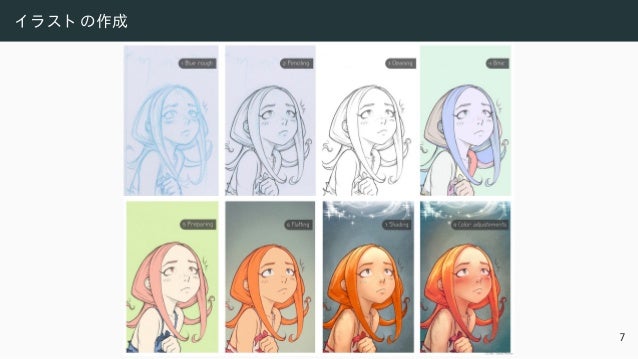
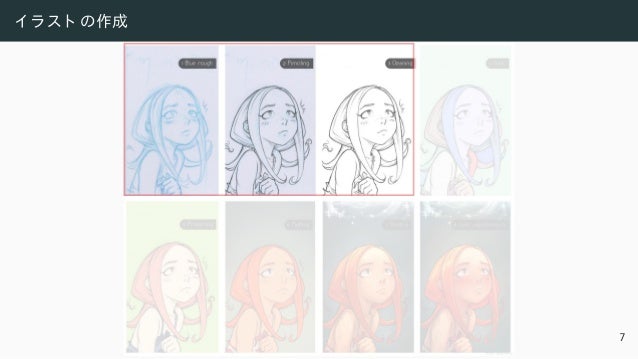
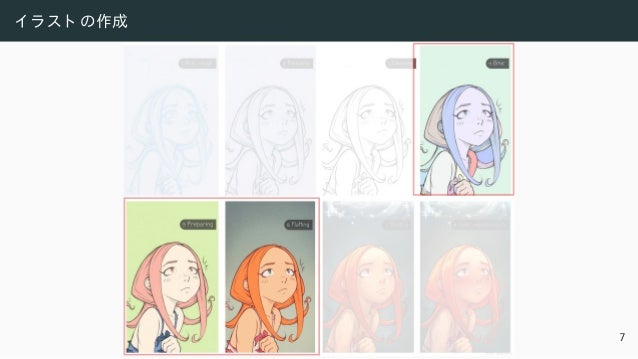
































![敵対的学習
min
S
max
D
教師あり
z }| {
E(x,y∗)∼ρx,y
通常教師あり ロ ス
z }| {
kS(x) − y∗
k2 +
教師あり 敵対的ロ ス
z }| {
α log D(y∗
) + α log(1 − D(S(x)))
+ β
線画
z }| {
Ey∼ρy [ log D(y) ] + β
ラ フ スケッ チ
z }| {
Ex∼ρx [ log(1 − D(S(x))) ]
| {z }
教師なし 敵対的ロ ス
入力 通常ロ ス + 敵対的ロ ス + 教師なし ロ ス
22](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-45-638.jpg)





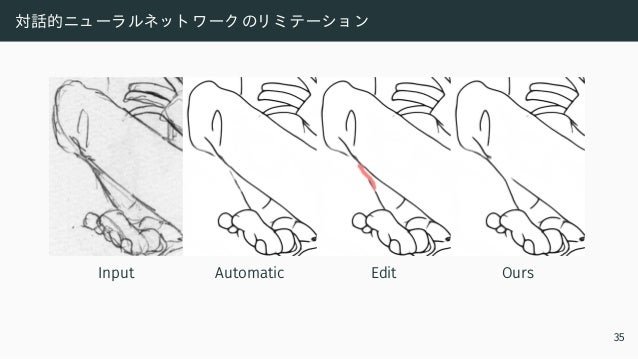
![全自動の限界
“1. The inker’s main purpose is to translate the penciller’s graphite pencil lines
into reproducible, black, ink lines.
2. The inker must honor the penciller’s original intent while adjusting any obvious
mistakes.
3. The inker determines the look of the finished art.”
— Gary Martin, The Art of Comic Book Inking [1997]
24](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-51-638.jpg)
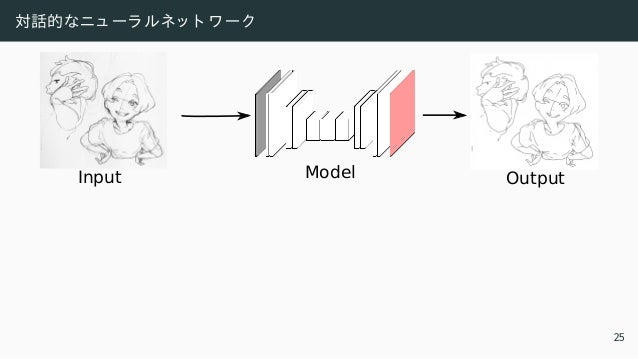
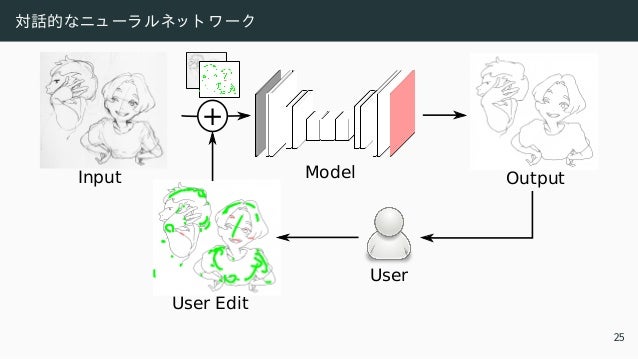
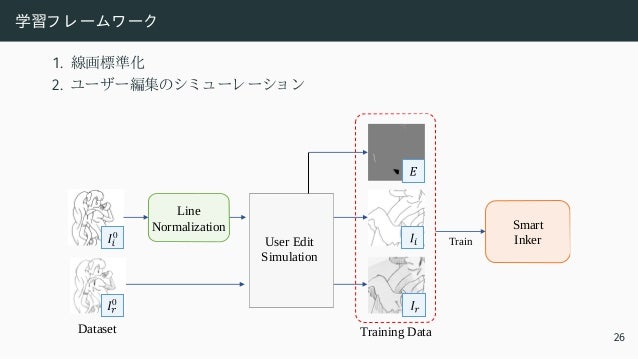
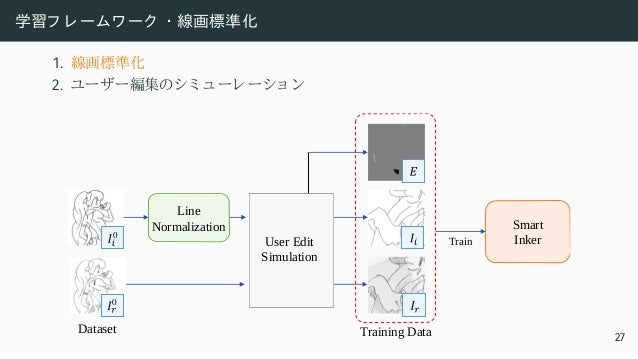
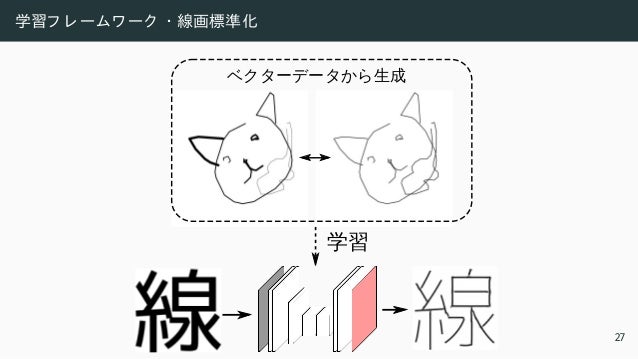
![学習フ レ ームワ ーク ・ 線画標準化
Input [Zhang and Suen 1984] Ours
27](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-57-638.jpg)




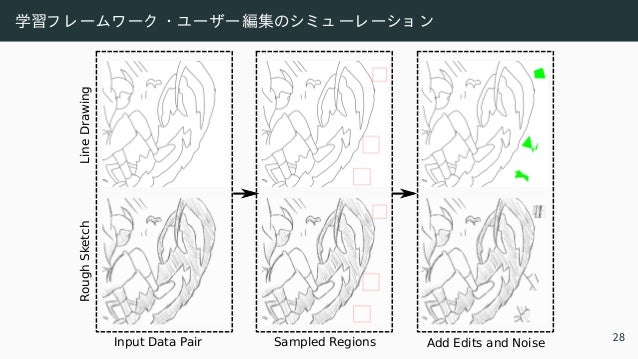



![(1 + γ (1 − y∗
))
| {z }
Weight lines with γ
|
• L1 ロ スを 使用
• γ の重みで線に重視
103
104
105
103
104
105
103
104
105
103
104
105
Input [Simo-Serra+ 2016] Baseline Ours
©David Revoy www.davidrevoy.com 29](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-66-638.jpg)
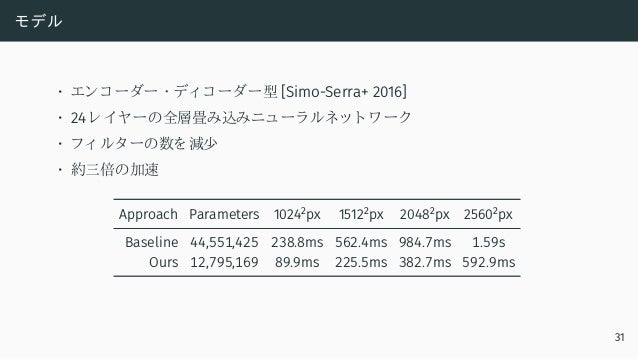
![モデル
• エンコ ーダー ・ ディ コ ーダー型 [Simo-Serra+ 2016]
• 24 レ イ ヤーの全層畳み込みニュ ーラ ルネッ ト ワ ーク
• フ ィ ルタ ーの数を 減少
• 約三倍の加速
Approach Parameters 10242
px 15122
px 20482
px 25602
px
Baseline 44,551,425 238.8ms 562.4ms 984.7ms 1.59s
Ours 12,795,169 89.9ms 225.5ms 382.7ms 592.9ms
31](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-68-638.jpg)











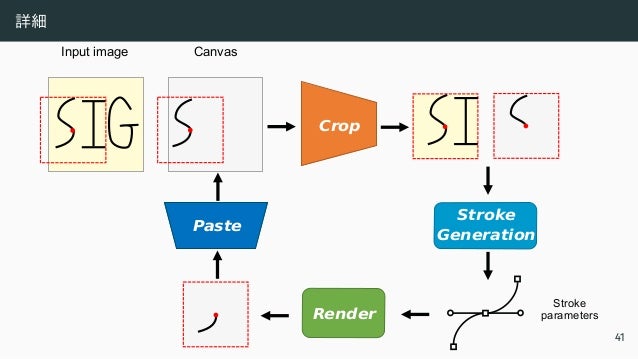
![スト ローク と は
• 二次ベジェ曲線
B(τ) = (1 − τ)2
P0 + 2(1 − τ)τP1 + τ2
P2, τ ∈ [0, 1] (1)
• (0, 0) から 描く ので、 P0 = 0
• モデルの出力
at = xc, yc, ∆x, ∆y, w
| {z }
曲線のパラ メ ータ と 幅 w
, ∆s, p
t
, t = 1, 2, ..., T (2)
• [−1, +1] の座標系
• ∆s は Canvas のスケール変更
• p ∈ [0, 1] は線を 描く か移動だけする か決める 変数
40](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-82-638.jpg)



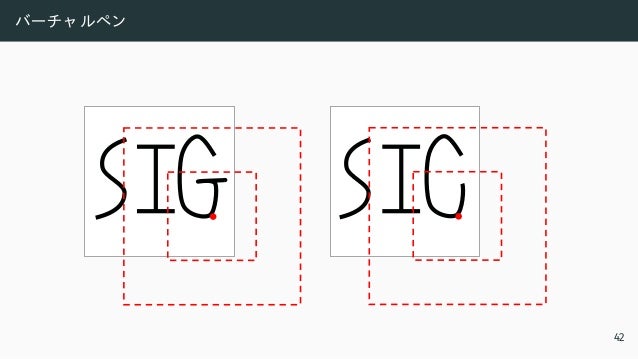
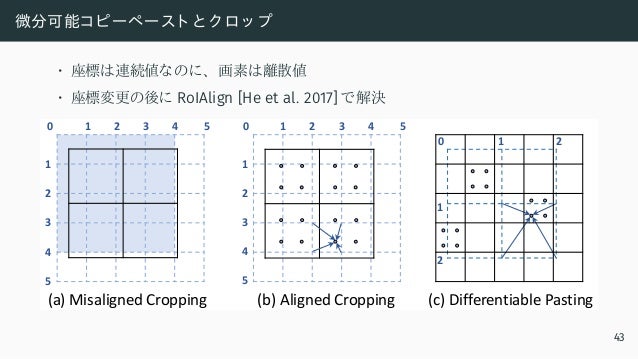
![微分可能コピーペースト と ク ロッ プ
• 座標は連続値なのに、 画素は離散値
• 座標変更の後に RoIAlign [He et al. 2017] で解決
0 1 2 3 4 5
1
2
3
4
5
0 1 2
1
2
(a) Misaligned Cropping (c) Differentiable Pasting
(b) Aligned Cropping
0 1 2 3 4 5
1
2
3
4
5
43](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-89-638.jpg)
![微分化レ ンダーリ ング
• ベク タ ースト ロ ーク から ラ スタ ー画像を 生成
• VGG16 を 使用 [Simonyan and Zisserman 2015]
Neural
Network
Neural
Renderer
Raster
Loss
Input image Stroke parameters Rendered image
44](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-90-638.jpg)
![ラスタ ーの損失関数
• VGG16 を 使用 [Simonyan and Zisserman 2015]
Loss Network (VGG-16)
Rendered
image
Target
image
45](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-91-638.jpg)




![ベク タ ー化の結果
75s 69s 29s (GPU)
Fidelity-vs-Simplicity
[Favreau et al. 2016]
PolyVectorization
[Bessmeltsev et al. 2019] Our results (vector)
Dracolion (1024px)
48](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-96-638.jpg)
![ベク タ ー化の結果
Fidelity-vs-Simplicity
[Favreau et al. 2016]
PolyVectorization
[Bessmeltsev et al. 2019] Our results (vector)
Mouse (1024px)
89s 61s 23s (GPU)
48](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-97-638.jpg)


![ペン入れの結果
PolyVectorization
[Bessmeltsev et al. 2019]
Sketch Simplification (pixel)
[Simo-Serra et al. 2018]
+ PolyVectorization
Our results (vector)
Bird (384px)
50](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-100-638.jpg)
![ペン入れの結果
PolyVectorization
[Bessmeltsev et al. 2019]
Sketch Simplification (pixel)
[Simo-Serra et al. 2018]
+ PolyVectorization
Our results (vector)
Hand (433px)
50](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-101-638.jpg)
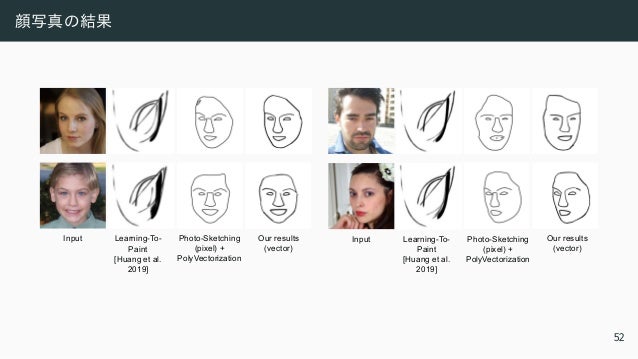
![顔写真の結果
Our results
(vector)
Input Learning-To-
Paint
[Huang et al.
2019]
Photo-Sketching
(pixel) +
PolyVectorization
Our results
(vector)
Input Learning-To-
Paint
[Huang et al.
2019]
Photo-Sketching
(pixel) +
PolyVectorization
52](https://image.slidesharecdn.com/ts32022ssiiess-220607054523-e80be8dc/95/SSII2022-TS3-103-638.jpg)









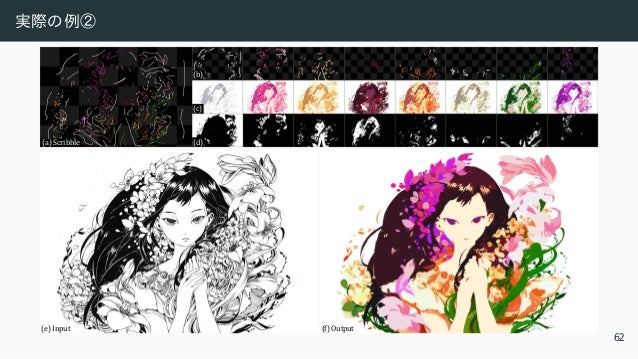




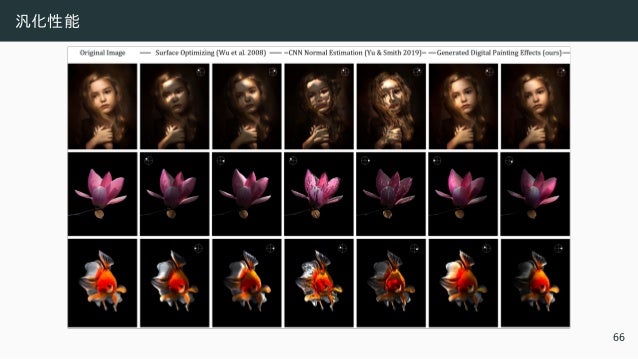






6/10 (金) 09:30~10:40メイン会場 講師:シモセラ エドガー 氏(早稲田大学) 概要: インターネットが現代社会の柱の基本的な構成要素になりつつある現在、大規模なコンテンツ制作がこれまで以上に重要になってきています。しかし、イラストレーションやウェブデザインなどのコンテンツ制作には、高解像度、構造付きデータ、インタラクティブ性など、コンピュータービジョンと機械学習にとって一連のユニークな課題があります。本講演では、機械学習技術を利用して、コンテンツ制作の多様な課題を解決し、クリエイターの能力を向上させる方法について説明します。
![SSII2022 [OS2-01] イメージング最前線](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os2-1-220607020403-b550c379-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-03] スケーラブルなロボット学習システムに向けて](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-03-220607020929-1e2b15e8-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS1-01] AI時代のチームビルディング](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os1-01-220607015404-49188612-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)

![[IBIS2017 講演] ディープラーニングによる画像変換](https://cdn.slidesharecdn.com/ss_thumbnails/ibis2017iizuka-171120134119-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning](https://cdn.slidesharecdn.com/ss_thumbnails/slidev2reduced-190422065109-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2022 [OS3-01] 深層学習のための効率的なデータ収集と活用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-01-220607020740-e80781dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS2] Deepfake Generation and Detection – An Overview (ディープフェイクの生成と検出)](https://cdn.slidesharecdn.com/ss_thumbnails/ss2-01-210607043612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS3] 機械学習のアノテーションにおける データ収集 〜 精度向上のための仕組み・倫理や社会性バイアス 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts3-01-210607043121-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-03] 画像と点群を用いた、森林という広域空間のゾーニングと施業管理](https://cdn.slidesharecdn.com/ss_thumbnails/os3-04-210605062524-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-02] BIM/CIMにおいて安価に点群を取得する目的とその利活用](https://cdn.slidesharecdn.com/ss_thumbnails/os3-03-210605062350-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-01] 設備や環境の高品質計測点群取得と自動モデル化技術](https://cdn.slidesharecdn.com/ss_thumbnails/os3-02-210605062048-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3] 広域環境の3D計測と認識 ~ 人が活動する場のセンシングとモデル化 ~(オーガナイザーによる冒頭の導入)](https://cdn.slidesharecdn.com/ss_thumbnails/os3-01-210605061816-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS1-03] エネルギーの情報化:需要家主体の分散協調型電力マネージメント](https://cdn.slidesharecdn.com/ss_thumbnails/os1-04-210605055326-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS1-02] まち全体のインフラや人流をサステナブルに計測する](https://cdn.slidesharecdn.com/ss_thumbnails/os1-03-210605055213-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS1-01] 水産養殖 x IoT・AI ~持続可能な水産養殖を実現するセンシング/解析技術~](https://cdn.slidesharecdn.com/ss_thumbnails/os1-02-210605054830-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS1] SDGsを実現するセンシング技術 ~ 海と都市とエネルギーを持続させるために ~(オーガナイザーによる冒頭の導入)](https://cdn.slidesharecdn.com/ss_thumbnails/os1-01-210605053952-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2020 [OS2-03] 深層学習における半教師あり学習の最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/ssiisuzukios203-200611050727-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2020 [OS2] 限られたデータからの深層学習 (オーガナイザーによる冒頭の導入)](https://cdn.slidesharecdn.com/ss_thumbnails/ssiiinoueos2-200610074955-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2020 [O3-01] Extreme 3D センシング](https://cdn.slidesharecdn.com/ss_thumbnails/200612-ssii-extreme3dsensing-print3-200608114658-thumbnail.jpg?width=640&height=640&fit=bounds)












