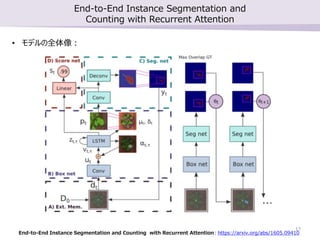
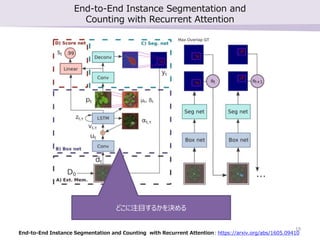
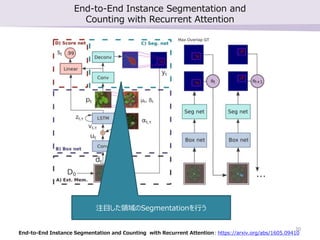
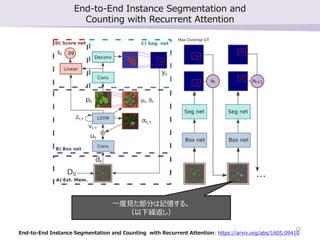
勉強会で最近読んだ論文2本の紹介を行いました。 ・SSD: Single Shot MultiBox Detector ・End-to-End Instance Segmentation and Counting with Recurrent Attention





















![[DL Hacks]Semantic Instance Segmentation with a Discriminative Loss Function](https://cdn.slidesharecdn.com/ss_thumbnails/taniai20180528-180528084124-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)





































![[DL Hacks]OCNet: Object Context Networkfor Scene Parsing](https://cdn.slidesharecdn.com/ss_thumbnails/taniai20181123-181122101559-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)











