論文紹介:Dueling network architectures for deep reinforcement learning
Wang, Ziyu, et al. "Dueling network architectures for deep reinforcement learning." Proceedings of The 33rd International Conference on Machine Learning, PMLR 48:1995-2003, 2016.
紹介論文
Ziyu Wang, TomSchaul, Matteo Hessel, Hado van
Hasselt, Marc Lanctot, Nando de Freitas
“Dueling network architectures for deep
reinforcement learning.”
Proceedings of The 33rd International Conference
on Machine Learning, pp. 1995–2003, 2016
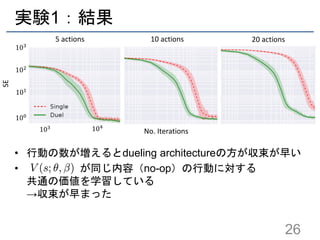
2
























![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Hindsight Experience Replay](https://cdn.slidesharecdn.com/ss_thumbnails/her-180105002310-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl1211-191213002847-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)



