Download as PDF, PPTX
![cvpaper.challenge
Twitter@CVPaperChalleng
http://www.slideshare.net/cvpaperchallenge
MAILTO: cvpaper.challenge[at]gmail[dot]com](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-1-320.jpg)
![cvpaper.challenge
Twitter@CVPaperChalleng
http://www.slideshare.net/cvpaperchallenge
MAILTO: cvpaper.challenge[at]gmail[dot]com](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/75/2016-01-1-3-cvpaper-challenge2016-1-2048.jpg)








![Keywords:Face Recognition, HOG, LBP Local Descriptor, Lerning-based, uunsupervised learning
新規性・差分
手法
結果
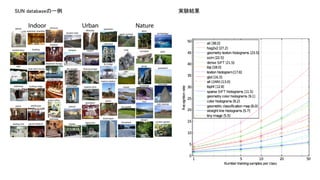
概要
学習ベースで顔認識用のencoderを生成する手法.実験の結
果,HOGなどよりも7[%]程度精度が向上しており,90[%]の精度
を誇っている.
従来手法のHOGやLBPのような人間が設計した特徴量ではな
く,unsupervised学習で特徴量を設計している.
Z Cao, Q Yin, X Tang, J Sun, “Face Recognition with Learning-based Descriptor”, in CVPR,2010.
【9】
Links
論文:
http://research.microsoft.com/en-us/um/people/jiansun/papers/
CVPR10_FaceReco.pdf](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-12-320.jpg)
![Keywords: Pedestrian Detection, Benchmark, Caltech Pedestrian Detection Benchmark
新規性・差分
結果
概要
歩行者検出用のベンチマークとして知られるCaltech
Pedestrian Detection Benchmarkの提案.
手法
データセットの撮影方法に関する項目や,歩行者のオクルージョン度合いな
ど歩行者の統計情報を評価した.学習画像はpositive 67k, negative 61k, テ
スト画像はpositive 65k, negative 56kのデータが収集されており,歩行者検出
データセットの中でも最大である.さらには,映像やオクルージョンラベルも含
まれている.比較にはHaar-like特徴をはじめShapelet, HOG, ChnFtrs,
PoseInv, PLS, HOGLBPなどの特徴量が比較されている.
データセットの説明はもちろん,映像に含まれる歩行者の特性
や手法の違いについても言及.データの収集,アノテーション,
歩行者検出手法の比較まで詳細に行っていることが新規性.
精度の面では[Walk+, CVPR2010]が最も高い精度を実現した.(表)
Piotr Dollar, Christian Wojek, Bernt Schiele, Pietro Perona, “Pedestrian Detection: An Evaluation of the State
of the Art”, in PAMI2012.
【10】
Links
論文 http://vision.ucsd.edu/~pdollar/files/papers/DollarPAMI12peds.pdf
プロジェクト http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-13-320.jpg)



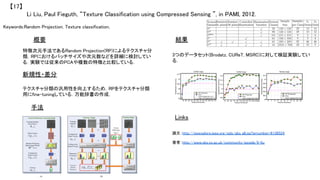
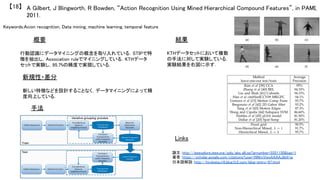
![Keywords:Action Recognition, Dense Trajecotories, HOG, HOF, MBH
新規性・差分
手法
結果 概要
行動認識のための特徴抽出手法の提案.密な軌跡上から複
数の局所特徴量を求めることによって,詳細な特徴抽出を可
能にしている.
従来の動作特徴と異なり,時間的にも空間的にもより密に特
徴を抽出している.
1.画像ピラミッドの生成&5[pixel]間隔で特徴点抽出.この
と特徴点は誤対応を防ぐため閾値判定している.
2.Farneback アルゴリズムによって15[frame]特徴点追跡
3.軌跡上からHOG,HOF,MBH特徴量を算出
H Wang, A Kläser, C Schmid, CL Liu, “Action Recognition by Dense Trajectories”, in CVPR, 2011.
【14】
Links
論文:https://hal.inria.fr/inria-00583818/document
Project:http://lear.inrialpes.fr/people/wang/dense_trajectories](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-17-320.jpg)







![Keywords: Action Recognition, Space-time Neighborhood Features
新規性・差分
手法
結果
概要
従来のbag-of-wordsモデルでは,識別的な特徴を見落としてし
まう可能性があったため,提案手法では隣接する時系列特徴
の形状を学習することで行動カテゴリに最も適した特徴を見つ
けることができる.
提案手法は行動認識の問題に則した形式で特徴量を学習する
ことができる.
Laptevらの提案したHOG/HOF特徴(level-0 feature)を取得し,それらの時系
列近傍をPCA次元圧縮した結果をlevel-1 featureとして記述.
さらに近傍特徴を各スケール・時系列的に階層的に構築し,Multiple Kernel
Learing (MKL)による識別器を生成.χ二乗距離によるカーネルにてSVM識
別器を生成する.level-2 featureは,level-1を各ワードとして見たより上位の
高次特徴を示す.
Level-0は[Laptev+, CVPR2008]の
結果(85.49%)であり,カーネル学習
(84.43%),Level-0, 1, 2の統合によ
る提案手法が最も高い精度
(87.27%)でUCF Sports datasetの
行動識別を実現した.
Adriana Kovashka, Kristen Grauman, “Learning a Hierarchy of Discriminative Space-Time Neighborhood
Features for Human Action Recognition”, in CVPR, 2010.
【25】
Links
論文
http://www.cs.utexas.edu/~grauman/papers/
kovashka_cvpr2010.pdf
プロジェクト
http://vision.cs.utexas.edu/projects/
activity_neighborhood_features/](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-28-320.jpg)




![Keywords: R-CNN, CNN, Selective Search
新規性・差分
手法
結果
概要
Regions with CNN (R-CNN)のオリジナル論文.候補領域抽出
と畳み込みニューラルネットワーク(CNN)の特徴量+SVMにより
分類することで物体検出を行う.
CNNの研究では主に物体識別問題が行われてきた.しかし,
位置まで含めて特徴量を取得することも重要な課題である.R-
CNNでは物体候補領域を抽出し,領域内で識別を実行するこ
とにより位置まで含めた物体検出を実現することができる.
次ページにR-CNNのフローを示す.(1)画像入力 (2) 2000前後の物体候補領
域を抽出する.本論文ではselective search (fast mode)を用いているが,
EdgeBoxes, GOP and LPO, MCG, RIGOR, などに代替可能である.(3) CNN
アーキテクチャの中間層から特徴量を取り出す.ここではCaffe/Decafの実装
であるAlexNetを用い,同Decaf論文[Donahue+, ICML2014]にてもっとも精度
の良かった第6, 7層の特徴量(4096次元)を使用.warped regionとあるが,これ
は一定のサイズ(227x227pixels)にリサイズすることである. (4) SVMにより候
補領域内の画像を評価する.信頼度が高い領域のみを認識結果として出力
する.
また,エラー率を下げるためにDPMでも採用されたbounding-box
regression(bbg)を採用した.bbgでは候補領域Pから正解領域Gへの線形関数
である変換マップdを生成することが目的である.
PASCAL VOC 2007で58.8%, 同2010で53.7%,同 2012にて53.3%の精度を
達成した.DPMでは33.4%(PASCAL VOC 2010)の認識結果であるため,
かなりの精度向上を実現した.処理時間はGPUにて13s/image, CPUにて
53s/imageであった.
Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik, “Rich feature hierarchies for accurate object
detection and semantic segmentation”, in CVPR, 2014.
【29】
Links
論文 http://www.cs.berkeley.edu/~rbg/papers/r-cnn-cvpr.pdf
プロジェクト https://github.com/rbgirshick/rcnn
【物体候補領域】
EdgeBoxes: matlab code
GOP and LPO: python code
MCG: matlab code
RIGOR: matlab code](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-33-320.jpg)

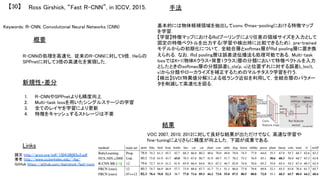
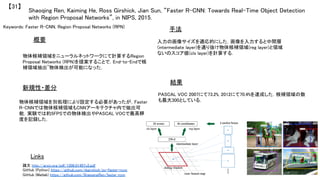
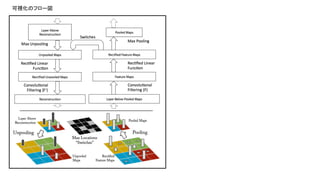
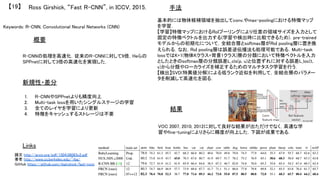
![R-CNNの流れ
R-CNN [CVPR2014]
Selective Search [IJCV2013]やBING [CVPR2014]など物体候補領域抽出 + 227x227pixelsの画像からAlexNetの第
6,7層を取り出し,bounding box regressionにより矩形の当てはめ
R-CNN+ [PAMI2015]
CNN特徴をAlexNetからVGGNetに変更 Pool5が最も精度が高いことが判明
Fast R-CNN [ICCV2015]
Selective Search+CNN特徴という形が基本だが,RoIプーリングにより任意の領域サイズを入力として固定の特徴ベ
クトルを出力.227x227pixelsの畳み込みを避けることで高速化.Multi-task lossやすべての層のパラメータ更新によ
り精度自体も向上.
Faster R-CNN [NIPS2015]
Fast R-CNNにてボトルネックになっていた物体候補領域抽出をRegion Proposal Networks (RPN)に置き換えることで
End-to-Endによる物体検出を実現.最適なRegion Proposal学習のためのLoss Functionも考慮.](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-37-320.jpg)



![Keywords: Visual Turing Test
新規性・差分
手法
結果
概要
画像に対する質問を自動で生成してくれる,Visual Turing Test
の手法を考案.画像の物体認識やその相対的な関係性などを
記述.
CNN+RNNのアプローチにより,従来のVisual Turing Testの精
度を大幅に向上させた.
Recurrent Neural Network (RNN)をベースとしたアプローチを提案する.CNNに
より物体を認識し,それらの相対的な位置関係を記述.RNNでは言語を扱い,質
問文や返答を認識結果から照合するために用いる.モデルは画像xや質問qが
与えられた時の返答aを探索する問題であり,すべてのパラメータθも判断して
返答の集合Aからベストなものを選ぶ.RNNのモデルには
[Donahue+, CVPR2015]を,CNNにはGoogLeNetを用いる.
指標としては,[Malinowski+, NIPS2014]に記載されているWUP (Wu-
Palme) scoresを参考にした.DAQUAR dataset (12,468の質問とそれに対
する返答文を含む)をもちいる.識別対象の物体数は37である.精度は
19.43%,WUPSスコアで25.28(0.9),62.00(0.0)であった.
Mateusz Malinowski, Marcus Rohrbach, Mario Fritz, “Ask Your Neurons: A Neural-based Approach to
Answering Questions about Images”, in ICCV, 2015.
【34】
Links
論文
https://www.d2.mpi-inf.mpg.de/sites/default/files/
iccv15-neural_qa.pdf
プロジェクト
https://www.mpi-inf.mpg.de/departments/computer-
vision-and-multimodal-computing/research/vision-and-
language/visual-turing-challenge/
YouTube
https://www.youtube.com/watch?v=QZEwDcN8ehs
# WUP (Wu-Palme) scoresは言語の精度を示す指標であ
り,スコアが高いほど曖昧度が低く精度が高い.](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-41-320.jpg)
![Keywords: Pedestrian Detection, Deep Learning, Convolutional Neural Networks (CNN), Cascade
新規性・差分
手法
結果
概要
CNNとの特徴量とカスケード識別器による歩行者検出の論文.
Caltech pedestrian benchmarkやKITTI datasetに対して歩行者
検出の実験を行い,良好な精度を達成.
Complexity-awareなブースティング手法を提案し,カスケード識
別を実現したことや,プーリングの仕組みにより効果的にCNN
特徴やHand-craftedな特徴を統合した.
有効なブースティングの手法であるComplexity-Aware Cascade
Training (CompACT)を提案.学習ではAdaBoostの出力F の(empirical)
リスク関数RE[F] や(complexity)リスク関数Rc[F] から構成されるL[F] =
RE[F]+ηRc[F]をLagrangianにより最適化する.ACF特徴を前処理として
用い,特徴量のプーリングにはSelf-similarity (SS) feature,
Checkerboard feature, HOG, CNNを用いる.
図のように,Caltech
datasetに対してエラー率が
11.7%と最高性能を達成し
た.CompactはACF + small
CNN featureを用い,
Compact-Deepは深層学習
にVGG modelも追加した.
Zhaowei Cai, Mohammad Saberian, Nuno Vasconcelos, “Learning Complexity-Aware Cascades for Deep
Pedestrian Detection”, in ICCV, 2015. (oral)
【35】
Links
論文 http://arxiv.org/abs/1507.05348v1
著者(Z.Cai) https://sites.google.com/site/zhaoweicai1989/
歩行者検出主要特徴
ACF
SS
Filter Channel Feat.
katamari
Spatial pooling+](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-42-320.jpg)
![Shenfeng He, Rynson W. H. Lau, “Oriented Object Proposals”, in ICCV, 2015.
【36】
Keywords: Object Proposal, Objectness
新規性・差分
手法
結果
概要
傾き(Orientation)を含めて物体の候補領域を推定する手法
Oriented Object Proposals (OOPs)を提案.
・傾きが発生した場合にも補正することが可能
・修正されたウィンドウで候補領域を得ることができる
・余分な背景を取得することが低減し,高いRecallを実現できる
全てのウインドウ探索を避けるために異なるポジションに配置された物体から,ス
ケールやアスペクト比計算を同時に処理する方法を考案.生成的確率モデルの構
築によりピクセルごとの計算まで可能にした.またそのために背景確率まで計算す
る.そのためには,Gradient MapやStructured Edges [Dollar+, ICCV2013]を適用す
る.対数尤度により局所最適解を計算し,物体形状は共分散行列により表現され
る.最終的な物体の尤度(l)は下記の式により決定し,背景 (l^{bg}),Structured
Edges (l^{e}),Gradient Map (l^{g})から総合的に判断される.a1, a2, a3はデータか
ら線形回帰により決定づけられる.
PASCAL VOC 2007で実験したところ,最先端の精度で物体を検出することができ
た.さらには,高いRecall rateを実現し,余分な物体候補領域を削減することに成
功した. Links
論文
http://www.shengfenghe.com/uploads/1/5/1/3/15132160/
oop_iccv15.pdf
プロジェクト
http://www.shengfenghe.com/oriented-object-proposals.html
YouTube https://www.youtube.com/watch?v=_iS9qoYWKpk
図は精度の比較である.左図はIoU (バ
ウンディングボックスの重なり)が50%,
右図は80%の時の精度である.正規の
手法で比較すると必ずしも最先端では
ないが,物体検出で計測するとかなり
高い精度で検出が可能.](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-43-320.jpg)








![Tomas Mikolov, Kai Chen, Greg Carrado, Jeffrey Dean, “Efficient Estimation of Word Representations in
Vector Space”, ICLR, 2013.
【42】
Keywords: Word2Vec
新規性・差分
手法
結果
概要
Word2Vecの論文.単語の概念間の計算を行うために,大規模
なテキストデータからその統計値を計算した.
単語間の意味的な関係性を記述・計算できるようにした画期的
な手法.単語の分散表現を学習する手法にはNNLMがあるが,
これはニューラルネット言語モデルであり,フィードフォワード
NNを線形射影層と非線形隠れ層とを組み合わせ,単語ベクト
ル表現と統計的言語モデルを同時に学習する.
例えば,vector(“King”) – vector(“Man”) + vector(“Woman”) = vector(“Queen”)な
ど,概念間の計算を効率的にやりとりできるようにした.ニューラルネットを用いて
いるが,DistBelief[Dean+, NIPS2012]により学習した.
・単語の表現としてはContinuous Bag-of-Words (CBOW)を採用した.これは,現在
の単語の周辺の単語を用いて現在の単語を予測する表現である.普通のBOWと
は異なり,分散表現を用いることが可能.
・Continuous Skip-gramモデルでは文脈から現在の単語を予測するのでなく現在
の単語から周辺の単語を予測する.文脈長を広げると単語ベクトルの質はよくなる
が,計算量が大きくなるし,離れれば離れるほど現在の単語と無関係になるので,
距離に応じてダウンサンプリングする.
6億を超える単語数を保持するGoogleNewsからモデリングを行った.下の表は783
万単語から学習された300次元Skip-gramの出力である.
Links
論文 http://arxiv.org/pdf/1301.3781.pdf
プロジェクト(コードあり) https://code.google.com/p/word2vec/
SlideShare
http://www.slideshare.net/mamoruk/iclr2013-word2vec](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-52-320.jpg)

![Keywords: R-CNN, Deep Learning, Convolutional Neural Networks (CNN), Object Detection
新規性・差分
手法
結果
概要
CNNの構造の中で物体検出できる仕組みを実装した.
R-CNNはselective searchにより物体候補領域を抽出し,CNN
により識別する手法であるが,CNNの構造内で検出までできる
かもしれないという主張.Spatil Pyramid Pooling (SPP)[1]や
selective searchによる物体検出の解析と検討をしている.
まず,SVMは冗長でありCNNの構造内で識別まで全て完結することができる
ということを検討.
次にSPPとbounding box regressionをbank of filterの枠組みの中で統合.ス
ケーリングについても考察し,単一スケールでも処理速度を保てるようにし
た.
表に結果を示す.各項目について有効性を確認しただけでなく,処理速
度も1フレーム160msであり,従来の16倍以上(2.5s)高速にした.
Karel Lenc, Andrea Vedaldi, “R-CNN minus R”, in BMVC, 2015.
【44】
Links
論文 http://www.robots.ox.ac.uk/~vedaldi/assets/pubs/lenc15rcnn.pdf
著者 (Andrea Vedaldi) http://www.robots.ox.ac.uk/~vedaldi/index.html
コードMatConvNet: CNN for MATLAB http://www.vlfeat.org/matconvnet/
[1]
K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional
networks for visual recognition. In ECCV, 2014.](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-54-320.jpg)
![Keywords: Convolutional Neural Networks (CNN), Deblurring, Blind Decovolution
新規性・差分
手法
結果
概要
Convolutional Neural Networks (CNN)を用いた,blind
deconvolutionに関する研究.文字OCRのための文字認識に着
目した.
Schulerら[27]の手法が比較として挙げられるが,CNNのネット
ワークが小規模であり,画像の復元もスタンダードなデブラー
の手法である.
x = F(y, θ)のθを求めるためにに(x,y)のペアを学習する.文字
は非常に強い事前情報を保持しており,学習ベースの復元は
有効である.本稿で用いられるCNNの構造は15層である.フィ
ルターやチャネル数は表の通り.
下は実際にCNNを用いてデブラーをした結果である.OCRを用いて処理した
結果,通常通り文字認識ができることを実証した.
Michal Hradis, Jan Kotera, Pavel Zemcik, Filip Sroubek, “Convolutional Neural Networks for Direct Text
Deblurring”, in BMVC, 2015.
【45】
Links
論文 http://bmvc2015.swansea.ac.uk/proceedings/papers/paper006/paper006.pdf
概要
http://bmvc2015.swansea.ac.uk/proceedings/papers/paper006/abstract006.pdf
プロジェクト http://www.fit.vutbr.cz/~zemcik/pubs.php?id=10922](https://image.slidesharecdn.com/2016011deepsurvey2016-160307022730/85/2016-01-1-3-cvpaper-challenge2016-55-320.jpg)


cvpaper.challengeにて2016年1月までにサーベイした論文のまとめ(1/3)です. Computer Visionの"今"をまとめています. cvpaper.challenge2016は産総研,東京電機大,筑波大学,東京大学,慶應義塾大学のメンバー約30名で構成されています. 2015年はCVPR2015の全602論文を読破し,PRMUにて論文調査からアイディア考案,論文化までをカバーする「DeepSurvey」を提案しました. 2016年は「1000本超の読破」と「コンピュータビジョンの上位会議への投稿」を目標に活動しております. Twitterで論文情報を随時アップしてます. Twitter: https://twitter.com/CVpaperChalleng 質問コメント等がありましたらメールまで. Mail : cvpaper.challenge@gmail.com



































































