Recommended
PPTX
PDF
Deep Forest: Towards An Alternative to Deep Neural Networks
PDF
PPTX
Globally and Locally Consistent Image Completion
PPTX
PPTX
PDF
Generating Videos with Scene Dynamics
PPTX
PDF
PDF
Deeply-Recursive Convolutional Network for Image Super-Resolution
PDF
【2016.05】cvpaper.challenge2016
PDF
PPTX
PPTX
PPTX
PPTX
Colorful image colorization
PPTX
Densely Connected Convolutional Networks
PPTX
PPTX
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network
PDF
【2016.02】cvpaper.challenge2016
PDF
【2016.01】(2/3)cvpaper.challenge2016
PDF
【2016.01】(3/3)cvpaper.challenge2016
PDF
【2016.03】cvpaper.challenge2016
PDF
【2016.04】cvpaper.challenge2016
PPTX
A simple neural network mnodule for relation reasoning
PDF
【2016.01】(1/3)cvpaper.challenge2016
PPTX
PDF
[Dl輪読会]introduction of reinforcement learning
PDF
NIPS KANSAI Reading Group #7: Temporal Difference Models: Model-Free Deep RL ...
PPTX
More Related Content
PPTX
PDF
Deep Forest: Towards An Alternative to Deep Neural Networks
PDF
PPTX
Globally and Locally Consistent Image Completion
PPTX
PPTX
PDF
Generating Videos with Scene Dynamics
PPTX
Viewers also liked
PDF
PDF
Deeply-Recursive Convolutional Network for Image Super-Resolution
PDF
【2016.05】cvpaper.challenge2016
PDF
PPTX
PPTX
PPTX
PPTX
Colorful image colorization
PPTX
Densely Connected Convolutional Networks
PPTX
PPTX
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network
PDF
【2016.02】cvpaper.challenge2016
PDF
【2016.01】(2/3)cvpaper.challenge2016
PDF
【2016.01】(3/3)cvpaper.challenge2016
PDF
【2016.03】cvpaper.challenge2016
PDF
【2016.04】cvpaper.challenge2016
PPTX
A simple neural network mnodule for relation reasoning
PDF
【2016.01】(1/3)cvpaper.challenge2016
Similar to DeepLoco
PPTX
PDF
[Dl輪読会]introduction of reinforcement learning
PDF
NIPS KANSAI Reading Group #7: Temporal Difference Models: Model-Free Deep RL ...
PPTX
PDF
Learning to Navigate in Complex Environments 輪読
PDF
Tech-Circle #18 Pythonではじめる強化学習 OpenAI Gym 体験ハンズオン
PPTX
[DL輪読会]Learning agile and dynamic motor skills for legged robots
PDF
PPTX
PPTX
Efficient Deep Reinforcement Learning with Imitative Expert Priors for Autono...
PDF
PDF
論文紹介:”Playing hard exploration games by watching YouTube“
PDF
NIPS KANSAI Reading Group #7: 逆強化学習の行動解析への応用
PDF
【論文紹介】Deep Mimic: Example-Guided Deep Reinforcement Learning of Physics-Based...
PDF
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
PPTX
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
PDF
PDF
Computational Motor Control: Reinforcement Learning (JAIST summer course)
More from harmonylab
PDF
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Lea...
PDF
APT-LLM Embedding-Based Anomaly Detection of Cyber Advanced Persistent Threat...
PDF
QuASAR: A Question-Driven Structure-Aware Approach for Table-to-Text Generation
PDF
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
PDF
CTINexus: Automatic Cyber Threat Intelligence Knowledge Graph Construction Us...
PDF
Can Large Language Models perform Relation-based Argument Mining?
PDF
AECR: Automatic attack technique intelligence extraction based on fine-tuned ...
PDF
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
PDF
Towards Scalable Human-aligned Benchmark for Text-guided Image Editing
PDF
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models throu...
PDF
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
PDF
Efficient anomaly detection in tabular cybersecurity data using large languag...
PDF
Encoding and Controlling Global Semantics for Long-form Video Question Answering
PDF
Data Scaling Laws for End-to-End Autonomous Driving
PDF
Multiple Object Tracking as ID Prediction
PDF
Mixture-of-Personas Language Models for Population Simulation
PDF
TransitReID: Transit OD Data Collection with Occlusion-Resistant Dynamic Pass...
PDF
Mixture-of-Personas Language Models for Population Simulation
PDF
Collaborative Document Simplification Using Multi-Agent Systems
PDF
【卒業論文】LLMを用いたMulti-Agent-Debateにおける反論の効果に関する研究
DeepLoco 1. DeepLoco : Dynamic Locomotion
Skills Using Hierarchical Deep
Reinforcement Learning
北海道大学 工学部
調和系工学研究室
学部四年 吉田拓海
2017年7月7日
2. 論文紹介
• DeepLoco : Dynamic Locomotion Skills Using Hierarchical Deep
Reinforcement Learning
– Transactions on Graphics (Proc. ACM SIGGRAPH 2017)
– XUE BIN PENG and GLEN BERSETH,University of British Columbia
– KANGKANG YIN,National University of Singapore
– MICHIEL VAN DE PANNE,University of British Columbia
• URL:http://www.cs.ubc.ca/~van/papers/2017-TOG-deepLoco/
• 概要
• エージェントに歩行技術を学習させた
• 結果は3D二足歩行シミュレーションで実証される
• 2レベルの階層的制御フレームワークを採用
• コントローラはどちらもdeep reinforcement learning で学習される
1
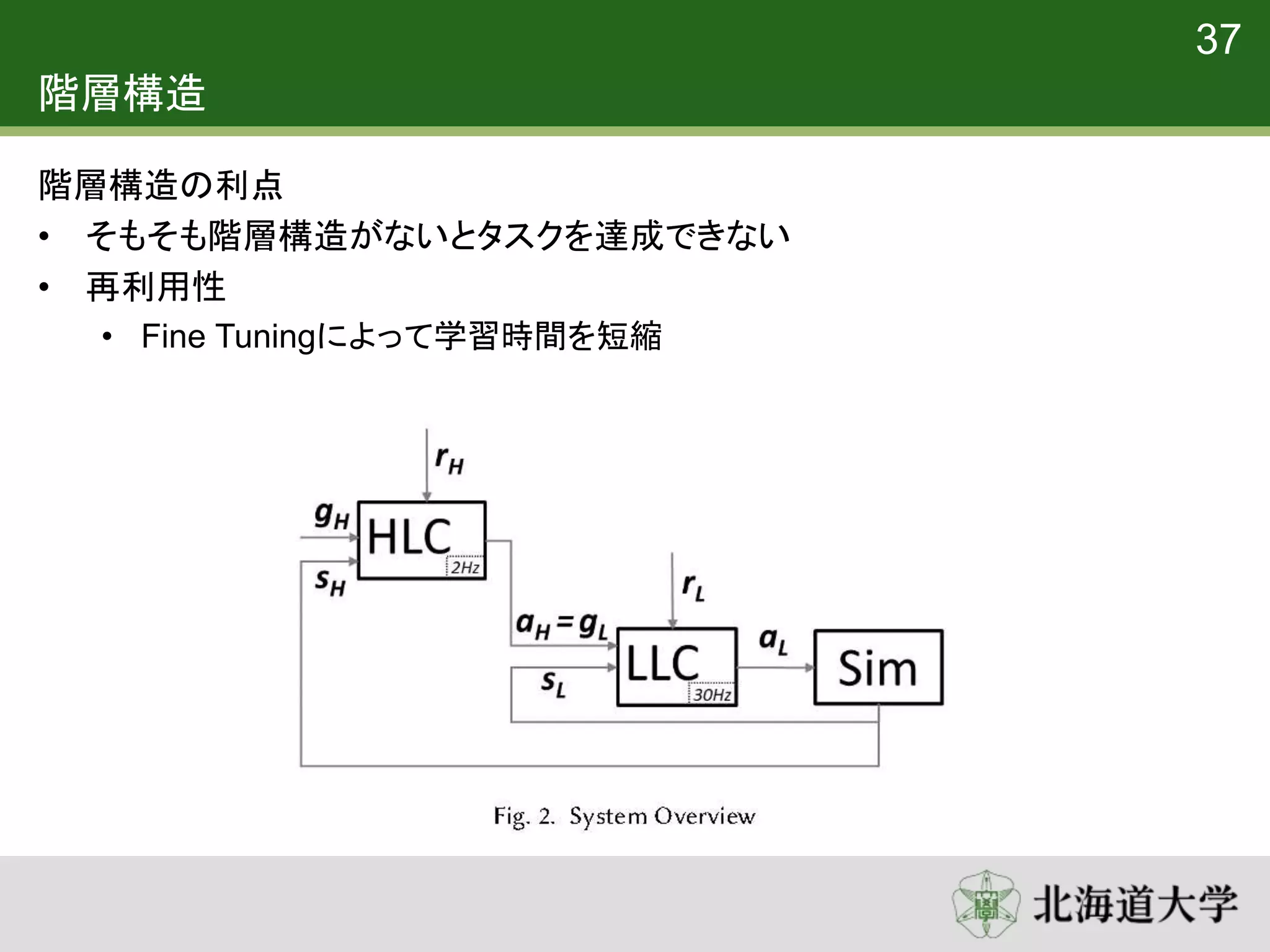
3. 4. システムの概要
3
HLC(High-level controller)
– 𝑠 𝐻:状態
– 𝑔 𝐻: 目標
– 𝑟 𝐻: 報酬
– 𝑎 𝐻: 行動
LLC(Low-level controller)
– 𝑠 𝐿: 状態
– 𝑔 𝐿: 目標
– 𝑟𝐿: 報酬
– 𝑎 𝐿: 行動
• HLCが高レベル目標𝑔 𝐻を処理し、LLCに低レベル目標𝑔 𝐿を提供する
• LLCからの行動𝑎 𝐿はシミュレーションに適用され、状態𝑠 𝐻, 𝑠 𝐿が更新される
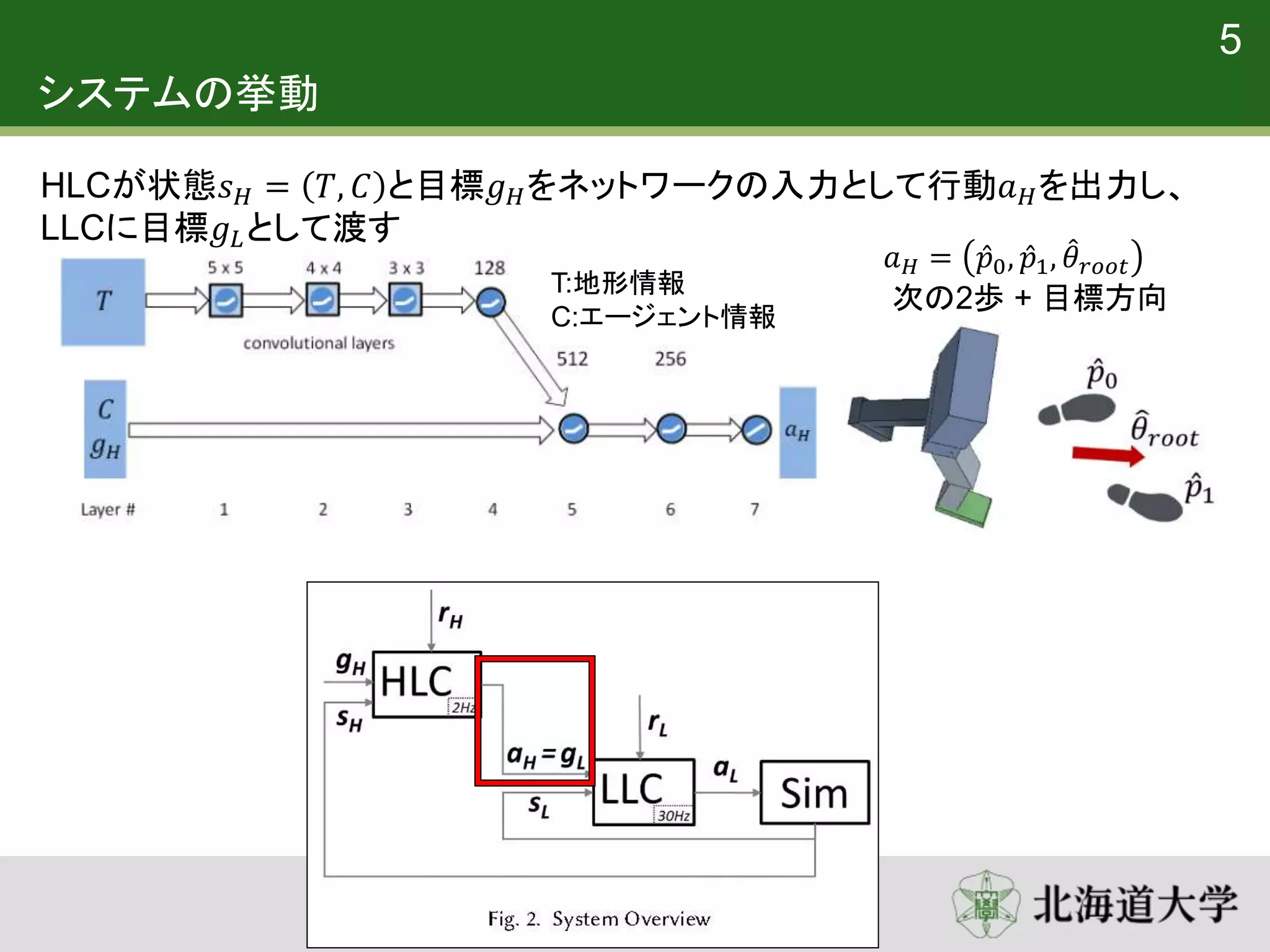
5. 6. システムの挙動
5
HLCが状態𝑠 𝐻 = 𝑇, 𝐶 と目標𝑔 𝐻をネットワークの入力として行動𝑎 𝐻を出力し、
LLCに目標𝑔 𝐿として渡す
𝑎 𝐻 = 𝑝0, 𝑝1, 𝜃 𝑟𝑜𝑜𝑡
次の2歩 + 目標方向
T:地形情報
C:エージェント情報
7. 8. 9. 10. 11. 12. 強化学習 (Reinforcement Learning)
• 環境から得られる最終的な累積報酬を最大化することで学習を行う
• 累積報酬 : 𝑘=0 𝛾 𝑘
𝑟𝑡+𝑘+1
• 𝛾 : 割引率 (遠い将来に得られる報酬ほど割り引いて評価する)
• Actor-Critic 法によって累積報酬を最大化する方策を学習
• 方策 𝜋 𝑠, 𝑔 = 𝑎
• 状態𝑠, 目標𝑔の時には行動𝑎をとる
• 行動を選択する”actor”
• 価値関数 𝑉(𝑠, 𝑔)
• ある方策𝜋をとる、状態𝑠, 目標𝑔の時の累積報酬
• actorによって選択された行動を批判”critic”
• 更新式
• 𝑉 𝑠𝑡, 𝑔𝑡 ← 𝑉 𝑠𝑡, 𝑔𝑡 + 𝛼[𝑟𝑡+1 + 𝛾𝑉 𝑠𝑡+1, 𝑔𝑡+1 − 𝑉 𝑠𝑡, 𝑔𝑡 ]
11
13. 強化学習 (Reinforcement Learning)
• 価値関数 𝑉(𝑠, 𝑔)
• ある方策𝜋をとる、状態𝑠, 目標𝑔の時の累積報酬
• actorによって選択された行動を批判”critic”
• 更新式
• 𝑉 𝑠𝑡, 𝑔𝑡 ← 𝑉 𝑠𝑡, 𝑔𝑡 + 𝛼[𝑟𝑡+1 + 𝛾𝑉 𝑠𝑡+1, 𝑔𝑡+1 − 𝑉 𝑠𝑡, 𝑔𝑡 ]
12
𝑉𝑡
𝑉𝑡+1
𝛾𝑉𝑡+1
報酬
𝑟𝑡
TD誤差
TD誤差
状態𝑠𝑡 状態𝑠𝑡+1
TD誤差 > 0
• 行った行動は価値を高めた
• その行動がより選択されるようにする
14. 学習
13
• 行動 𝑎 = 𝜇 𝑠, 𝑔|𝜃𝜇 (= 方策𝜋 𝑠, 𝑔 )
• パラメータ𝜃𝜇のニューラルネットワークの出力
• 状態𝑠, 目標𝑔が与えられた時の最適な行動となるように学習
• 価値関数𝑉 𝑠, 𝑔 𝜃𝑣
• パラメータ𝜃𝑣のニューラルネットワークの出力
• 状態𝑠, 目標𝑔が与えられた時の累積報酬となるように学習
• 行動(方策)の最適化に利用
λ=0:決定論的(実行時)
λ=1:確率論的(学習時)
探査ノイズ𝑁を加えることにより行動探索の幅が広がる
𝑎 = 𝜇 𝑠, 𝑔 + 𝜆𝑁, 𝑁~𝐺(0, Σ)
𝜆~Ber 𝜖 : ε-greedy法
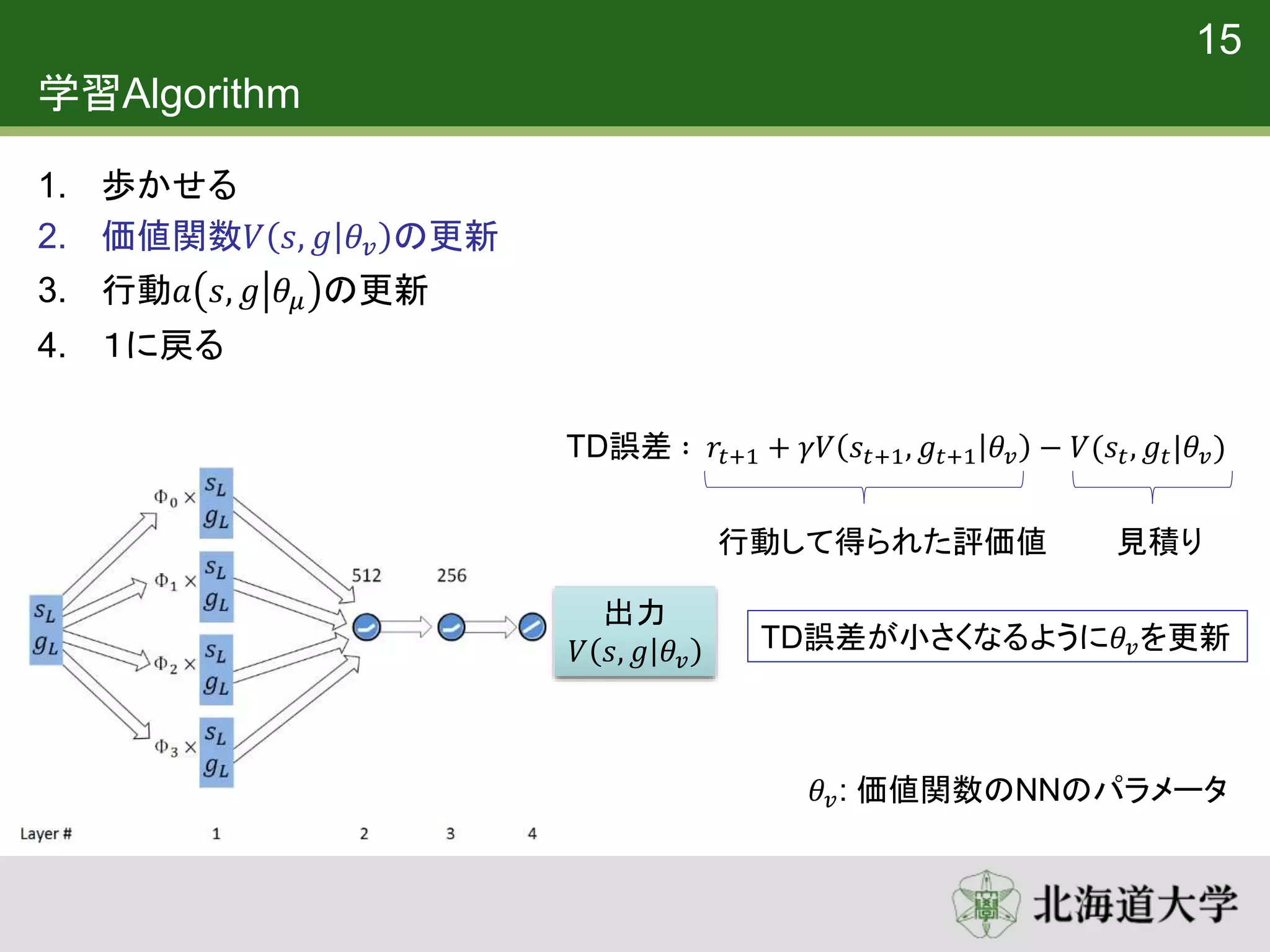
15. 16. 学習Algorithm
1. 歩かせる
2. 価値関数𝑉 𝑠, 𝑔 𝜃𝑣 の更新
3. 行動𝑎 𝑠, 𝑔 𝜃𝜇 の更新
4. 1に戻る
15
出力
𝑉 𝑠, 𝑔 𝜃𝑣
見積り
TD誤差 ∶ 𝑟𝑡+1 + 𝛾𝑉 𝑠𝑡+1, 𝑔𝑡+1 𝜃𝑣 − 𝑉(𝑠𝑡, 𝑔𝑡|𝜃𝑣)
行動して得られた評価値
TD誤差が小さくなるように𝜃𝑣を更新
𝜃𝑣: 価値関数のNNのパラメータ
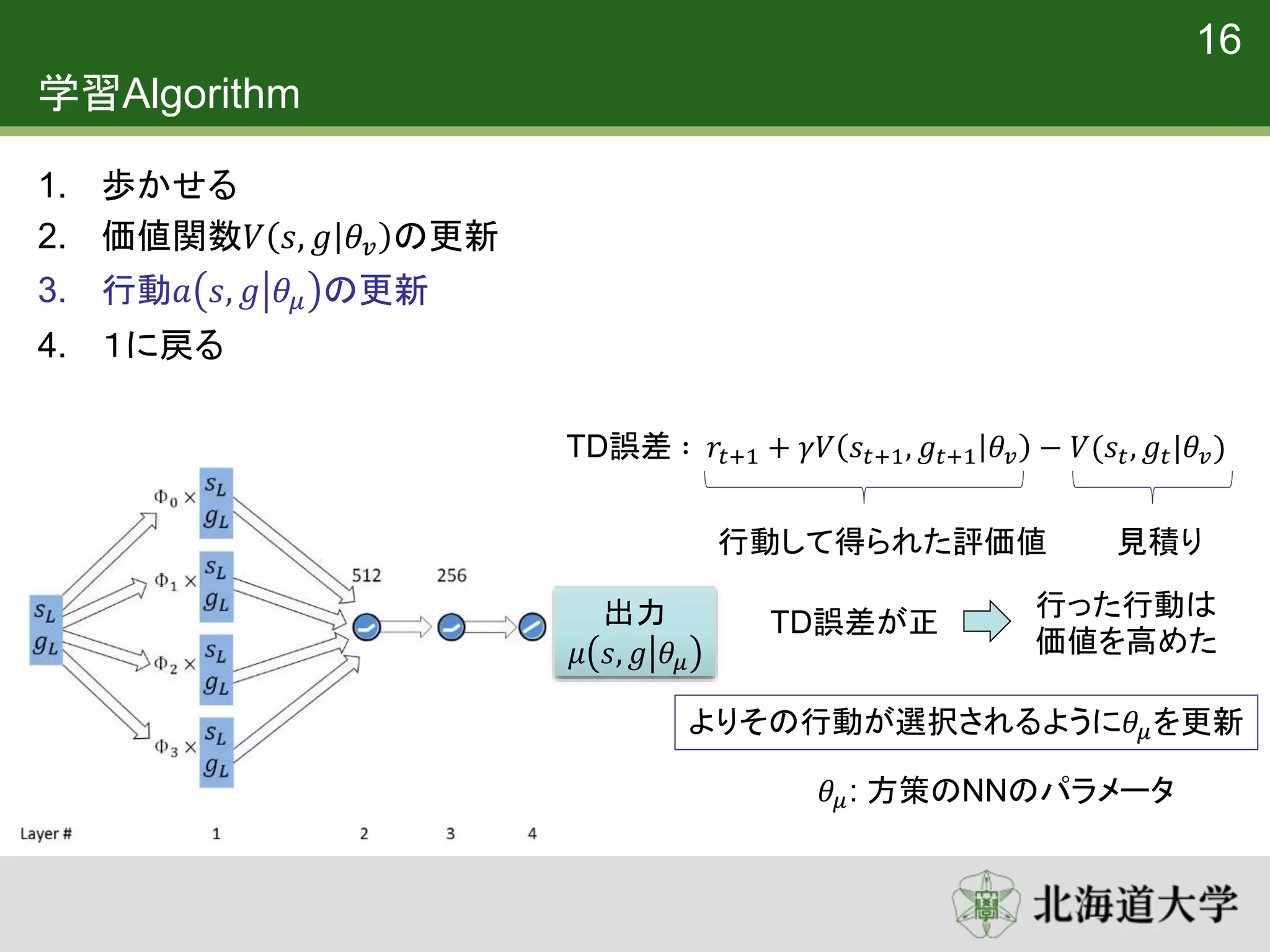
17. 学習Algorithm
1. 歩かせる
2. 価値関数𝑉 𝑠, 𝑔 𝜃𝑣 の更新
3. 行動𝑎 𝑠, 𝑔 𝜃𝜇 の更新
4. 1に戻る
16
出力
𝜇 𝑠, 𝑔 𝜃𝜇
見積り
TD誤差 ∶ 𝑟𝑡+1 + 𝛾𝑉 𝑠𝑡+1, 𝑔𝑡+1 𝜃𝑣 − 𝑉(𝑠𝑡, 𝑔𝑡|𝜃𝑣)
行動して得られた評価値
TD誤差が正
行った行動は
価値を高めた
よりその行動が選択されるように𝜃𝜇を更新
𝜃𝜇: 方策のNNのパラメータ
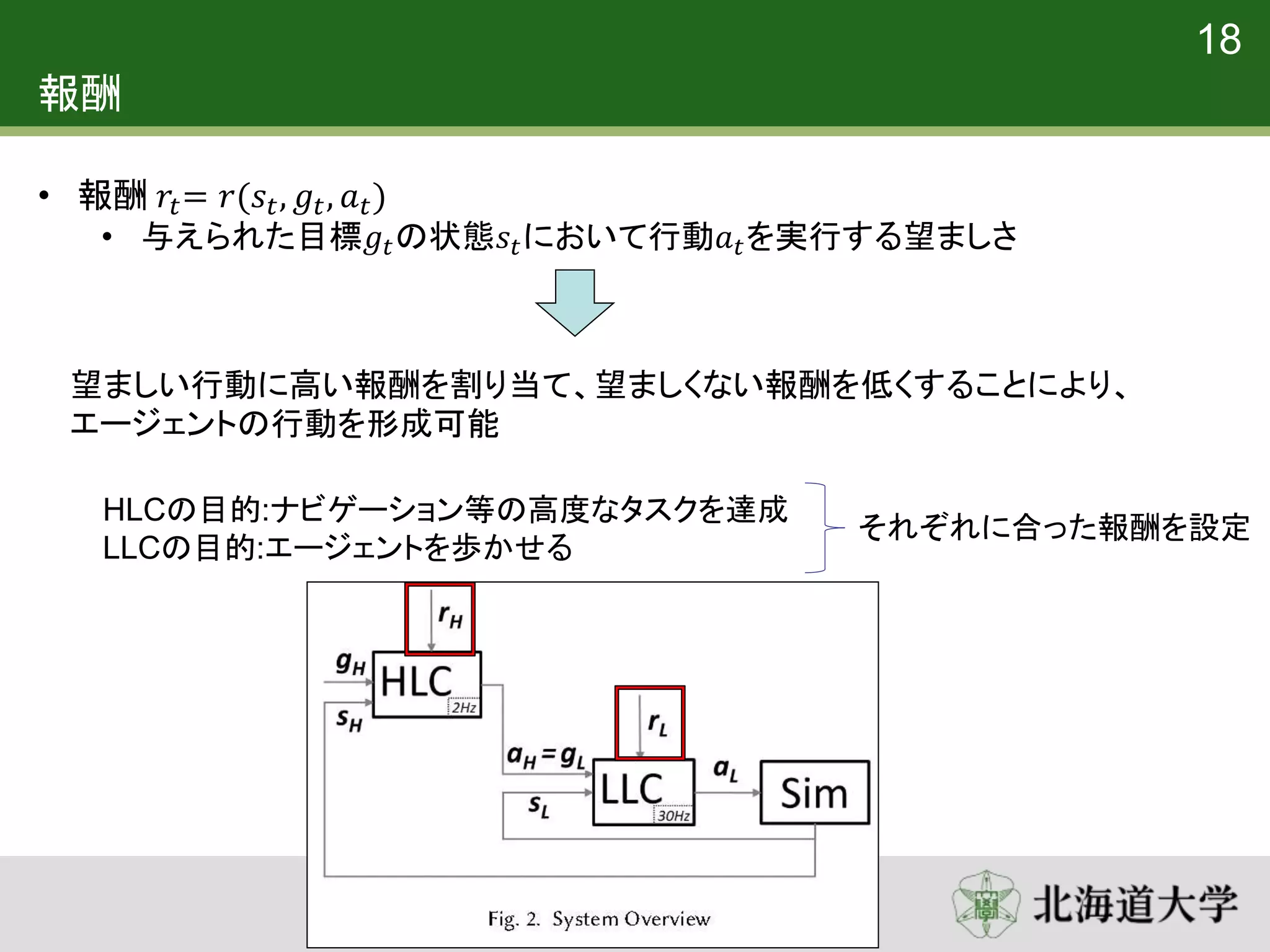
18. 19. 報酬
18
• 報酬 𝑟𝑡= 𝑟(𝑠𝑡, 𝑔𝑡, 𝑎 𝑡)
• 与えられた目標𝑔𝑡の状態𝑠𝑡において行動𝑎 𝑡を実行する望ましさ
望ましい行動に高い報酬を割り当て、望ましくない報酬を低くすることにより、
エージェントの行動を形成可能
HLCの目的:ナビゲーション等の高度なタスクを達成
LLCの目的:エージェントを歩かせる
それぞれに合った報酬を設定
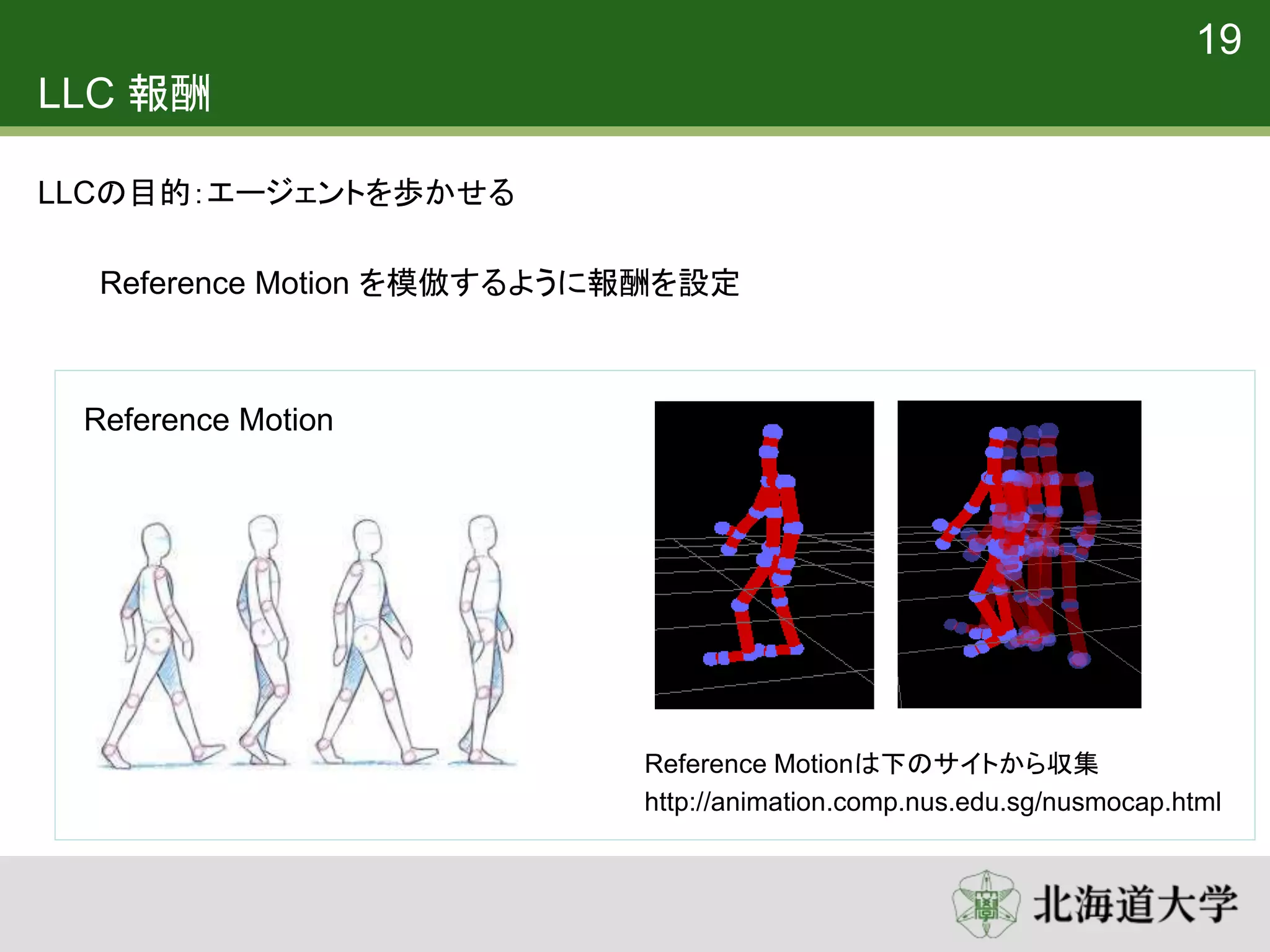
20. 21. LLC 報酬
Reference Motion の状態と近いほど報酬が高くなるように設定
20
𝑟𝐿 = 𝑤 𝑝𝑜𝑠𝑒 𝑟𝑝𝑜𝑠𝑒 + 𝑤 𝑣𝑒𝑙 𝑟𝑣𝑒𝑙 + 𝑤 𝑟𝑜𝑜𝑡 𝑟𝑟𝑜𝑜𝑡 + 𝑤𝑐𝑜𝑚 𝑟𝑐𝑜𝑚 + 𝑤 𝑒𝑛𝑑 𝑟𝑒𝑛𝑑 + 𝑤ℎ𝑒𝑎𝑑𝑖𝑛𝑔 𝑟ℎ𝑒𝑎𝑑𝑖𝑛𝑔
22. LLC 報酬
Reference Motion の状態と近いほど報酬が高くなるように設定
21
𝑟𝐿 = 𝑤 𝑝𝑜𝑠𝑒 𝑟𝑝𝑜𝑠𝑒 + 𝑤 𝑣𝑒𝑙 𝑟𝑣𝑒𝑙 + 𝑤 𝑟𝑜𝑜𝑡 𝑟𝑟𝑜𝑜𝑡 + 𝑤𝑐𝑜𝑚 𝑟𝑐𝑜𝑚 + 𝑤 𝑒𝑛𝑑 𝑟𝑒𝑛𝑑 + 𝑤ℎ𝑒𝑎𝑑𝑖𝑛𝑔 𝑟ℎ𝑒𝑎𝑑𝑖𝑛𝑔
• Reference Motionを模倣するように設定された項
• 𝑟𝑝𝑜𝑠𝑒, 𝑟𝑣𝑒𝑙 : 関節の動きについて
• 𝑟𝑟𝑜𝑜𝑡 : 骨盤の高さについて
• 𝑟𝑐𝑜𝑚 : 重心の速度について
23. LLC 報酬
Reference Motion の状態と近いほど報酬が高くなるように設定
22
𝑟𝐿 = 𝑤 𝑝𝑜𝑠𝑒 𝑟𝑝𝑜𝑠𝑒 + 𝑤 𝑣𝑒𝑙 𝑟𝑣𝑒𝑙 + 𝑤 𝑟𝑜𝑜𝑡 𝑟𝑟𝑜𝑜𝑡 + 𝑤𝑐𝑜𝑚 𝑟𝑐𝑜𝑚 + 𝑤 𝑒𝑛𝑑 𝑟𝑒𝑛𝑑 + 𝑤ℎ𝑒𝑎𝑑𝑖𝑛𝑔 𝑟ℎ𝑒𝑎𝑑𝑖𝑛𝑔
• 歩行計画𝑔 𝐿に従うように設計された項
• 𝑟𝑒𝑛𝑑 : 脚の位置について
• 𝑟ℎ𝑒𝑎𝑑𝑖𝑛𝑔 : 進行方向について
𝑔 𝐿 = 𝑝0, 𝑝1, 𝜃 𝑟𝑜𝑜𝑡
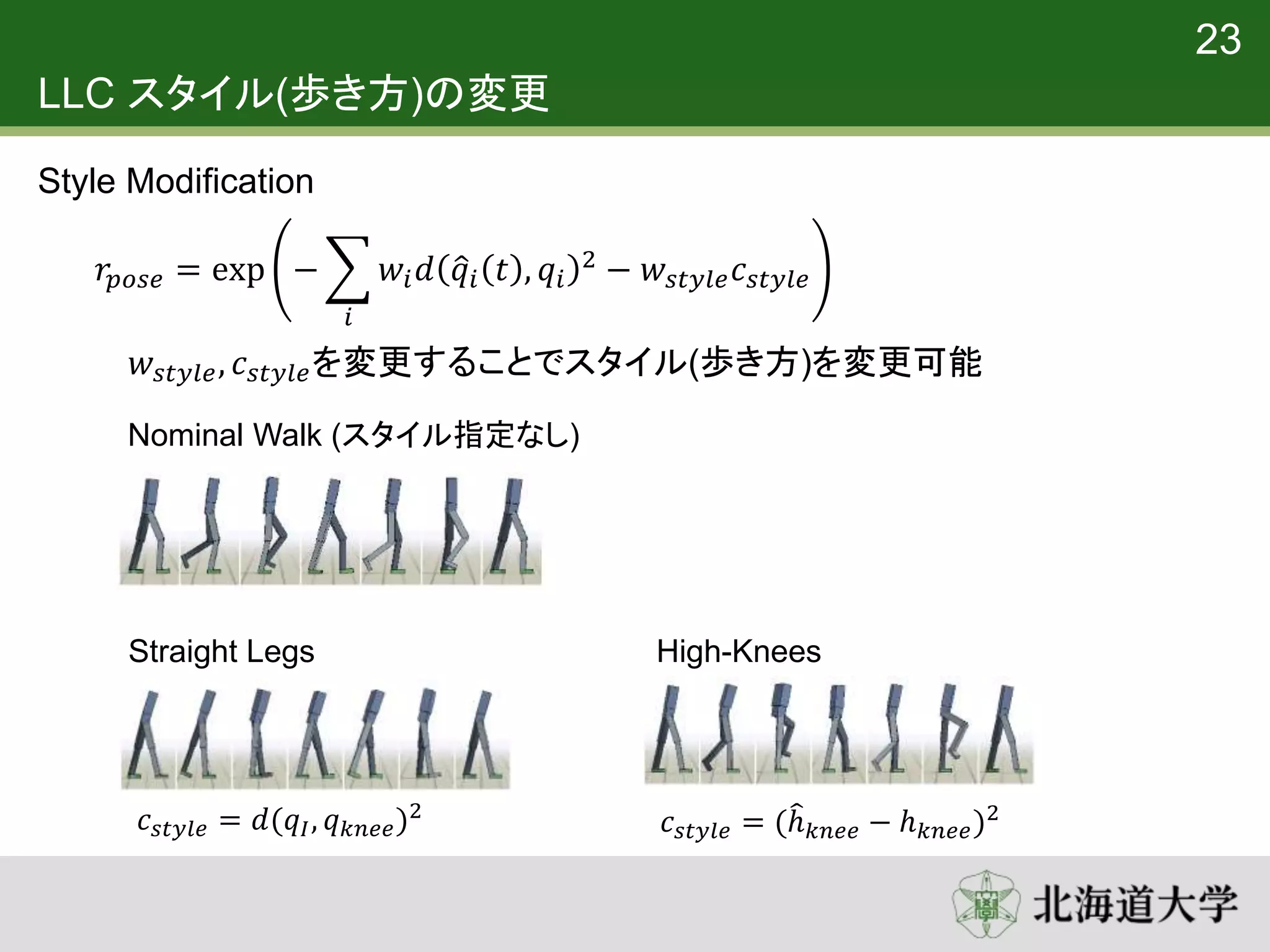
24. LLC スタイル(歩き方)の変更
𝑤𝑠𝑡𝑦𝑙𝑒, 𝑐 𝑠𝑡𝑦𝑙𝑒を変更することでスタイル(歩き方)を変更可能
Straight Legs High-Knees
23
Style Modification
𝑟𝑝𝑜𝑠𝑒 = exp −
𝑖
𝑤𝑖 𝑑 𝑞𝑖 𝑡 , 𝑞𝑖
2 − 𝑤𝑠𝑡𝑦𝑙𝑒 𝑐 𝑠𝑡𝑦𝑙𝑒
Nominal Walk (スタイル指定なし)
𝑐 𝑠𝑡𝑦𝑙𝑒 = 𝑑(𝑞𝐼, 𝑞 𝑘𝑛𝑒𝑒)2
𝑐 𝑠𝑡𝑦𝑙𝑒 = (ℎ 𝑘𝑛𝑒𝑒 − ℎ 𝑘𝑛𝑒𝑒)2
25. 26. 27. 28. HLC
• Soccer Dribble
ボールを目標位置までドリブルして移動させるように訓練
ボール:半径0.2m , 質量0.1kg
27
目標𝑔 𝐻
𝑔 𝐻 = (𝜃𝑡𝑎𝑟, 𝑑 𝑡𝑎𝑟, 𝜃 𝑏𝑎𝑙𝑙, 𝑑 𝑏𝑎𝑙𝑙, ℎ 𝑏𝑎𝑙𝑙, 𝑣 𝑏𝑎𝑙𝑙, 𝜔 𝑏𝑎𝑙𝑙)
報酬𝑟 𝐻
𝑟 𝐻 = 𝑤𝑐𝑣 𝑟𝑐𝑣 + 𝑤𝑐𝑝 𝑟𝑐𝑝 + 𝑤 𝑏𝑣 𝑟𝑏𝑣 + 𝑤 𝑏𝑝 𝑟𝑏𝑝
𝜃𝑡𝑎𝑟, 𝑑 𝑡𝑎𝑟 : ボールに対する目標位置の方向、距離
𝜃 𝑏𝑎𝑙𝑙, 𝑑 𝑏𝑎𝑙𝑙 : エージェントに対するボールの方向、距離
ℎ 𝑏𝑎𝑙𝑙, 𝑣 𝑏𝑎𝑙𝑙, 𝜔 𝑏𝑎𝑙𝑙 : ボールの高さ、速度、角速度
𝑔 𝐻 = (𝜃𝑡𝑎𝑟, 𝑑 𝑡𝑎𝑟, 𝜃 𝑏𝑎𝑙𝑙, 𝑑 𝑏𝑎𝑙𝑙, ℎ 𝑏𝑎𝑙𝑙, 𝑣 𝑏𝑎𝑙𝑙, 𝜔 𝑏𝑎𝑙𝑙)
29. HLC
• Soccer Dribble
ボールを目標位置までドリブルして移動させるように訓練
ボール:半径0.2m , 質量0.1kg
28
目標𝑔 𝐻
𝑔 𝐻 = (𝜃𝑡𝑎𝑟, 𝑑 𝑡𝑎𝑟, 𝜃 𝑏𝑎𝑙𝑙, 𝑑 𝑏𝑎𝑙𝑙, ℎ 𝑏𝑎𝑙𝑙, 𝑣 𝑏𝑎𝑙𝑙, 𝜔 𝑏𝑎𝑙𝑙)
報酬𝑟 𝐻
𝑟 𝐻 = 𝑤𝑐𝑣 𝑟𝑐𝑣 + 𝑤𝑐𝑝 𝑟𝑐𝑝 + 𝑤 𝑏𝑣 𝑟𝑏𝑣 + 𝑤 𝑏𝑝 𝑟𝑏𝑝
𝑟 𝐻 = 𝑤𝑐𝑣 𝑟𝑐𝑣 + 𝑤𝑐𝑝 𝑟𝑐𝑝 + 𝑤 𝑏𝑣 𝑟𝑏𝑣 + 𝑤 𝑏𝑝 𝑟𝑏𝑝
エージェントがボールへ向かって移動するように設定
𝑟𝑐𝑣 = exp − min(0, 𝑢 𝑏𝑎𝑙𝑙
T
𝑣𝑐𝑜𝑚 − 𝑣𝑐𝑜𝑚)
2
𝑢 𝑏𝑎𝑙𝑙 : エージェントからボールへ向く単位ベクトル
𝑣𝑐𝑜𝑚 : エージェントの速度
𝑣𝑐𝑜𝑚 : エージェントに求める速度
30. HLC
• Soccer Dribble
ボールを目標位置までドリブルして移動させるように訓練
ボール:半径0.2m , 質量0.1kg
29
目標𝑔 𝐻
𝑔 𝐻 = (𝜃𝑡𝑎𝑟, 𝑑 𝑡𝑎𝑟, 𝜃 𝑏𝑎𝑙𝑙, 𝑑 𝑏𝑎𝑙𝑙, ℎ 𝑏𝑎𝑙𝑙, 𝑣 𝑏𝑎𝑙𝑙, 𝜔 𝑏𝑎𝑙𝑙)
報酬𝑟 𝐻
𝑟 𝐻 = 𝑤𝑐𝑣 𝑟𝑐𝑣 + 𝑤𝑐𝑝 𝑟𝑐𝑝 + 𝑤 𝑏𝑣 𝑟𝑏𝑣 + 𝑤 𝑏𝑝 𝑟𝑏𝑝
𝑟 𝐻 = 𝑤𝑐𝑣 𝑟𝑐𝑣 + 𝑤𝑐𝑝 𝑟𝑐𝑝 + 𝑤 𝑏𝑣 𝑟𝑏𝑣 + 𝑤 𝑏𝑝 𝑟𝑏𝑝
エージェントがボールの近くに居続けるように設定
𝑟𝑐𝑝 = exp −𝑑 𝑏𝑎𝑙𝑙
2
𝑑 𝑏𝑎𝑙𝑙 : エージェントとボールの距離
31. HLC
• Soccer Dribble
ボールを目標位置までドリブルして移動させるように訓練
ボール:半径0.2m , 質量0.1kg
30
目標𝑔 𝐻
𝑔 𝐻 = (𝜃𝑡𝑎𝑟, 𝑑 𝑡𝑎𝑟, 𝜃 𝑏𝑎𝑙𝑙, 𝑑 𝑏𝑎𝑙𝑙, ℎ 𝑏𝑎𝑙𝑙, 𝑣 𝑏𝑎𝑙𝑙, 𝜔 𝑏𝑎𝑙𝑙)
報酬𝑟 𝐻
𝑟 𝐻 = 𝑤𝑐𝑣 𝑟𝑐𝑣 + 𝑤𝑐𝑝 𝑟𝑐𝑝 + 𝑤 𝑏𝑣 𝑟𝑏𝑣 + 𝑤 𝑏𝑝 𝑟𝑏𝑝
𝑟 𝐻 = 𝑤𝑐𝑣 𝑟𝑐𝑣 + 𝑤𝑐𝑝 𝑟𝑐𝑝 + 𝑤 𝑏𝑣 𝑟𝑏𝑣 + 𝑤 𝑏𝑝 𝑟𝑏𝑝
エージェントがボールを目標位置に向かって移動させるように設定
𝑟𝑏𝑣 = exp − min(0, 𝑢 𝑡𝑎𝑟
T
𝑣 𝑏𝑎𝑙𝑙 − 𝑣 𝑏𝑎𝑙𝑙)
2
𝑢 𝑡𝑎𝑟 : ボールから目標位置へ向く単位ベクトル
𝑣 𝑏𝑎𝑙𝑙 : ボールの速度
𝑣 𝑏𝑎𝑙𝑙 : ボールに求める速度
32. HLC
• Soccer Dribble
ボールを目標位置までドリブルして移動させるように訓練
ボール:半径0.2m , 質量0.1kg
31
目標𝑔 𝐻
𝑔 𝐻 = (𝜃𝑡𝑎𝑟, 𝑑 𝑡𝑎𝑟, 𝜃 𝑏𝑎𝑙𝑙, 𝑑 𝑏𝑎𝑙𝑙, ℎ 𝑏𝑎𝑙𝑙, 𝑣 𝑏𝑎𝑙𝑙, 𝜔 𝑏𝑎𝑙𝑙)
報酬𝑟 𝐻
𝑟 𝐻 = 𝑤𝑐𝑣 𝑟𝑐𝑣 + 𝑤𝑐𝑝 𝑟𝑐𝑝 + 𝑤 𝑏𝑣 𝑟𝑏𝑣 + 𝑤 𝑏𝑝 𝑟𝑏𝑝
𝑟 𝐻 = 𝑤𝑐𝑣 𝑟𝑐𝑣 + 𝑤𝑐𝑝 𝑟𝑐𝑝 + 𝑤 𝑏𝑣 𝑟𝑏𝑣 + 𝑤 𝑏𝑝 𝑟𝑏𝑝
エージェントがボールを目標位置の近くに保つように設定
𝑟𝑐𝑣 = exp −𝑑 𝑡𝑎𝑟
2
𝑑 𝑡𝑎𝑟 : ボールと目標位置の距離
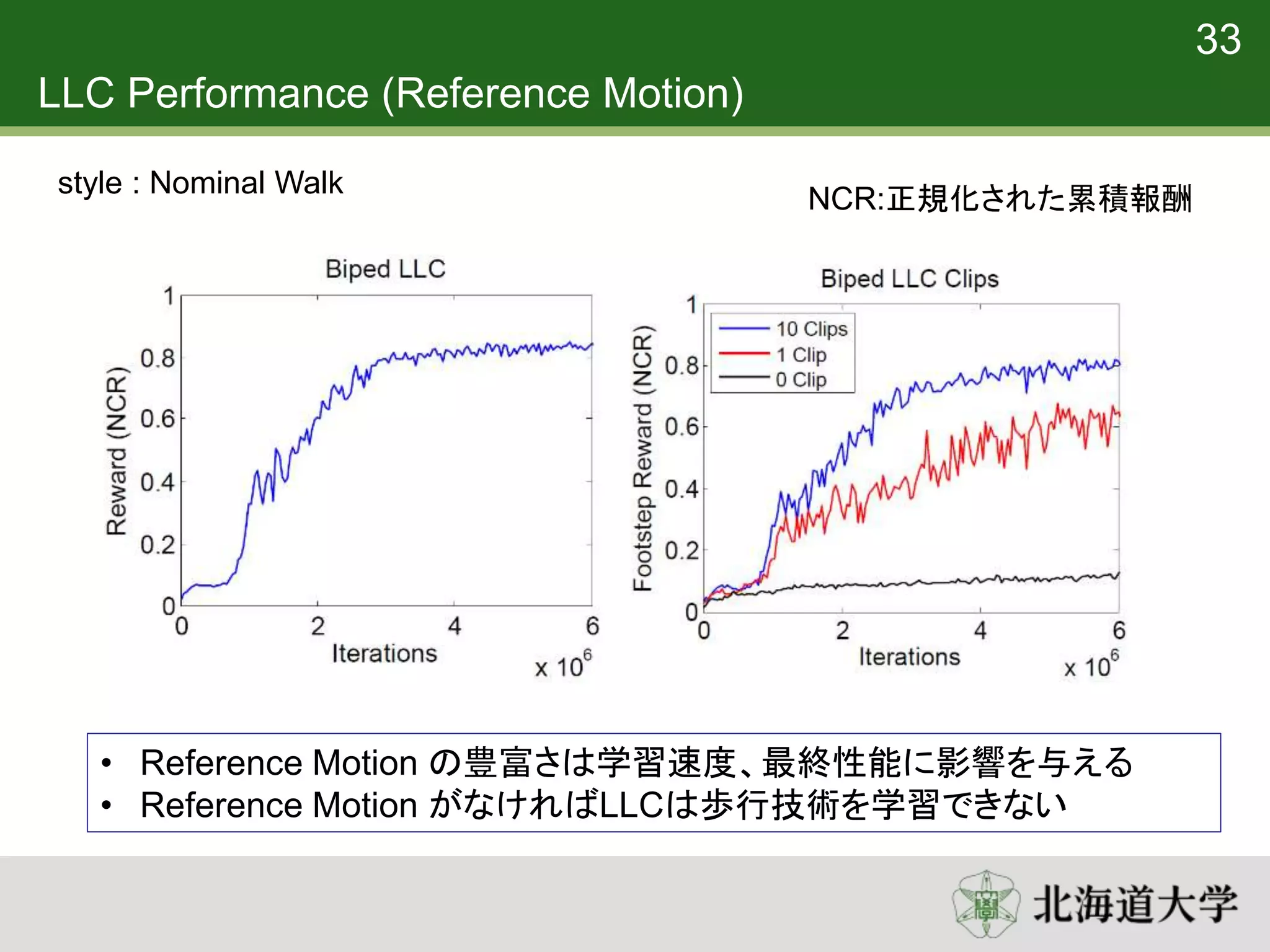
33. 34. LLC Performance (Reference Motion)
• Reference Motion の豊富さは学習速度、最終性能に影響を与える
• Reference Motion がなければLLCは歩行技術を学習できない
NCR:正規化された累積報酬
33
style : Nominal Walk
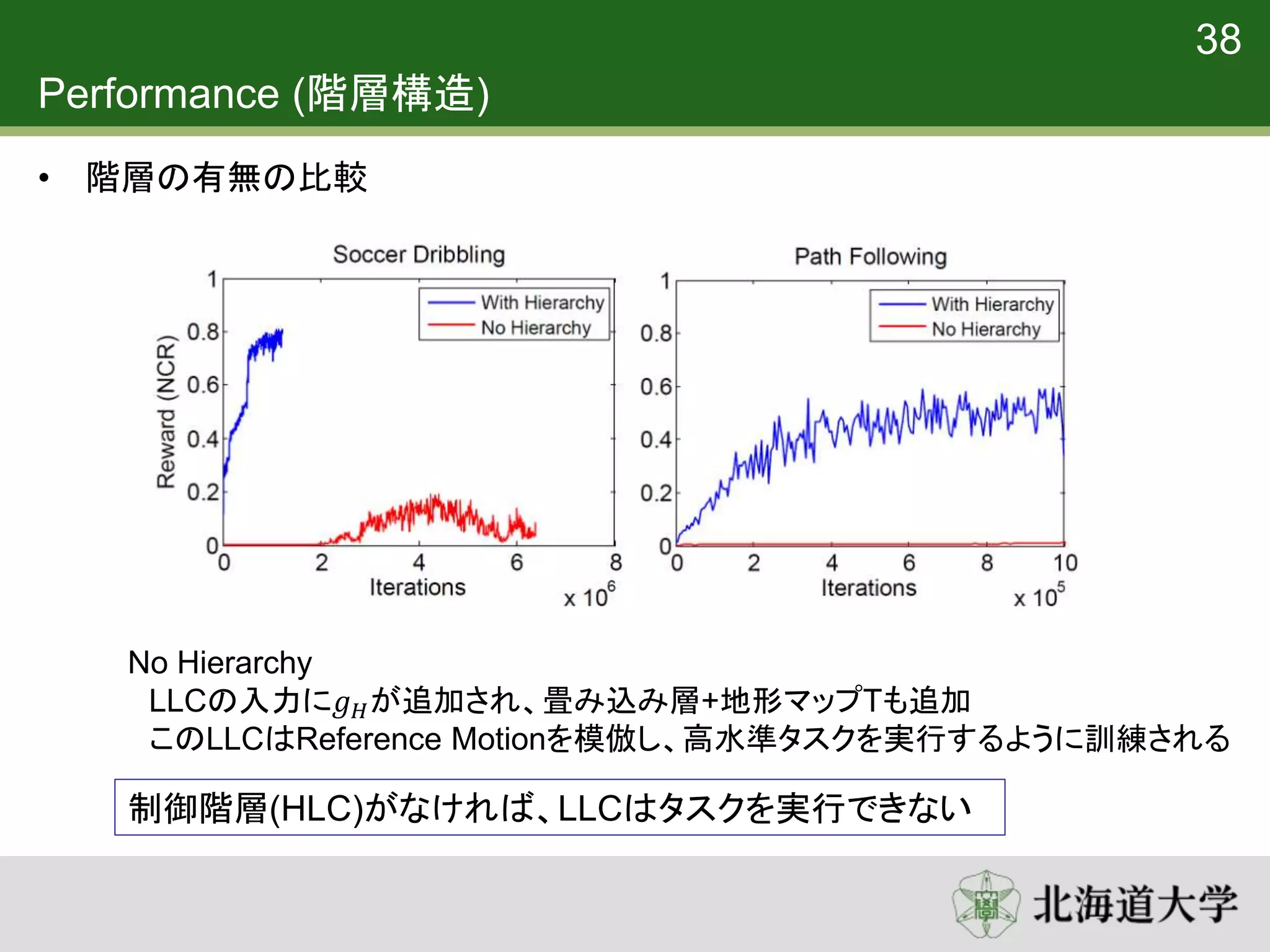
35. 36. 37. 38. 39. 40. 41. 再利用性 (階層構造)
• Nominal Walk LCC に対して訓練されたHLCを使用して20万回fine tuning
を適用
• 再学習はランダム初期化から100万回
再学習する場合に比べて、学習時間を大幅に短縮
40
42.










![強化学習 (Reinforcement Learning)
• 環境から得られる最終的な累積報酬を最大化することで学習を行う
• 累積報酬 : 𝑘=0 𝛾 𝑘
𝑟𝑡+𝑘+1
• 𝛾 : 割引率 (遠い将来に得られる報酬ほど割り引いて評価する)
• Actor-Critic 法によって累積報酬を最大化する方策を学習
• 方策 𝜋 𝑠, 𝑔 = 𝑎
• 状態𝑠, 目標𝑔の時には行動𝑎をとる
• 行動を選択する”actor”
• 価値関数 𝑉(𝑠, 𝑔)
• ある方策𝜋をとる、状態𝑠, 目標𝑔の時の累積報酬
• actorによって選択された行動を批判”critic”
• 更新式
• 𝑉 𝑠𝑡, 𝑔𝑡 ← 𝑉 𝑠𝑡, 𝑔𝑡 + 𝛼[𝑟𝑡+1 + 𝛾𝑉 𝑠𝑡+1, 𝑔𝑡+1 − 𝑉 𝑠𝑡, 𝑔𝑡 ]
11](https://image.slidesharecdn.com/deeplocoai-170707073220/75/DeepLoco-12-2048.jpg)
![強化学習 (Reinforcement Learning)
• 価値関数 𝑉(𝑠, 𝑔)
• ある方策𝜋をとる、状態𝑠, 目標𝑔の時の累積報酬
• actorによって選択された行動を批判”critic”
• 更新式
• 𝑉 𝑠𝑡, 𝑔𝑡 ← 𝑉 𝑠𝑡, 𝑔𝑡 + 𝛼[𝑟𝑡+1 + 𝛾𝑉 𝑠𝑡+1, 𝑔𝑡+1 − 𝑉 𝑠𝑡, 𝑔𝑡 ]
12
𝑉𝑡
𝑉𝑡+1
𝛾𝑉𝑡+1
報酬
𝑟𝑡
TD誤差
TD誤差
状態𝑠𝑡 状態𝑠𝑡+1
TD誤差 > 0
• 行った行動は価値を高めた
• その行動がより選択されるようにする](https://image.slidesharecdn.com/deeplocoai-170707073220/75/DeepLoco-13-2048.jpg)
















































![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning agile and dynamic motor skills for legged robots](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar0125nishimura-190125001509-thumbnail.jpg?width=640&height=640&fit=bounds)































