Downloaded 689 times




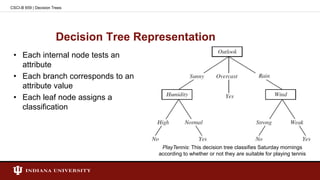
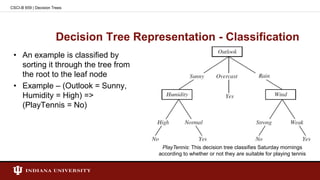





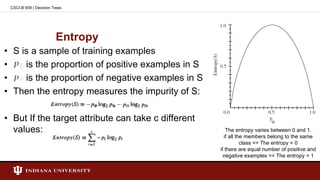
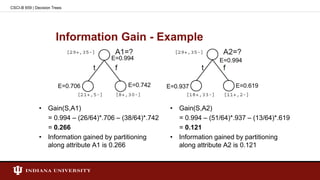
![Entropy - Example
• Entropy([29+, 35-]) = - (29/64) log2(29/64) - (35/64) log2(35/64)
= 0.994
CSCI-B 659 | Decision Trees](https://image.slidesharecdn.com/presentationdecisiontreesmilind-150204024306-conversion-gate01/85/Decision-Tree-Learning-12-320.jpg)









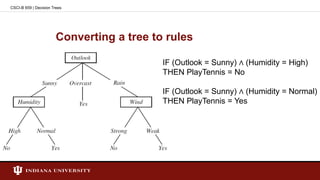


![Attributes with costs
• Problem:
• Medical diagnosis, BloodTest has cost $150
• Robotics, Width_from_1ft has cost 23 sec
• One Approach - replace gain
• Tan and Schlimmer (1990)
• Nunez (1988)
• where w ∈ [0, 1] is a constant that determines the relative importance of cost versus information
gain.
CSCI-B 659 | Decision Trees](https://image.slidesharecdn.com/presentationdecisiontreesmilind-150204024306-conversion-gate01/85/Decision-Tree-Learning-30-320.jpg)





The document provides an overview of decision tree learning, detailing its representation, the ID3 algorithm, and key concepts like entropy and information gain. It discusses the structure of decision trees, their applications, and challenges such as overfitting and handling missing data. Illustrative examples demonstrate how attributes are evaluated for creating the best decision tree, along with methods for avoiding overfitting and pruning techniques.











































































































