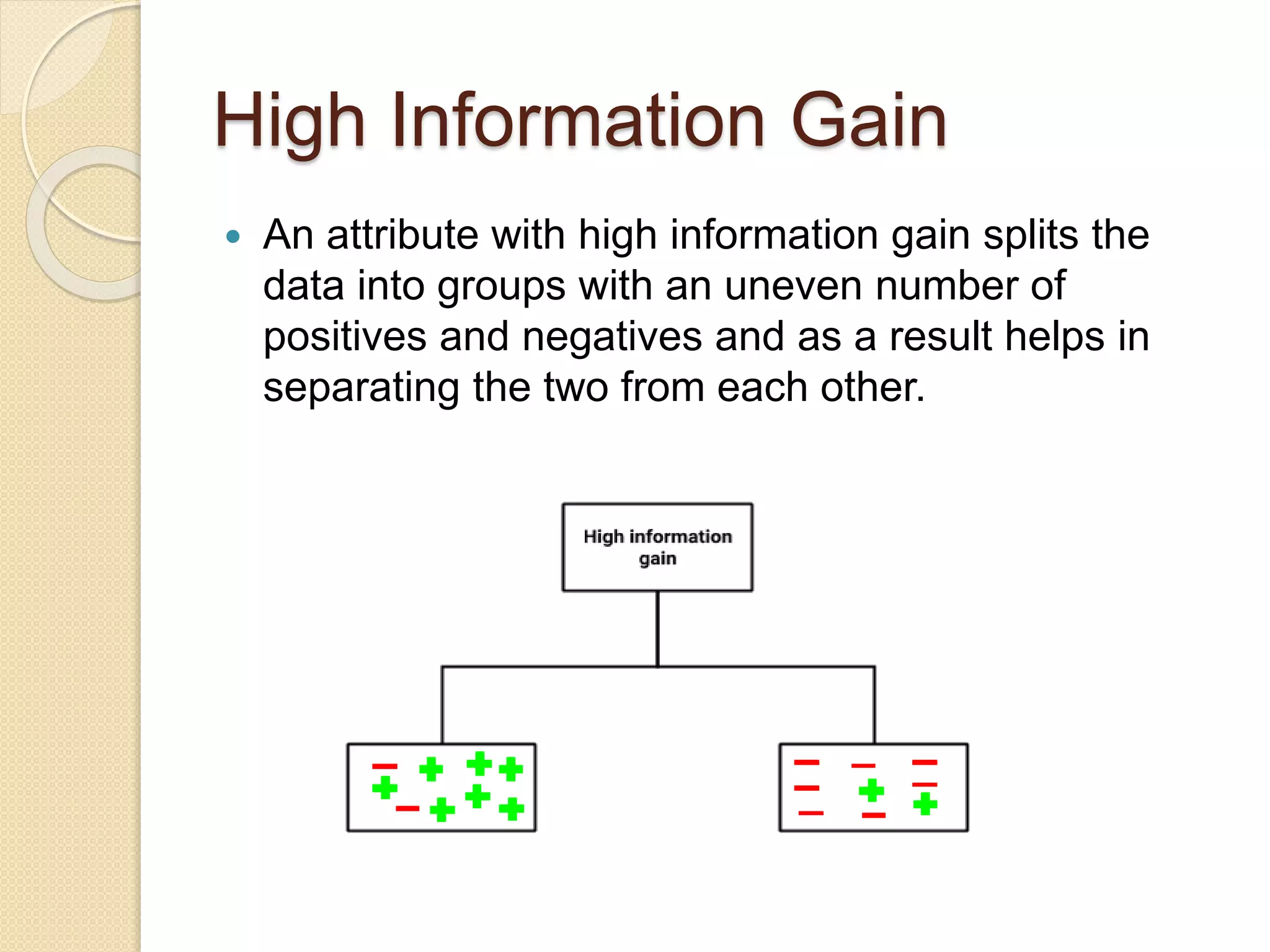
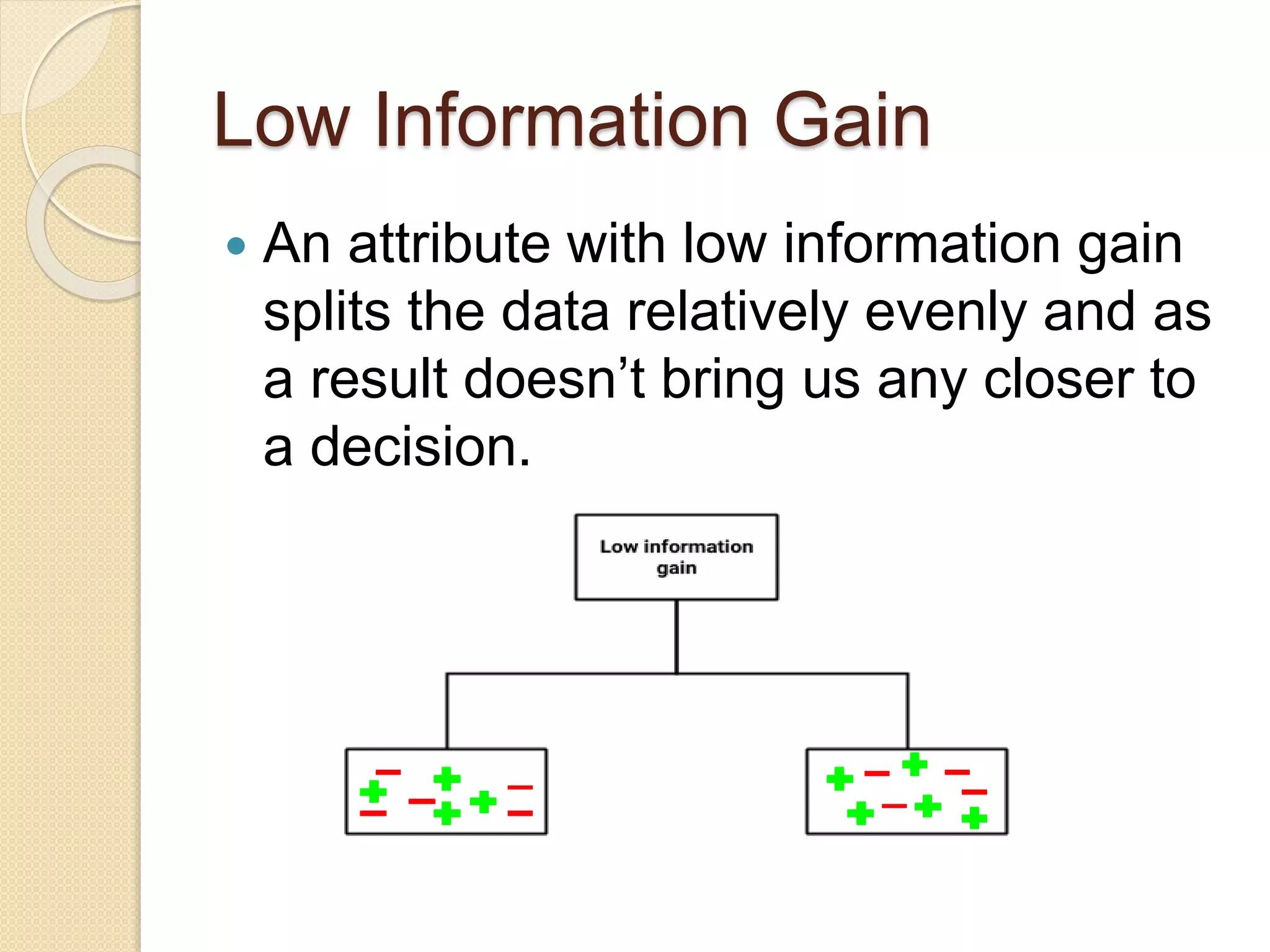
A decision tree is a popular supervised learning tool used for classification and prediction, represented as a flowchart-like structure. The document discusses key concepts such as selecting the deciding node, measuring uncertainty through entropy and information gain, and the Gini impurity. It also outlines the steps to create a decision tree and highlights its pros and cons.

























































![[Women in Data Science Meetup ATX] Decision Trees](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontrees-161118165341-thumbnail.jpg?width=640&height=640&fit=bounds)


















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


