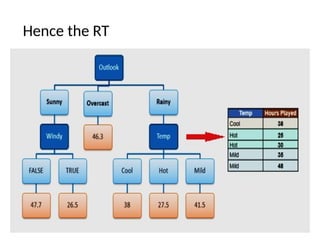
• Decision treerepresentation
– Objective
• Classify the instances by sorting them down the tree from
the root to some leaf node, which provides the class of the
instance
– Each node tests the attribute of an instance whereas each branch
descending from that node specifies one possible value of this
attribute
– Testing
• Start at the root node, test the attribute specified by this
node and identify the appropriate branch then repeat the
process
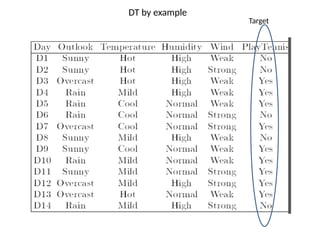
– Example
• Decision tree for classifying the Saturday mornings to test
whether it is suitable for playing outdoor game based on the
weather attributes
4.
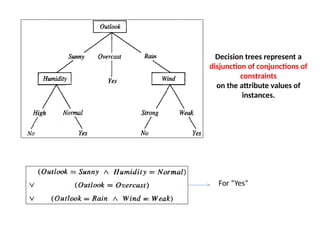
For “Yes”
Decision treesrepresent a
disjunction of conjunctions of
constraints
on the attribute values of
instances.
5.
• The characteristicsof best suited problems for DT
– Instances that are represented by attribute-value pairs
• Each attribute takes small number of disjoint possible values (e.g., Hot,
Mild, Cold) discrete
• Real-valued attributes like temperature continuous
– The target function has discrete output values
• Binary, multi-class and real-valued outputs
– Disjunctive descriptions may be required
– The training data may contain errors
• DT robust to both errors: errors in classification and attributes
– The training data may contain missing attribute values
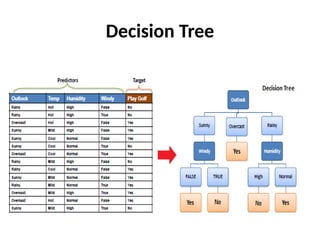
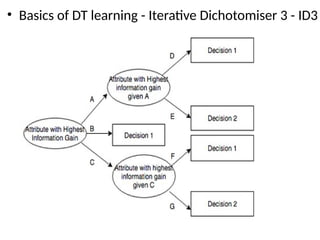
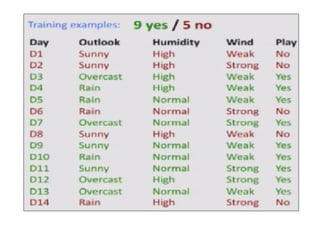
• ID3 algorithm
–ID3 algorithm begins with the original set S as the root node.
– On each iteration of the algorithm, it iterates through every
unused attribute of the set S and calculates the entropy H(S)
(or information gain IG(S)) of that attribute.
– It then selects the attribute which has the smallest entropy (or
largest information gain) value.
• The set S is then split by the selected attribute (e.g. age is less than 50,
age is between 50 and 100, age is greater than 100) to produce subsets
of the data.
– The algorithm continues to recurs on each subset, considering
only attributes never selected before.
10.
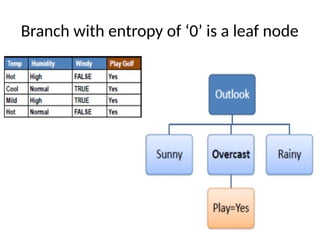
• Recursion ona subset may stop, When
– All the elements in the class belong to same class
– All instances does not belong to same class but there is no
attribute to select
– There is no example in the subset
• Steps in ID3
– Calculate the entropy of every attribute using the data set S
– Split the set S into subsets using the attribute for which the
resulting entropy (after splitting) is minimum (or, equivalently,
information gain is maximum)
– Make a decision tree node containing that attribute
– Recurs on subsets using remaining attributes.
11.
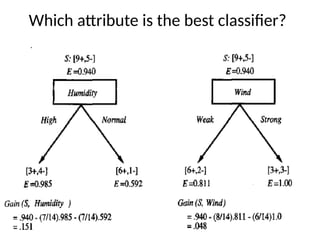
• Root -Significance
– Root node
• Which attribute should be tested at the root of the DT?
– Decided based on the information gain or entropy
– Significance
» The best attribute that classifies the training samples very
well
» The attribute that should be tested in all the instances of the
dataset
• @root node
– Information gain is more or entropy has the least value
• Entropy measures the homogeneity or impurities in the
instances
• Information gain measures the expected reduction in
entropy
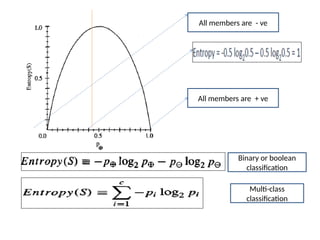
13.
All members are+ ve
All members are - ve
Binary or boolean
classification
Multi-class
classification
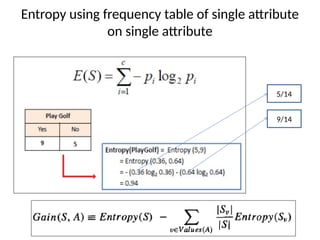
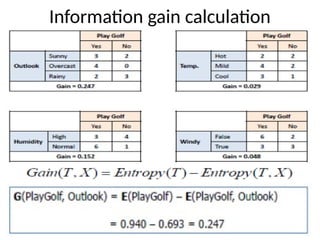
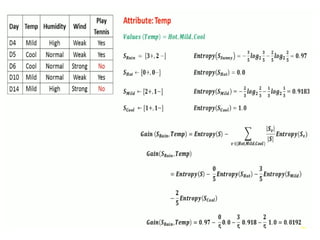
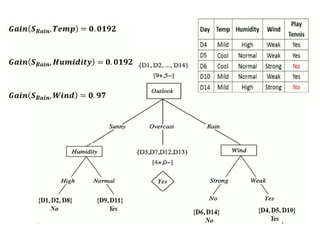
Entropy using frequencytable of single attribute on dependent attribute
PlayGolf on Outlook
PlayGolf on Temperature
PlayGolf on Humidity
PlayGolf on Windy
22.
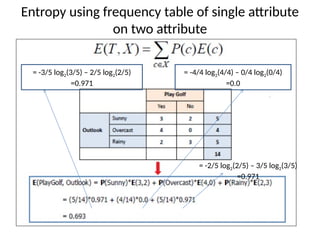
Entropy using frequencytable of single attribute
on two attribute
= -3/5 log2(3/5) – 2/5 log2(2/5)
=0.971
= -4/4 log2(4/4) – 0/4 log2(0/4)
=0.0
= -2/5 log2(2/5) – 3/5 log2(3/5)
=0.971
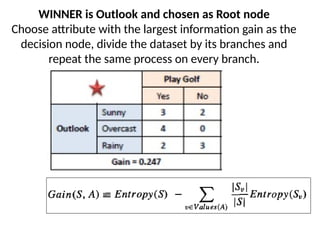
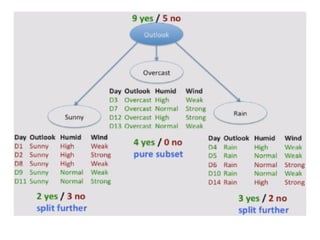
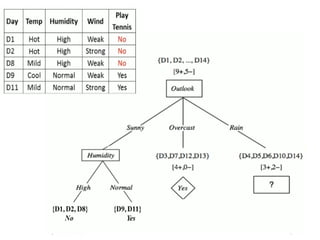
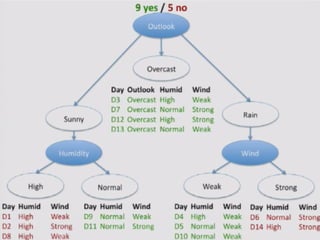
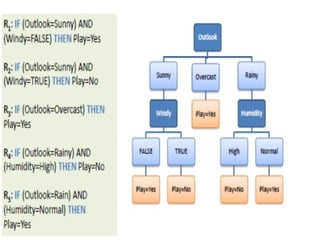
WINNER is Outlookand chosen as Root node
Choose attribute with the largest information gain as the
decision node, divide the dataset by its branches and
repeat the same process on every branch.
29.
Choose the othernodes below the root
node
Iterate the same procedure for finding
the root node
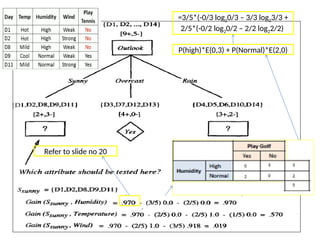
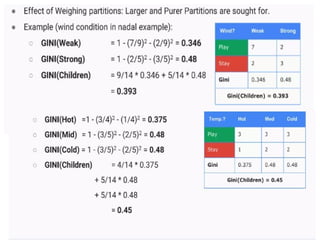
Gini Gain forall input features
Gini gain (S, outlook) = 0.459 - 0.342 = 0.117
Gini gain(S, Temperature) = 0.459 - 0.4405 = 0.0185
Gini gain(S, Humidity) = 0.459 - 0.3674 = 0.0916
Gini gain(S, windy) = 0.459 - 0.4286 = 0.0304
Choose one that has a higher Gini gain. Gini gain is
higher for outlook. So we can choose it as our root
node.
Gini(S) = 1 - [(9/14)² + (5/14)²] = 0.4591
43.
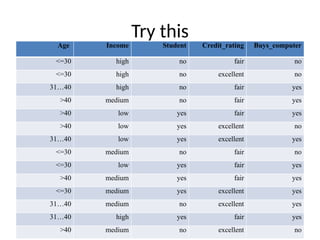
Try this
Age IncomeStudent Credit_rating Buys_computer
<=30 high no fair no
<=30 high no excellent no
31…40 high no fair yes
>40 medium no fair yes
>40 low yes fair yes
>40 low yes excellent no
31…40 low yes excellent yes
<=30 medium no fair no
<=30 low yes fair yes
>40 medium yes fair yes
<=30 medium yes excellent yes
31…40 medium no excellent yes
31…40 high yes fair yes
>40 medium no excellent no
44.
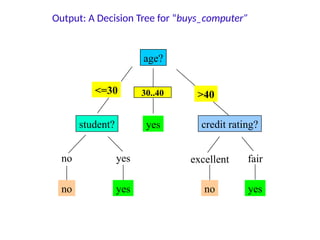
Output: A DecisionTree for “buys_computer”
age?
overcast
student? credit rating?
no yes fair
excellent
<=30 >40
no no
yes yes
yes
30..40
45.
Pruning Trees
• Removesubtrees for better generalization
(decrease variance)
– Prepruning: Early stopping
– Postpruning: Grow the whole tree then prune subtrees
which overfit on the pruning set
• Prepruning is faster, postpruning is more
accurate (requires a separate pruning set)
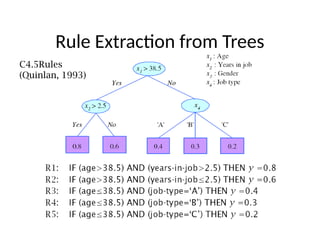
Learning Rules
• Ruleinduction is similar to tree induction but
– tree induction is breadth-first,
– rule induction is depth-first; one rule at a time
• Rule set contains rules; rules are conjunctions of terms
• Rule covers an example if all terms of the rule evaluate
to true for the example
• Sequential covering: Generate rules one at a time until
all positive examples are covered
• IREP (Fürnkrantz and Widmer, 1994), Ripper (Cohen,
1995)
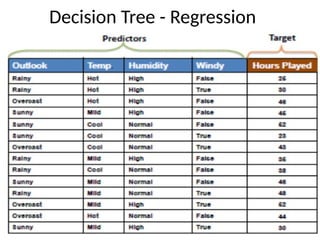
• Regression DecisionTree
– The ID3 algorithm can be used to construct a decision tree for
regression by replacing Information Gain with Standard
Deviation Reduction
– If the numerical sample is completely homogeneous its standard
deviation is zero
– Algorithm
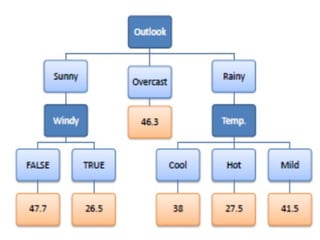
• Step 1: The standard deviation of the target is calculated.
• Step 2: The dataset is then split on the different attributes. The standard
deviation for each branch is calculated. The resulting standard deviation
is subtracted from the standard deviation before the split. The result is
the standard deviation reduction.
• Step 3: The attribute with the largest standard deviation reduction is
chosen as the decision node.
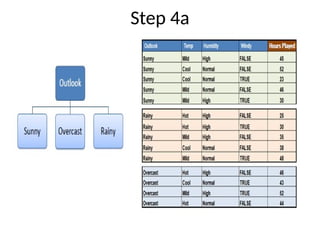
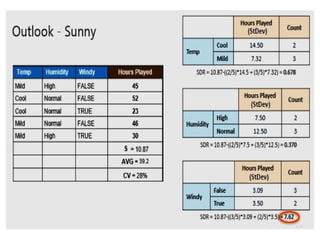
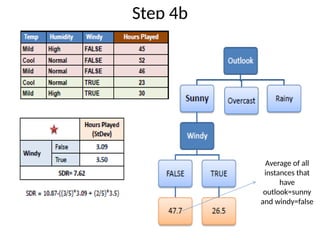
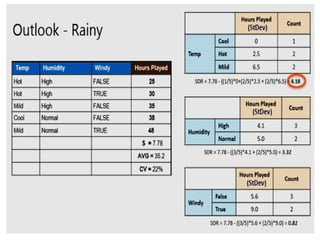
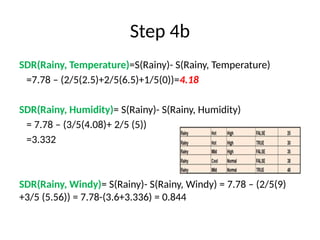
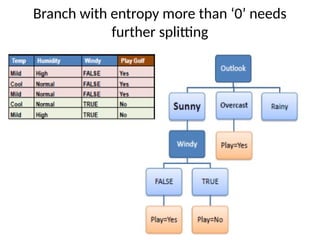
• Step 4a: Dataset is divided based on the values of the selected attribute.
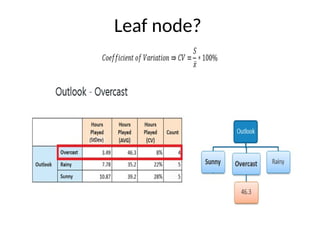
• Step 4b: A branch set with standard deviation more than 0 needs further
splitting.






















![Gini Gain for all input features
Gini gain (S, outlook) = 0.459 - 0.342 = 0.117
Gini gain(S, Temperature) = 0.459 - 0.4405 = 0.0185
Gini gain(S, Humidity) = 0.459 - 0.3674 = 0.0916
Gini gain(S, windy) = 0.459 - 0.4286 = 0.0304
Choose one that has a higher Gini gain. Gini gain is
higher for outlook. So we can choose it as our root
node.
Gini(S) = 1 - [(9/14)² + (5/14)²] = 0.4591](https://image.slidesharecdn.com/decisiontreeslearning-250503033348-6462bfe8/85/Decision-Trees-Learning-in-Machine-Learning-42-320.jpg)