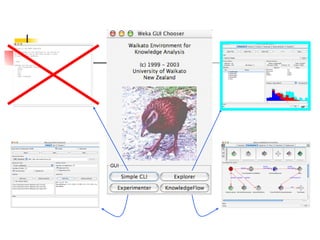
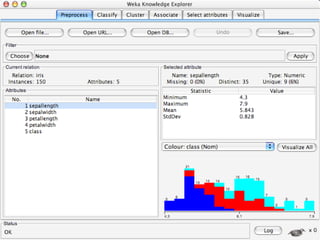
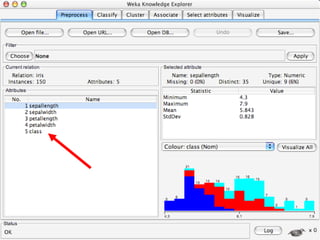
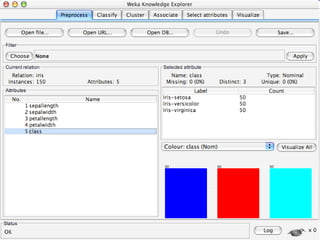
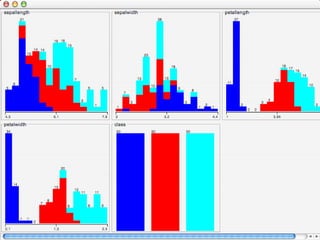
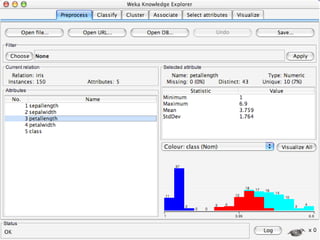
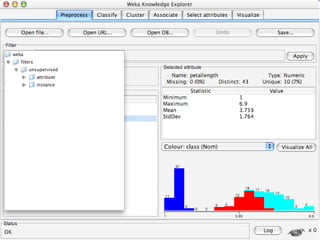
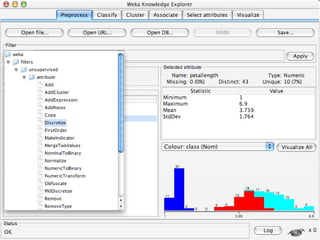
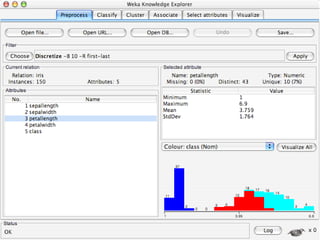
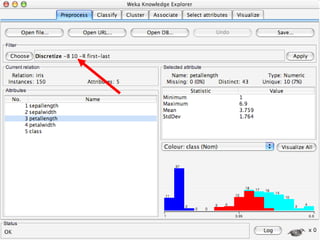
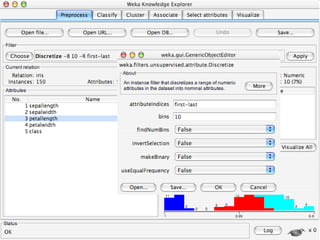
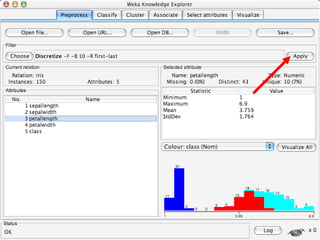
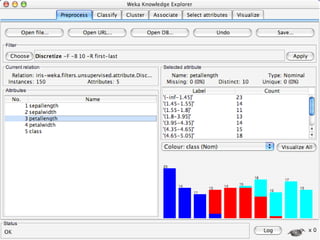
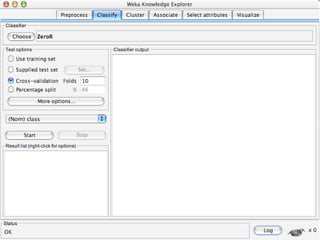
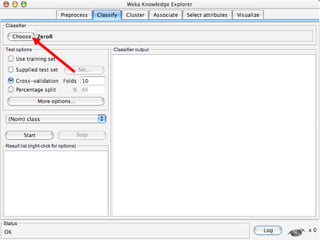
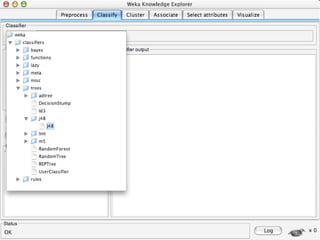
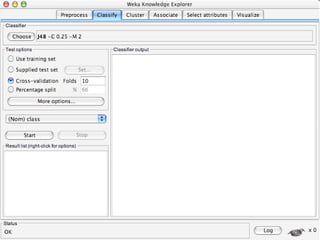
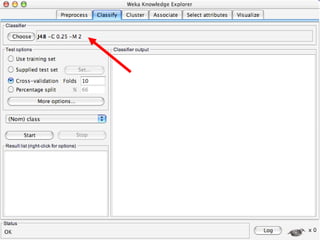
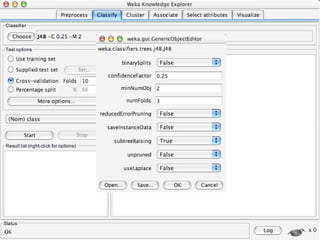
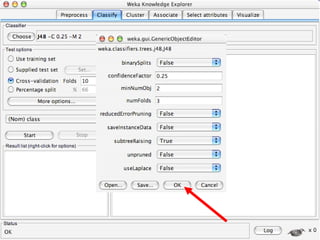
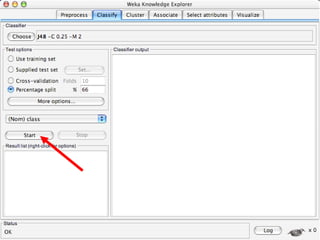
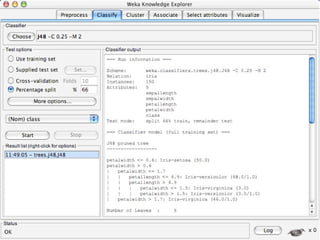
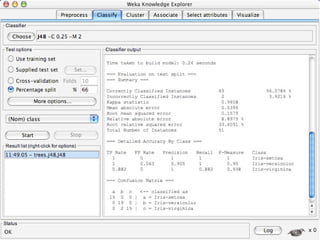
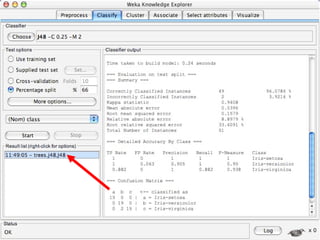
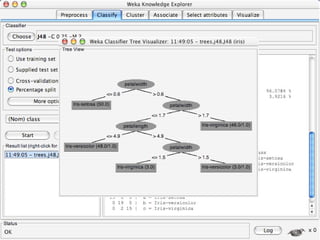
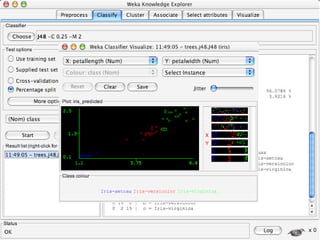
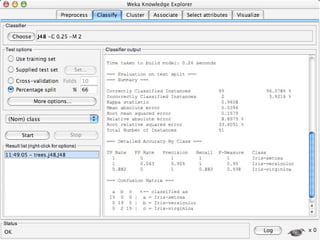
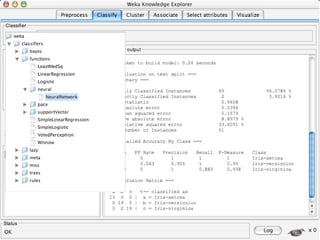
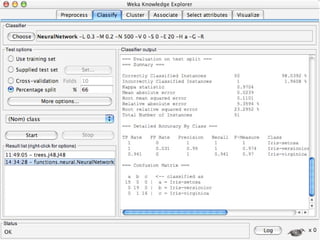
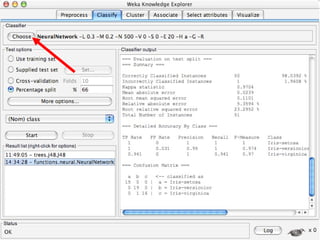
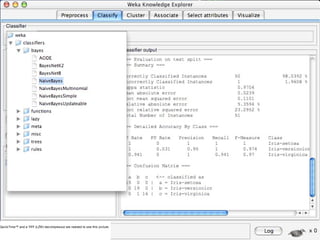
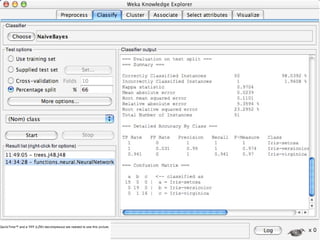
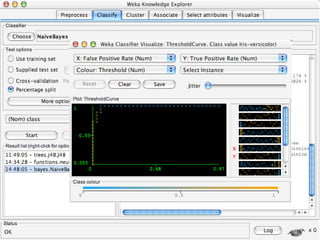
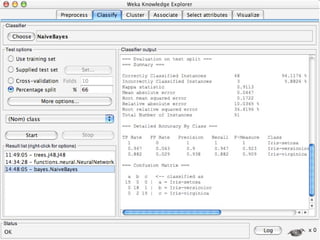
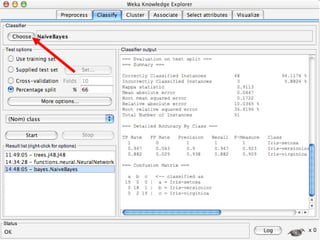
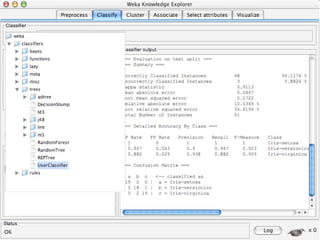
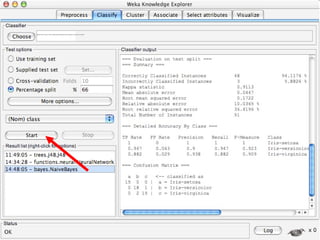
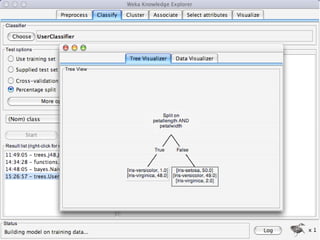
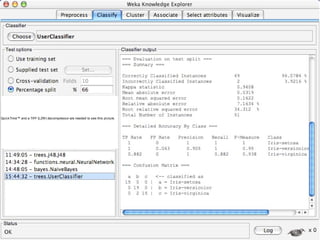
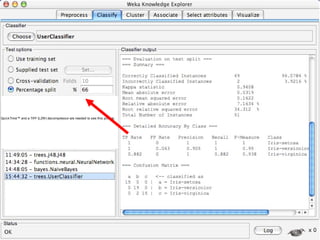
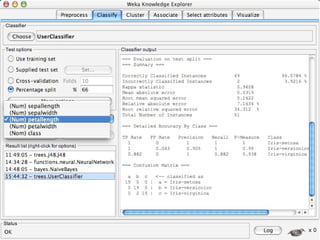
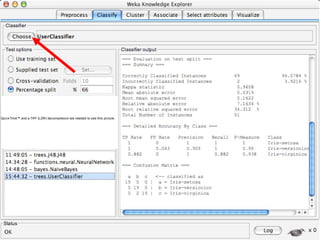
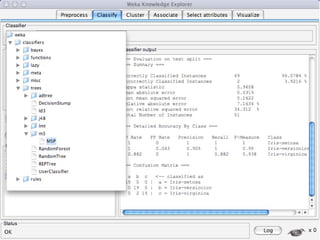
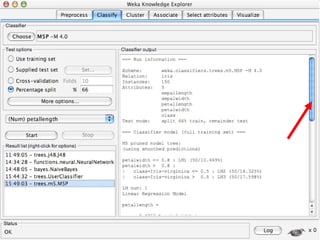
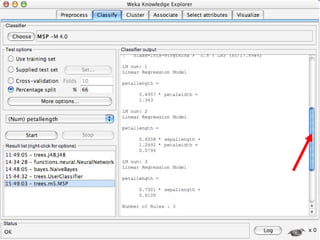
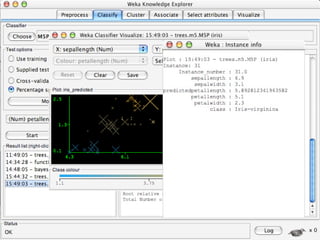
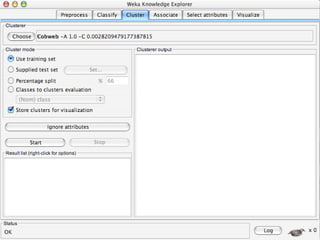
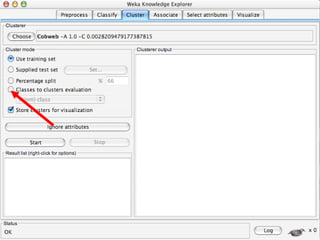
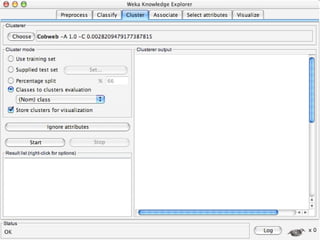
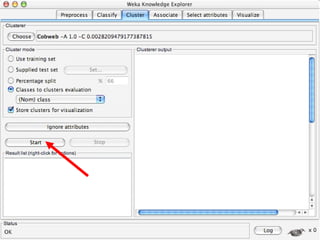
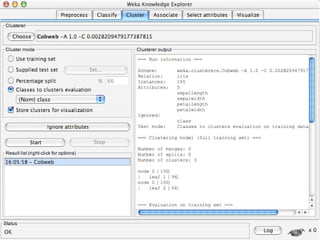
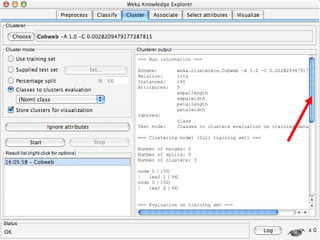
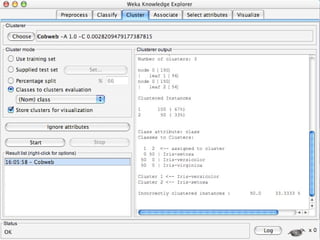
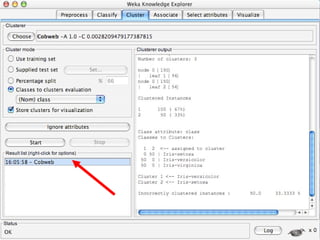
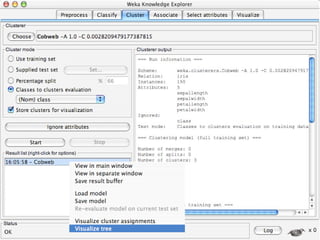
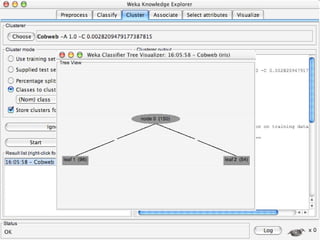
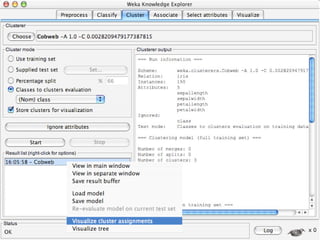
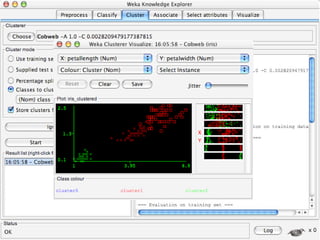
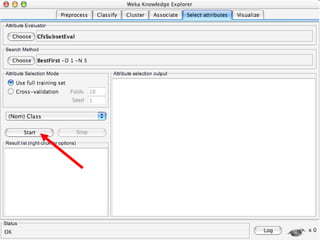
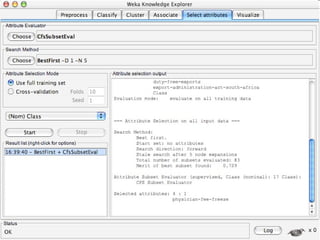
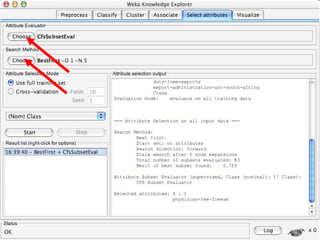
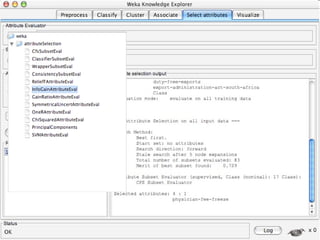
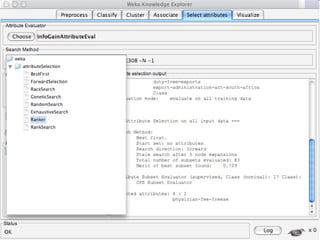
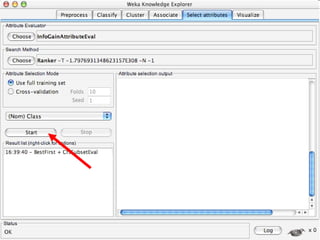
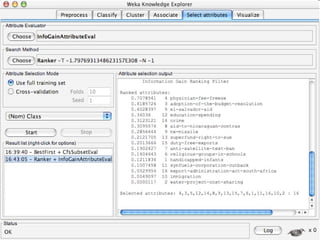
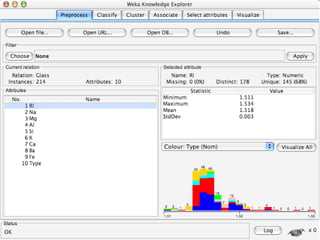
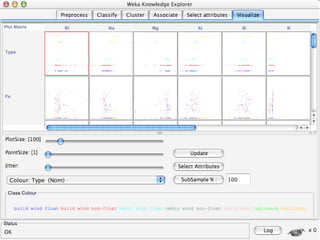
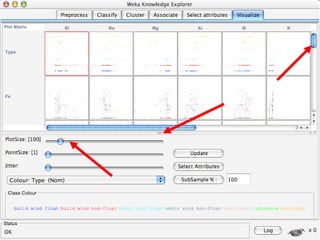
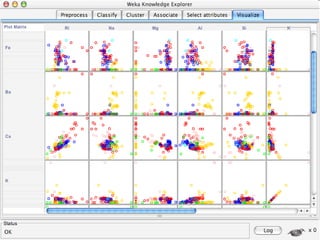
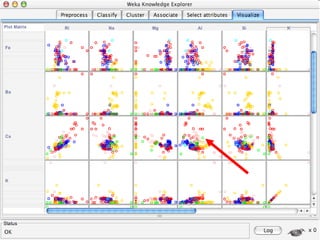
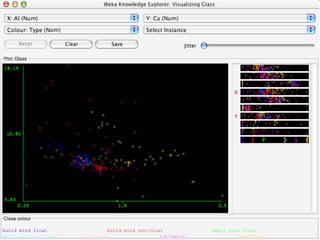
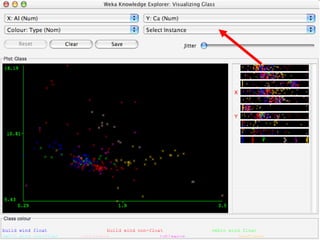
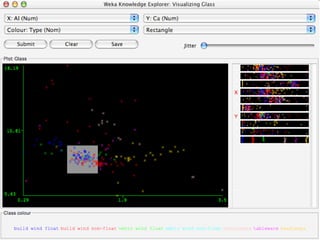
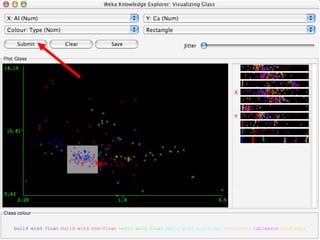
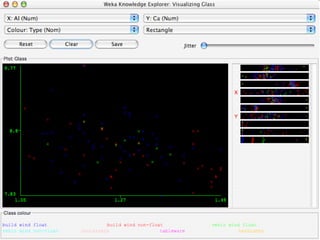
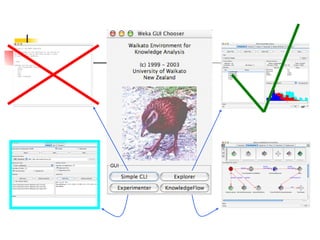
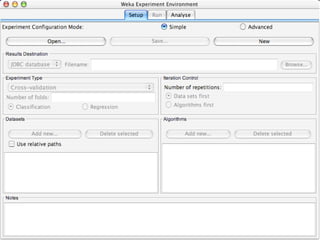
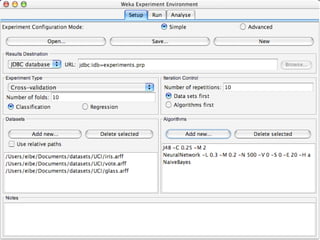
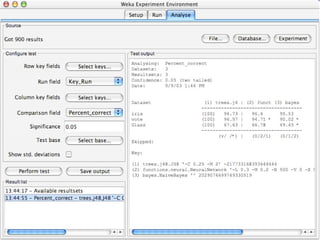
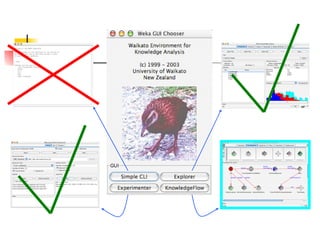
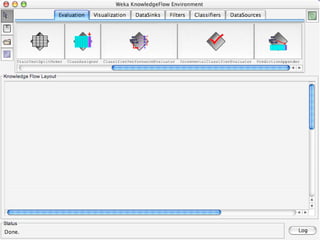
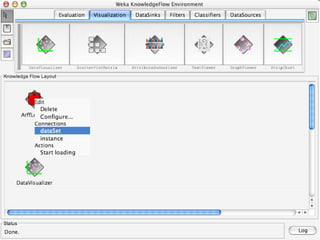
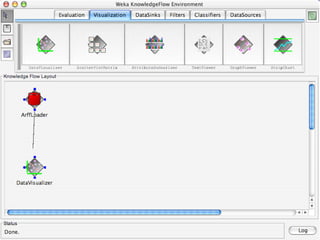
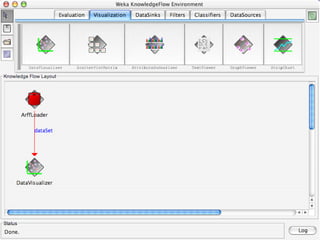
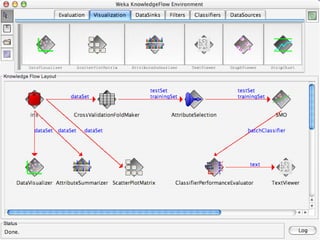
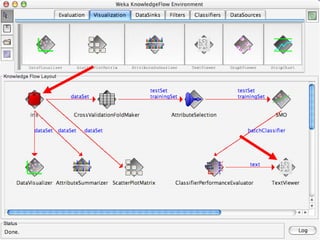
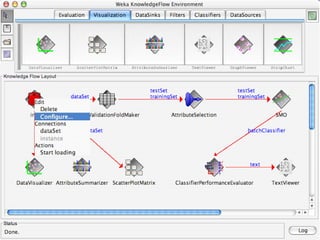
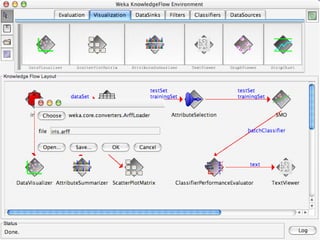
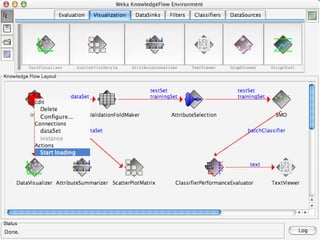
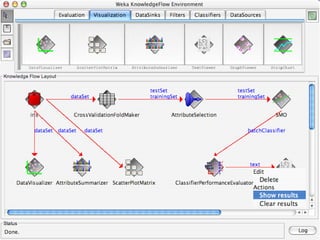
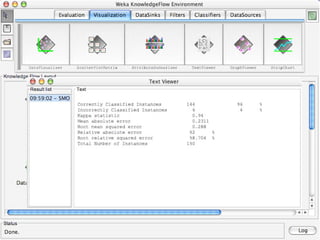
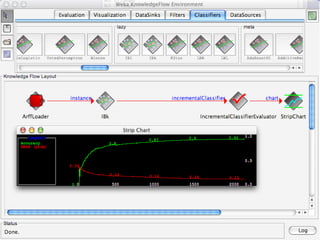
WEKA is machine learning software written in Java that is used for data mining tasks. It contains tools for pre-processing data, building classifiers, clustering data, finding associations, attribute selection, and visualizing data. WEKA also allows users to perform experiments to compare the performance of different learning algorithms on classification and regression problems. It has graphical user interfaces that make it easy to set up and run machine learning experiments by connecting different components in a workflow.













































































![Microsoft PowerPoint - weka [Read-Only]](https://cdn.slidesharecdn.com/ss_thumbnails/microsoft-powerpoint-weka-readonly3765-thumbnail.jpg?width=640&height=640&fit=bounds)






















