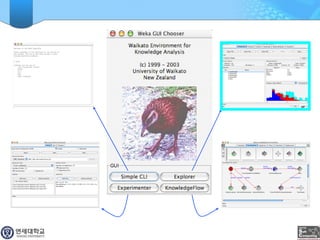
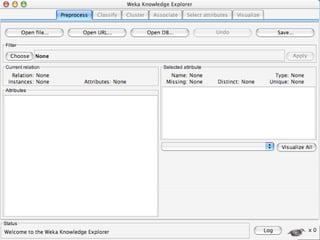
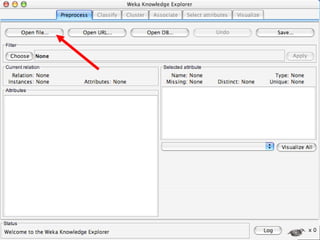
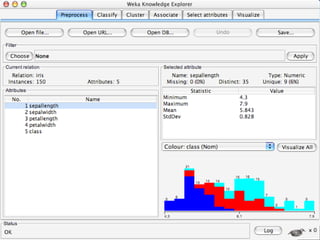
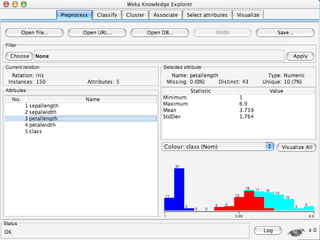
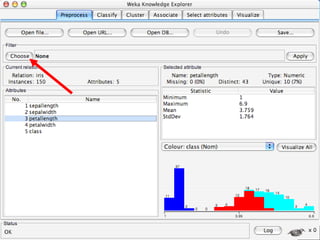
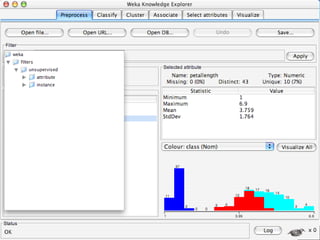
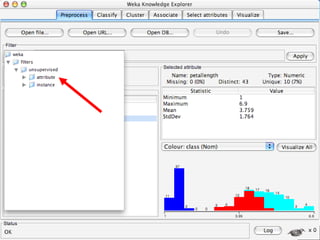
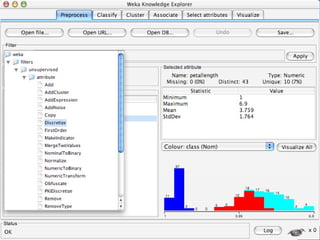
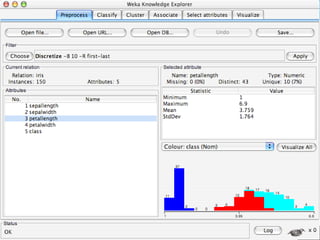
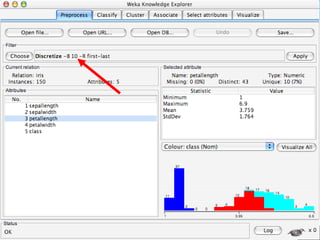
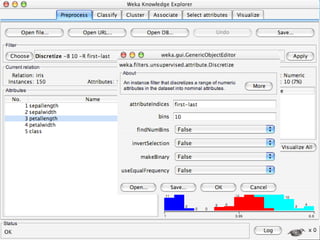
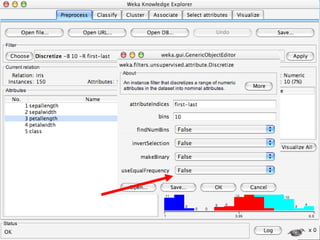
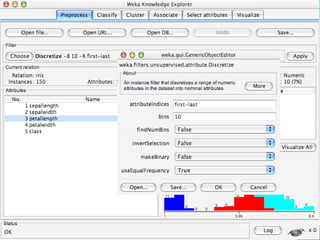
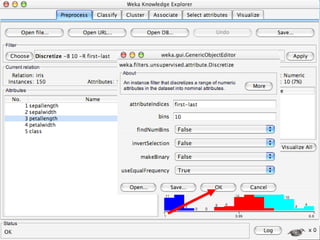
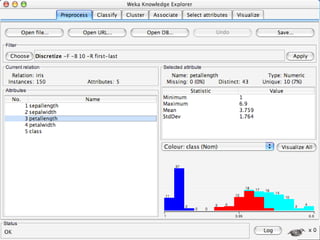
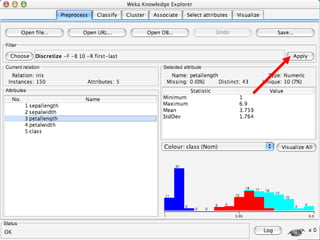
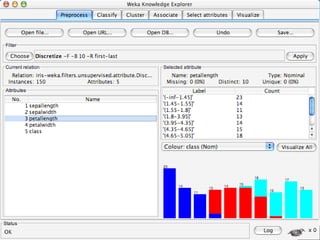
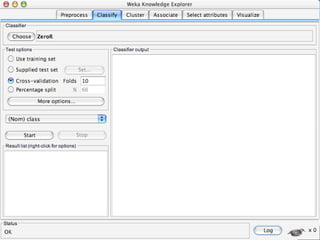
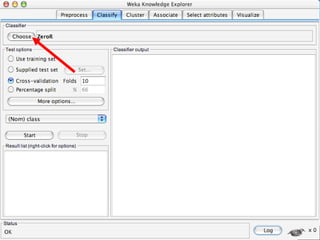
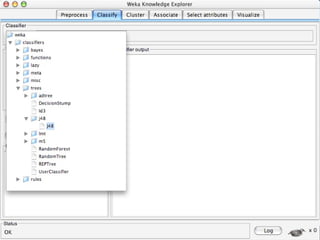
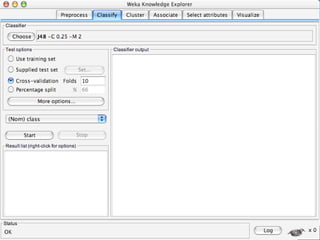
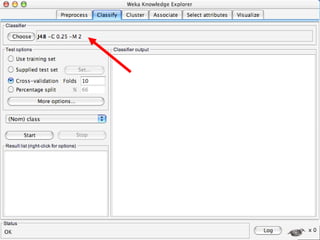
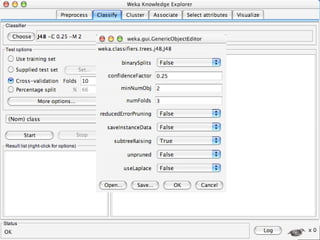
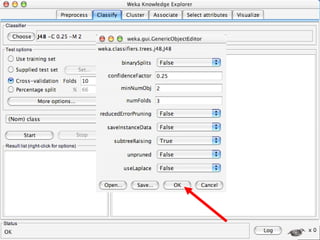
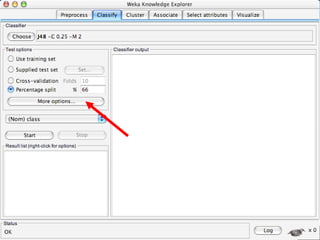
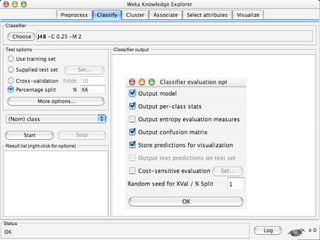
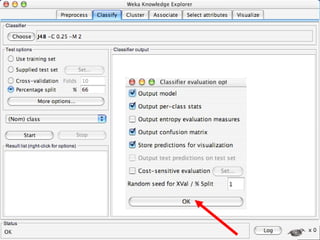
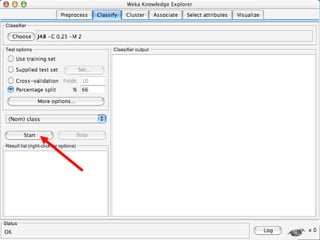
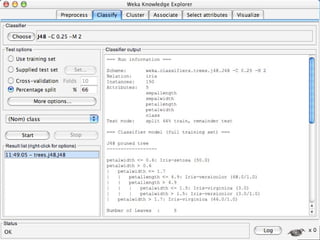
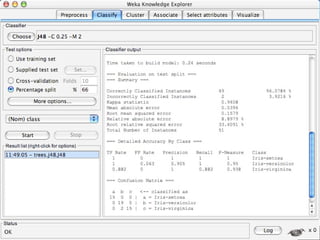
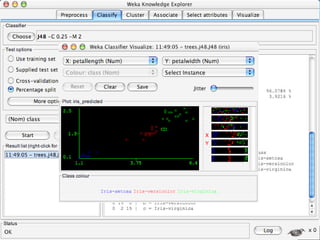
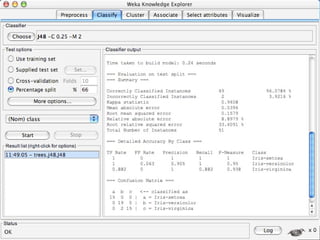
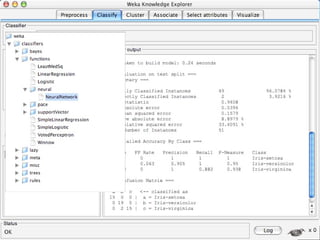
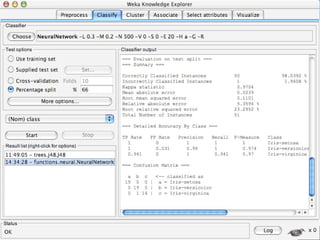
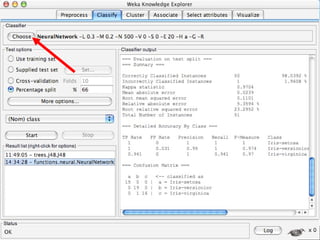
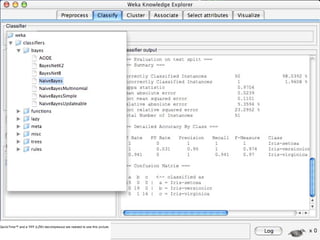
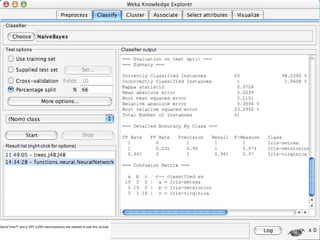
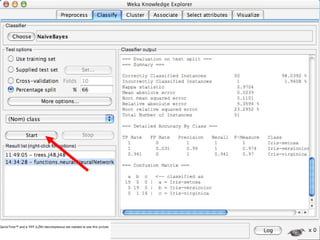
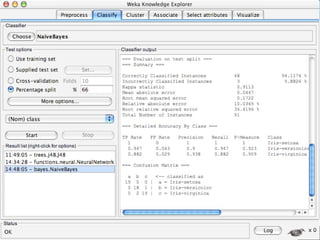
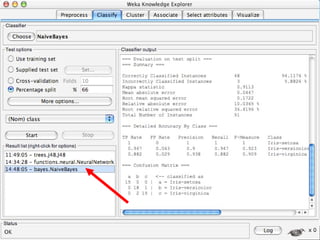
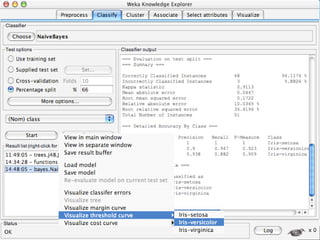
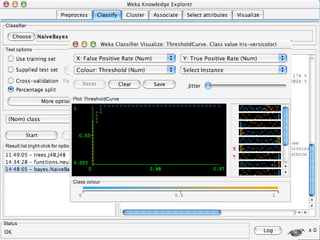
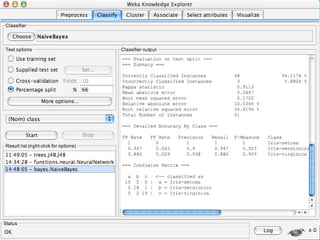
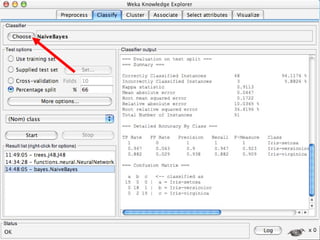
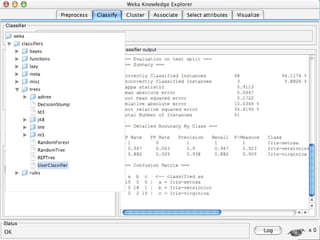
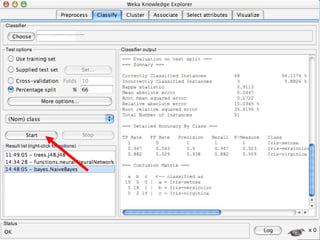
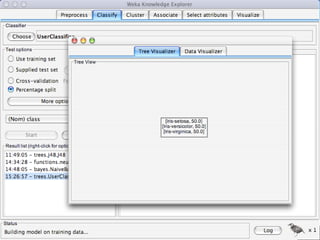
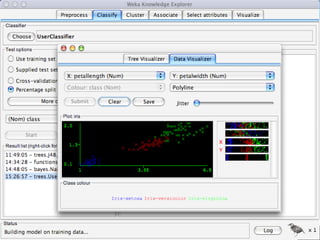
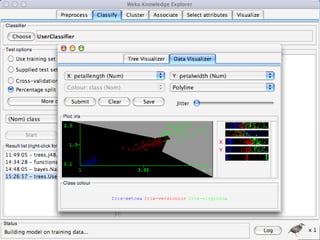
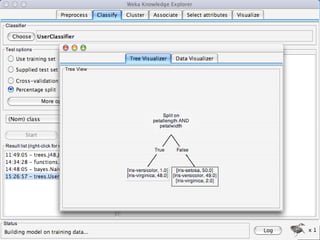
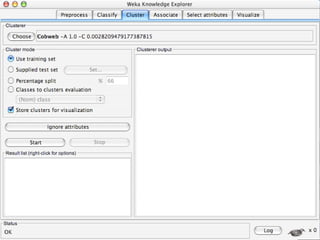
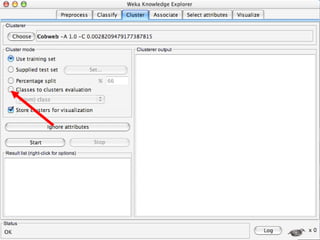
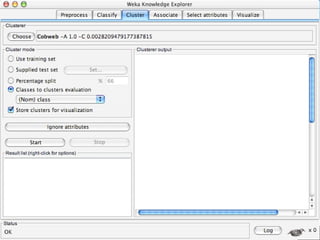
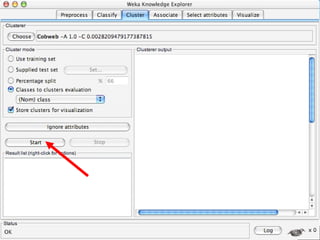
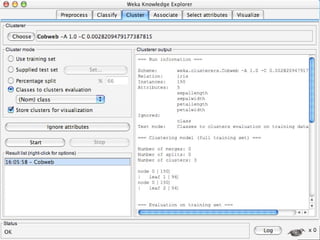
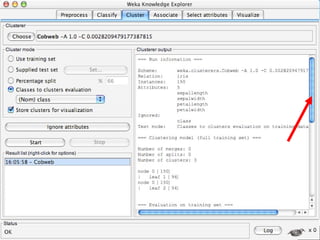
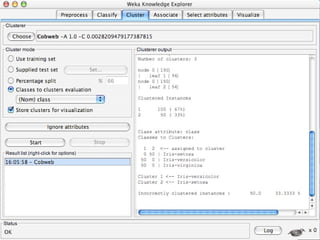
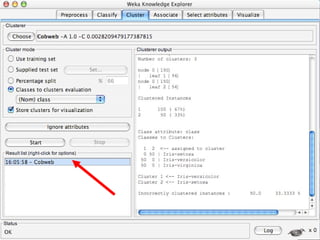
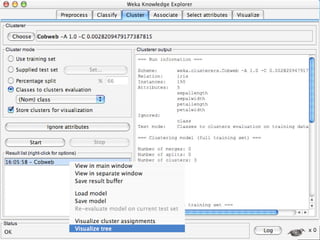
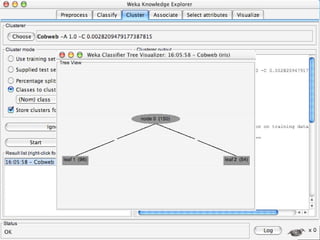
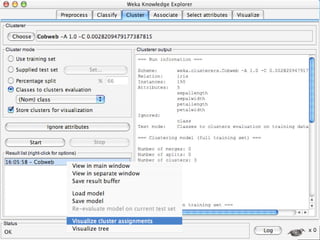
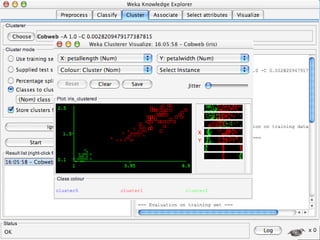
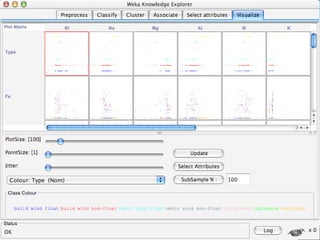
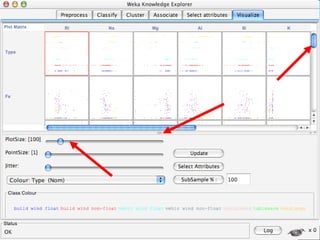
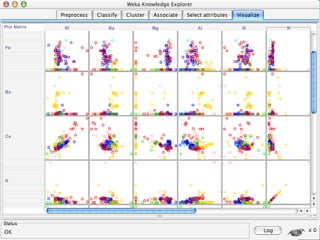
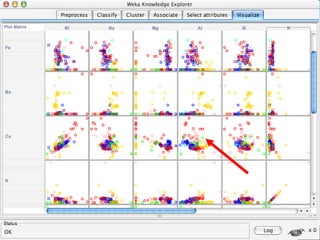
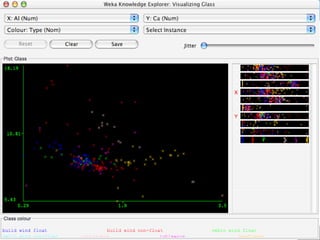
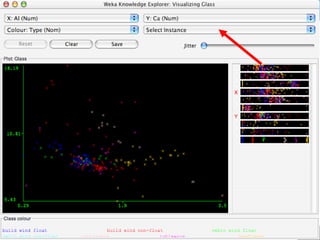
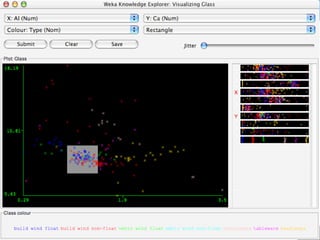
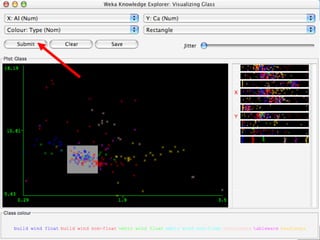
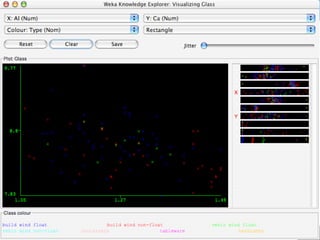
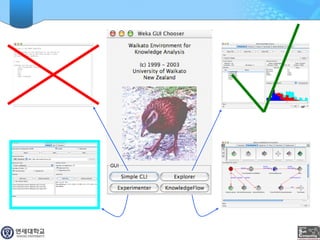
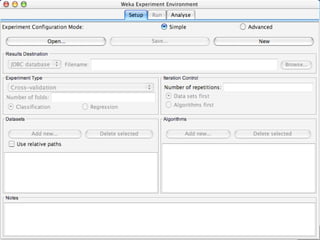
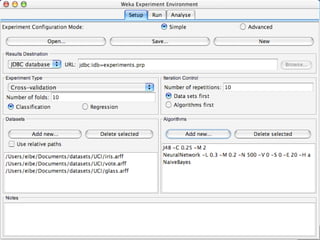
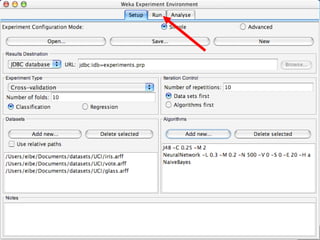
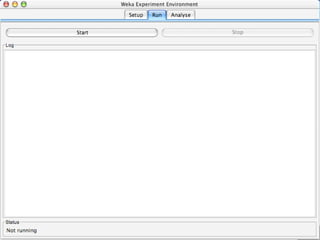
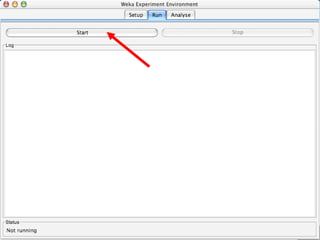
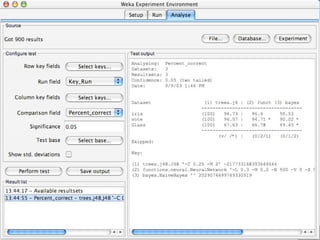
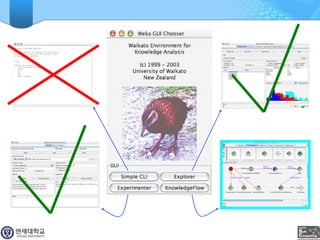
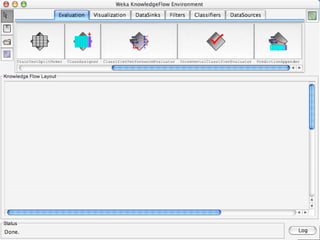
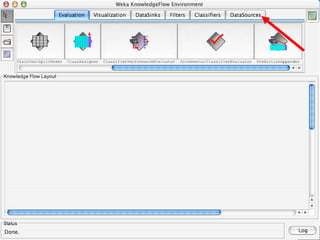
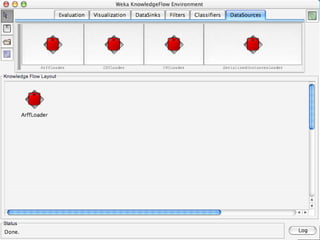
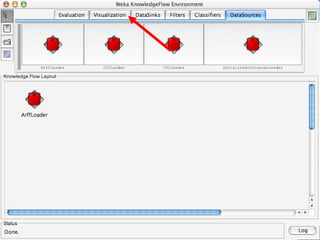
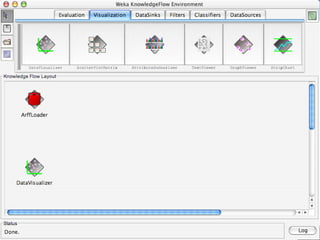
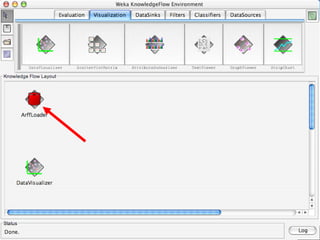
WEKA is a machine learning toolkit written in Java that contains tools for data pre-processing, classification, regression, clustering, visualization, and evaluating machine learning algorithms. It contains algorithms like decision trees, neural networks, and support vector machines. The toolkit includes graphical user interfaces for exploring data and models as well as an experiment environment for comparing machine learning algorithms. WEKA is open source and available for research, education, and applications.


























































![Microsoft PowerPoint - weka [Read-Only]](https://cdn.slidesharecdn.com/ss_thumbnails/microsoft-powerpoint-weka-readonly3765-thumbnail.jpg?width=640&height=640&fit=bounds)




















