














![Statistical Modeling: An exampleDerivation using Bayes’ rule:Acc to Bayes’ rule, for a hypothesis H and evidence E that bears on that hypothesis, then P[H|E] = (P[E|H] x P[H]) / P[E]For our example hypothesis H is that play will be, say, yes and E is the particular combination of attribute values at handOutlook = sunny(E1)Temperature = cool (E2)Humidity = high(E3)Windy = True (E4)](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-17-320.jpg)
![Statistical Modeling: An exampleDerivation using Bayes’ rule:Now since E1, E2, E3 and E4 are independent therefore we have P[H|E] = (P[E1|H] x P[E2|H] x P[E3|H] x P[E4|H] x P[H] ) / P[E]Replacing values from the table we get, P[yes|E] = (2/9 x 3/9 x 3/9 x 3/9 x 9/14) / P[E]P[E] will be taken care of during normalization of P[yes|E] and P[No|E] This method is called as Naïve Bayes](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-18-320.jpg)
![Problem and Solution for Naïve BayesProblem:In case we have an attribute value (Ea)for which P[Ea|H] = 0, then irrespective of other attributes P[H|E] = 0Solution:We can add a constant to numerator and denominator, a technique called Laplace Estimator for example, P1 + P2 + P3 = 1:](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-19-320.jpg)
![Statistical Modeling: Dealing with missing attributesIncase an value is missing, say for attribute Ea in the given data set, we just don’t count it while calculating the P[Ea|H]Incase an attribute is missing in the instance to be classified, then its factor is not there in the expression for P[H|E], for example if outlook is missing then we will have:Likelihood of Yes = 3/9 x 3/9 x 3/9 x 9/14 = 0.0238 Likelihood of No = 1/5 x 4/5 x 3/5 x 5/14 = 0.0343](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-20-320.jpg)


![Statistical Modeling: Dealing with numerical attributesSo here we have calculated the mean and standard deviation for numerical attributes like temperature and humidityFor temperature = 66So the contribution of temperature = 66 in P[yes|E] is 0.0340We do this similarly for other numerical attributes](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-23-320.jpg)




![Divide-and-Conquer: Constructing Decision TreesCalculations:Using the formulae for Information, initially we haveNumber of instances with class = Yes is 9 Number of instances with class = No is 5So we have P1 = 9/14 and P2 = 5/14Info[9/14, 5/14] = -9/14log(9/14) -5/14log(5/14) = 0.940 bitsNow for example lets consider Outlook attribute, we observe the following:](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-28-320.jpg)
![Divide-and-Conquer: Constructing Decision TreesExample Contd.Gain by using Outlook for division = info([9,5]) – info([2,3],[4,0],[3,2]) = 0.940 – 0.693 = 0.247 bitsGain (outlook) = 0.247 bits Gain (temperature) = 0.029 bits Gain (humidity) = 0.152 bits Gain (windy) = 0.048 bitsSo since Outlook gives maximum gain, we will use it for divisionAnd we repeat the steps for Outlook = Sunny and Rainy and stop for Overcast since we have Information = 0 for it](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-29-320.jpg)

![Divide-and-Conquer: Constructing Decision TreesHighly branching attributes: The problemInformation for such an attribute is 0info([0,1]) + info([0,1]) + info([0,1]) + …………. + info([0,1]) = 0It will hence have the maximum gain and will be chosen for branchingBut such an attribute is not good for predicting class of an unknown instance nor does it tells anything about the structure of divisionSo we use gain ratio to compensate for this](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-31-320.jpg)
![Divide-and-Conquer: Constructing Decision TreesHighly branching attributes: Gain ratioGain ratio = gain/split infoTo calculate split info, for each instance value we just consider the number of instances covered by each attribute value, irrespective of the classThen we calculate the split info, so for identification code with 14 different values we have:info([1,1,1,…..,1]) = -1/14 x log1/14 x 14 = 3.807For Outlook we will have the split info:info([5,4,5]) = -1/5 x log 1/5 -1/4 x log1/4 -1/5 x log 1/5 = 1.577](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-32-320.jpg)



























![Linear modelsLinear classification: Logistic regressionTo get the output as proper probabilities in the range 0 to 1 we use logistic regressionHere the output y is defined as: y = 1/(1+e^(-x))x = (w0) + (w1)x(a1) + (w2)x(a2) + …… + (wk)x(ak)So the output y will lie in the range (0,1]](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-60-320.jpg)





![Instance-based learningNormalization of data:We normalize attributes such that they lie in the range [0,1], by using the formulae:Missing attributes:In case of nominal attributes, if any of the two attributes are missing or if the attributes are different, the distance is taken as 1 In nominal attributes, if both are missing than difference is 1. If only one attribute is missing than the difference is the either the normalized value of given attribute or one minus that size, which ever is bigger](https://image.slidesharecdn.com/algorithmsthebasicmethods-100203234917-phpapp01/85/WEKA-Algorithms-The-Basic-Methods-66-320.jpg)









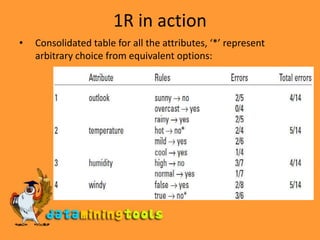
1) The 1R algorithm generates a one-level decision tree by considering each attribute individually and assigning the majority class to each branch. It chooses the attribute with the minimum classification error. 2) Naive Bayes classification assumes attributes are independent and calculates the probability of each class using Bayes' rule. It handles missing and numeric attributes. 3) Decision tree algorithms like ID3 use a divide-and-conquer approach, recursively splitting the data on attributes that maximize information gain or gain ratio at each node. 4) Rule-based algorithms like PRISM generate rules to cover instances of each class sequentially, maximizing the ratio of correctly covered to total covered instances at each step.

































































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)








































