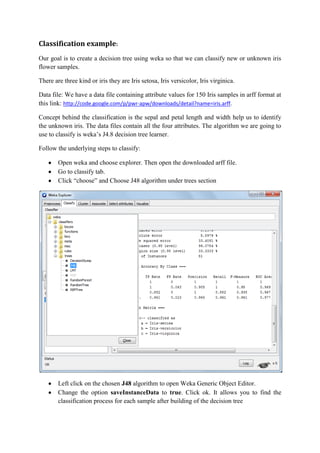
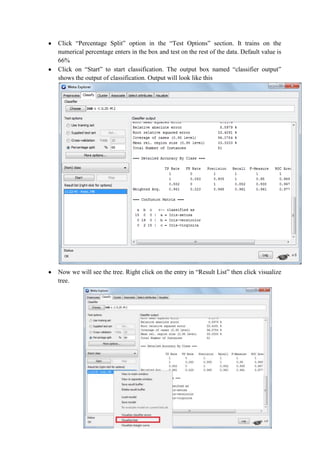
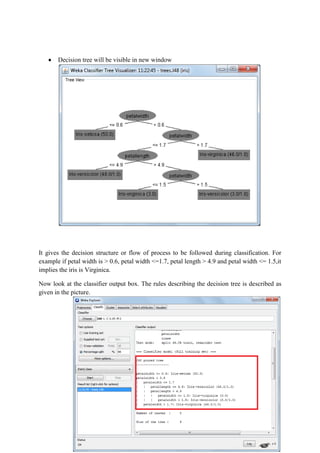
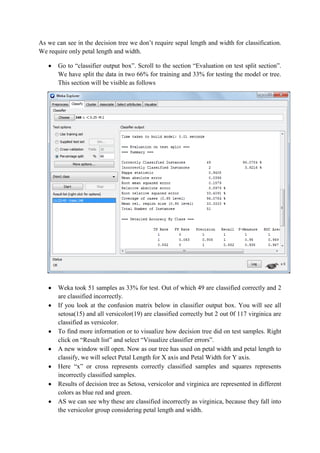
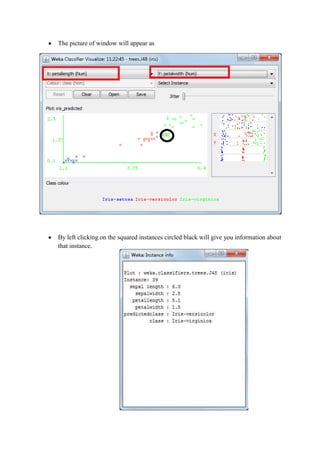
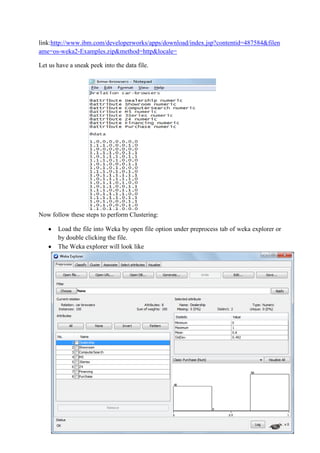
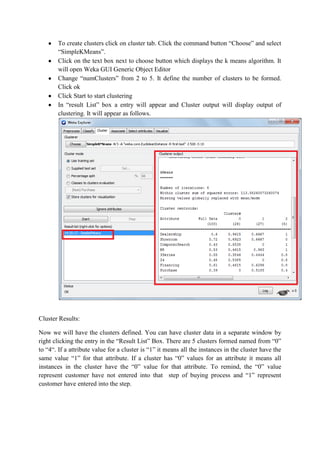
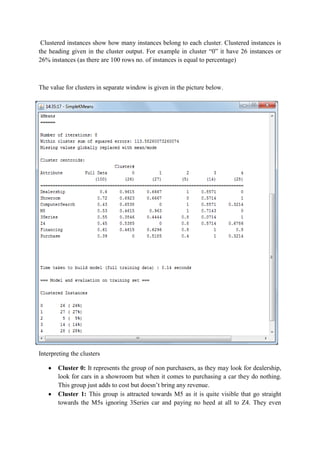
This document discusses classification and clustering techniques using the Weka data mining tool. It begins with an introduction to Weka and its capabilities for classification, clustering, and other data mining functions. It then provides an example of using Weka's J48 decision tree algorithm to classify iris flower samples based on sepal and petal attributes. Finally, it demonstrates k-means clustering on customer purchase data from a BMW dealership to group customers into five clusters based on their buying behaviors.






![REFERENCES
[1] Data mining by Jan H. witten, Eibe Frank and Mark A. Hall, 3rd edition, Morgan
Kaufman Publisher
[2]Tutorial for weka provided by university of Waikato, www.cs.waikato.ac.nz/ml/weka/
[3] Weka,Classification using decision trees based on Dr. Polczynski's Lecture, written by
Prof. Andrzej Kochanski and Prof Marcin Perzyk, Faculty of Production Engineering,
Warsaw University of Technology, Warsaw Poland,
http://referensi.dosen.narotama.ac.id/files/2011/12/weka-tutorial-2.pdf
[4] Classification via Decision Trees in WEKA, Computer science, Telecommunications, and
Information systems, DePaul University,
http://maya.cs.depaul.edu/classes/ect584/weka/classify.html
[5] Data mining with WEKA, Part 2: classification and clustering, IBM developer works
Michael Abernethy, http://www.ibm.com/developerworks/opensource/library/os-
weka2/index.html?ca=drs-](https://image.slidesharecdn.com/dataminingtechniquesusingweka-120417052341-phpapp01/85/Data-mining-techniques-using-weka-14-320.jpg)























































































