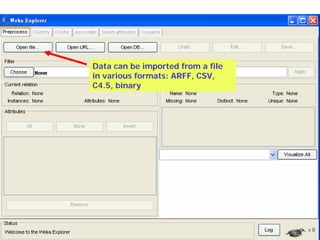
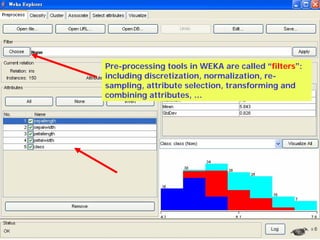
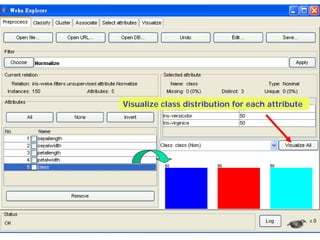
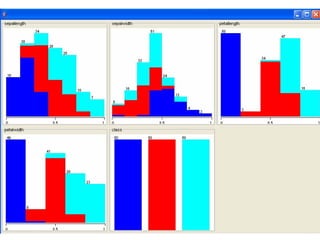
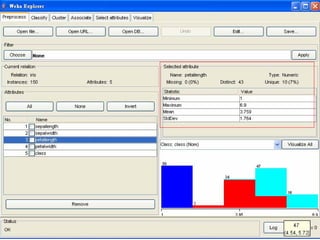
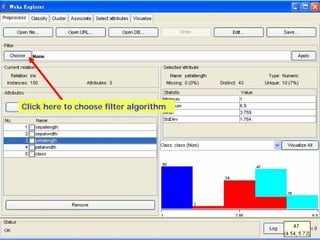
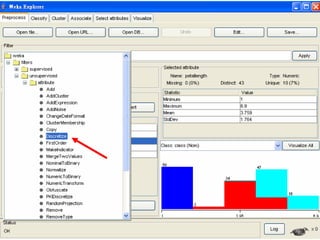
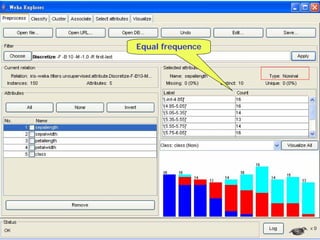
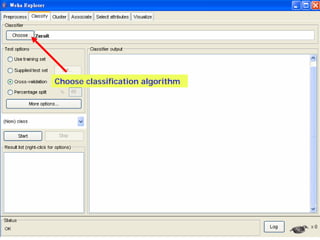
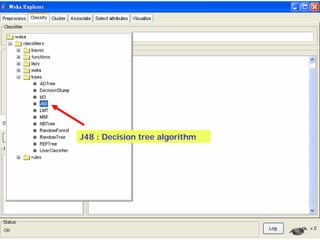
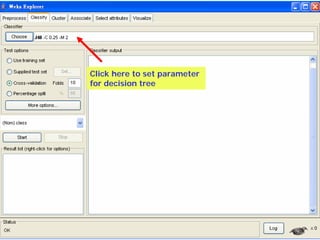
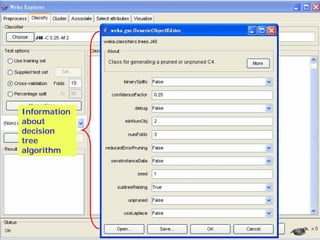
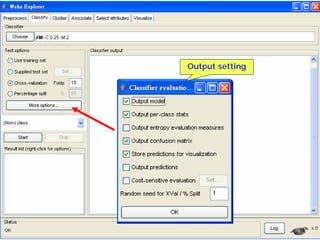
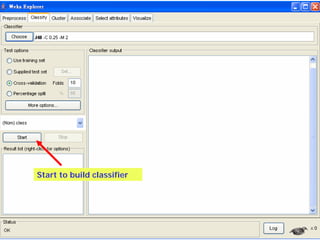
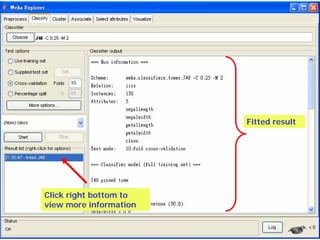
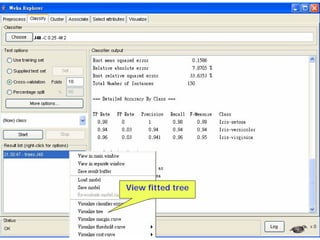
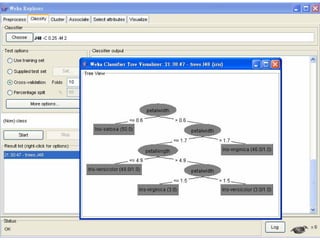
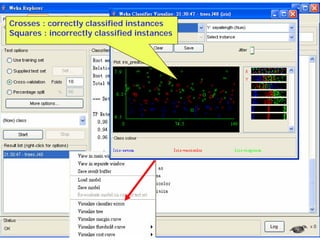
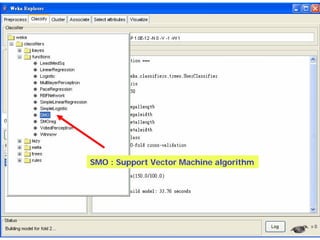
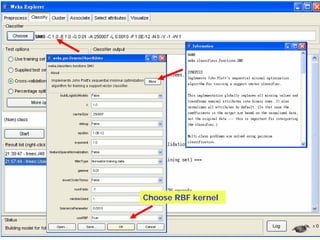
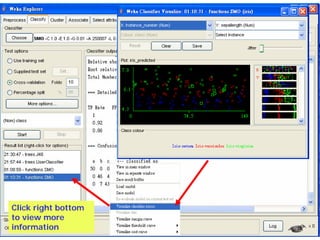
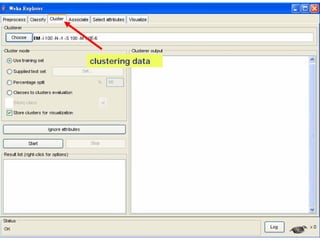
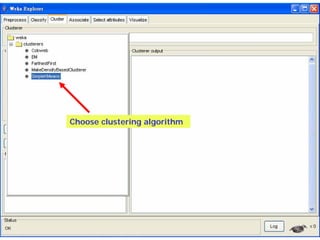
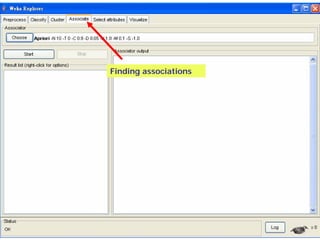
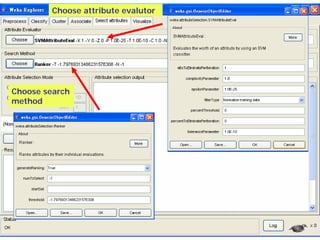
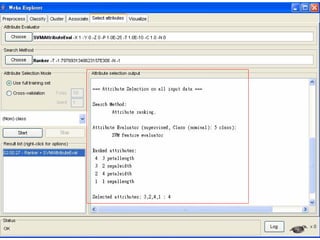
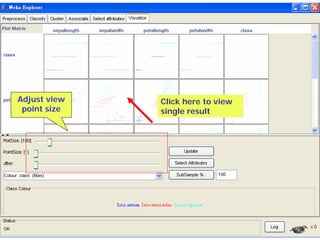
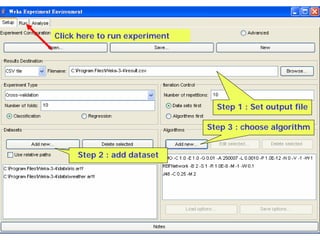
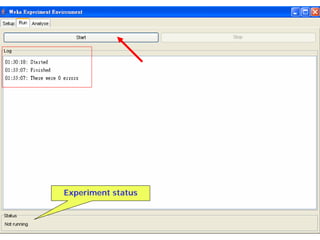
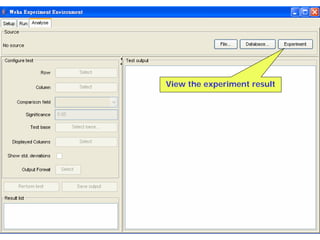
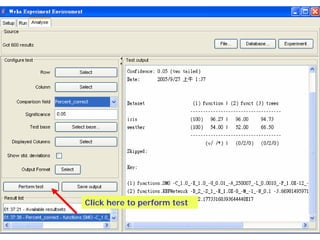
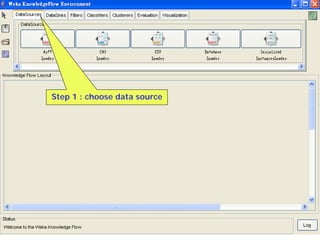
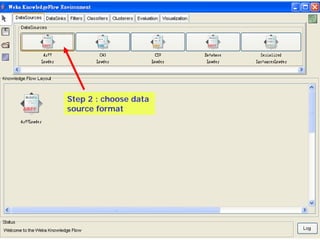
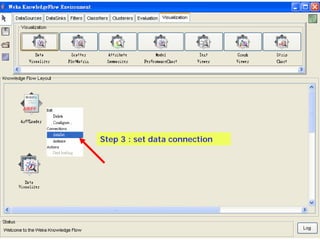
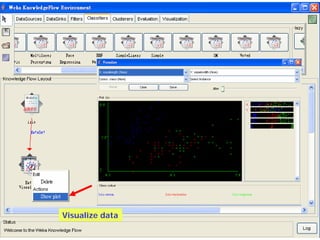
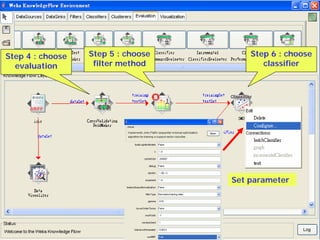
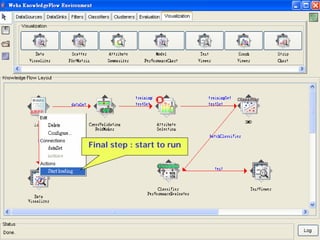
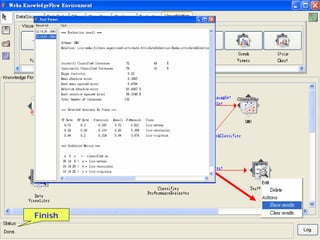
This document provides an overview of the machine learning workbench WEKA. It describes how WEKA can be used to import and preprocess data, build classifiers and clustering models, perform attribute selection and data visualization, and run experiments. Key capabilities mentioned include importing data from various formats, using filters for preprocessing, implementing various learning algorithms like decision trees and SVMs, clustering algorithms, association rule learning, attribute selection methods, and the experimenter for comparing models. The Knowledge Flow GUI is also introduced as a graphical interface in WEKA.







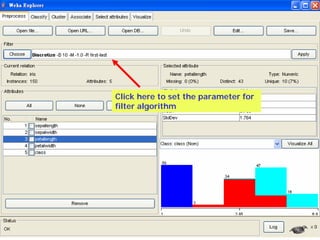
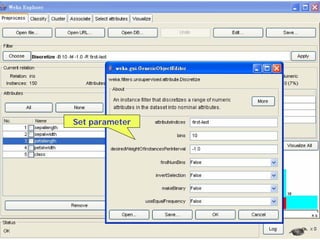
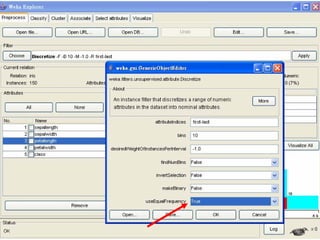
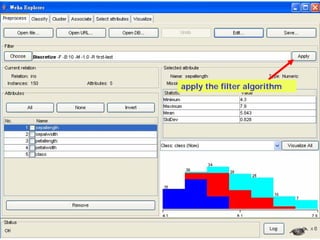































































![Microsoft PowerPoint - weka [Read-Only]](https://cdn.slidesharecdn.com/ss_thumbnails/microsoft-powerpoint-weka-readonly3765-thumbnail.jpg?width=640&height=640&fit=bounds)
























