Downloaded 294 times







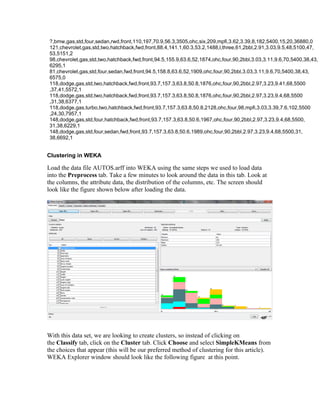
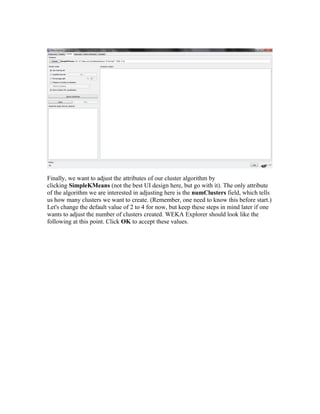
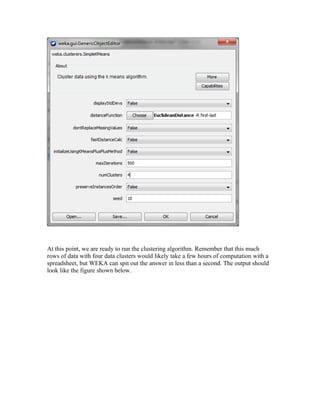








The document discusses using the WEKA data mining tool to perform clustering and linear regression analysis on an automotive dataset. It describes loading the dataset into WEKA's Explorer interface and preprocessing the data. For clustering, it uses the SimpleKMeans algorithm to cluster the data into 4 groups. For linear regression, it predicts normalized losses using attribute values as predictors. The document provides an overview of the key steps and features used in WEKA for these common data mining techniques.



































































