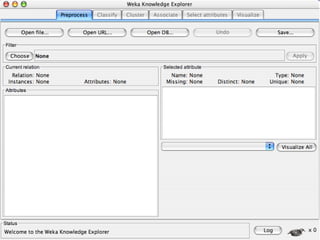
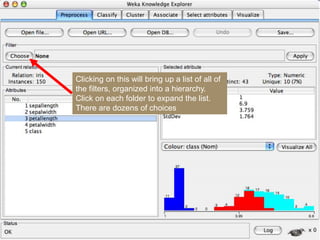
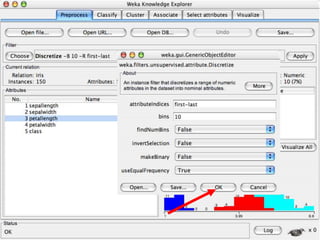
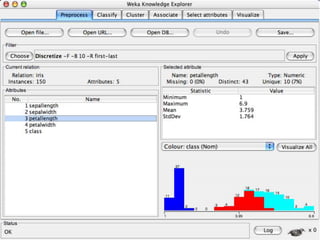
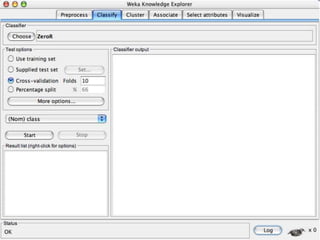
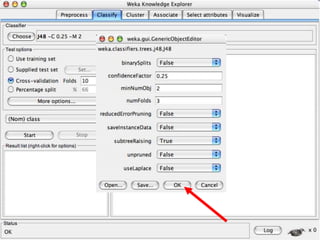
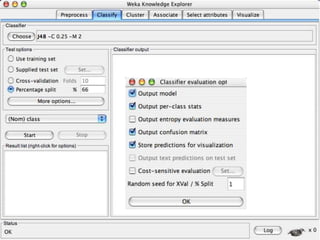
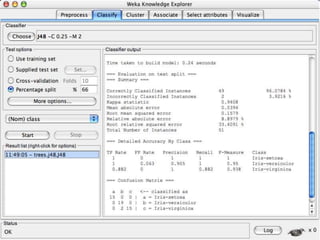
This document provides an introduction to WEKA, an open-source data mining and machine learning toolkit. It discusses installing WEKA and exploring its features, including preprocessing data, classification, clustering, association rule mining, attribute selection, and data visualization. The main interface is the Explorer, which allows applying preprocessing filters and building classifiers without programming. The document provides examples of using various WEKA tools and functions on sample datasets.





















































































































![Microsoft PowerPoint - weka [Read-Only]](https://cdn.slidesharecdn.com/ss_thumbnails/microsoft-powerpoint-weka-readonly3765-thumbnail.jpg?width=640&height=640&fit=bounds)





















