






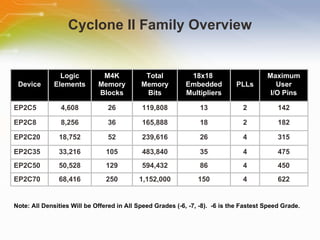


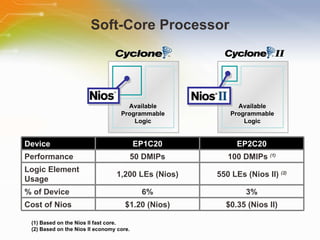

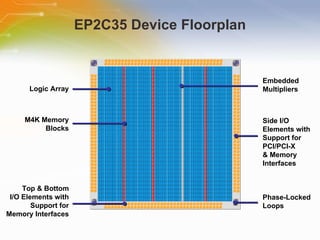

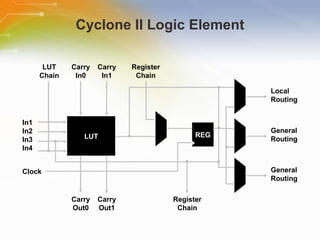
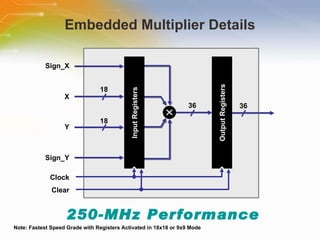

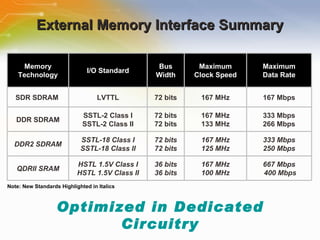

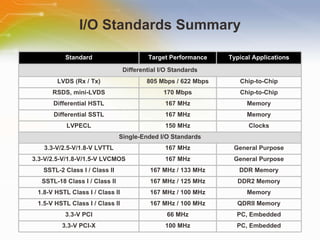
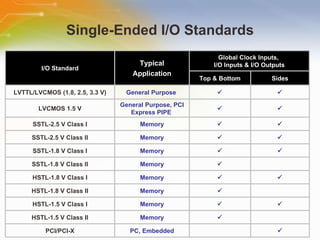
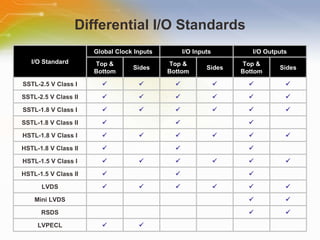




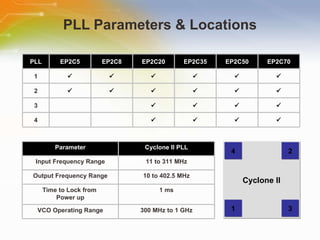

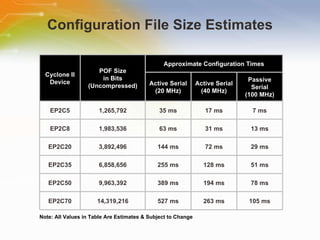


The document provides an overview of the Cyclone II FPGA family from Altera, detailing their features, design capabilities, and applications. It emphasizes the advantages of FPGA technology in customization and cost-effectiveness compared to ASICs, while highlighting the high performance and low power consumption of the Cyclone II devices. Additionally, it includes specifications on device capabilities, packaging options, and embedded processors, along with support for various I/O standards.











































































































