Downloaded 151 times







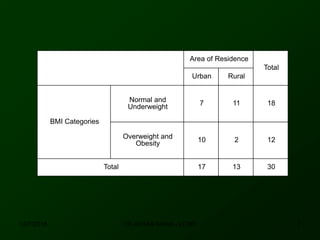









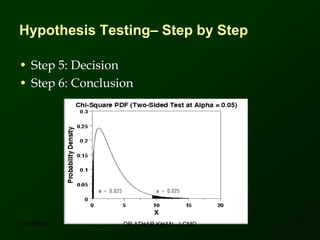
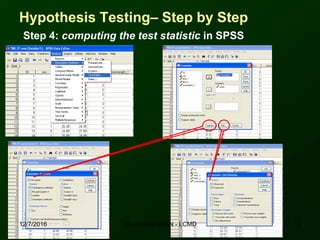


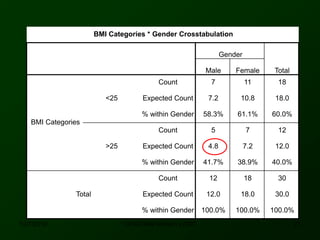
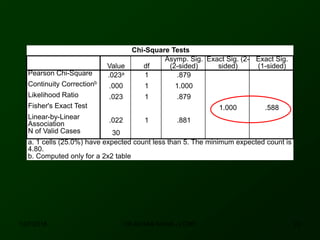

This document discusses using SPSS to conduct a chi-square test of independence. It provides an example of testing whether there is an association between area of residence (urban vs. rural) and BMI categories (normal weight vs. overweight/obese). The chi-square test involves stating hypotheses, calculating expected and observed frequencies, computing the test statistic in SPSS, and making a decision. No significant relationship was found between gender and BMI categories in another example exercise.








































































































![PERI-PROSTHETIC FRACTURE NAIL-PLATE CONSTRUCT [NPC].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/drarunkumardrmohamedashrafperiprostheticfrasturenail-plateconstructnpc-260209164459-7e9d15a1-thumbnail.jpg?width=640&height=640&fit=bounds)

