Download as PDF, PPTX







![ปริมาณ
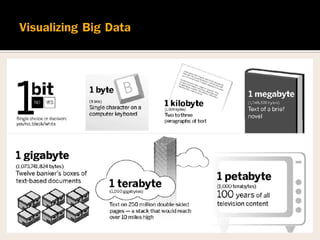
ปริมาณของข้อมูล เพิ่มขึ้ นอย่างรวดเร็วตั้งแต่ปี 2004 โดยในปี 2004
จานวนของข้อมูลที่เก็บไว้บนอินเทอร์เน็ตมีทั้งหมด 1 petabyte (1,000
terabytes) เทียบเท่ากับ 100 ปี ของเนื้ อหาโทรทัศน์ทั้งหมด
ในปี 2011 จานวนรวมของข้อมูลทั่วโลกที่เก็บไว้ด้วยระบบอิเล็กทรอนิกส์
คือ 1 Zettabyte (1,000,000 petabytes หรือ 36 ล้านปี ของวิดีโอความ
ละเอียดสูง [HD]) โดยในปี 2015 ตัวเลขคาดว่าจะถึง 7.9 zettabytes (หรือ
7,900,000 petabytes)
ขนาดของชุดข้อมูลที่มีการใช้งานอย่างต่อเนื่อง มีการเจริญเติบโตแซงหน้า
ความสามารถของเครื่องมือแบบดั้งเดิม ในการบันทึก จัดเก็บ จัดการ และ
วิเคราะห์ข้อมูล](https://image.slidesharecdn.com/bigdata-150709152308-lva1-app6892/85/Big-data-8-320.jpg)
















ข้อมูลขนาดใหญ่ ทุกวันนี้ มีการหารือถึงความสำคัญที่เพิ่มขึ้นและเร่งด่วน ของ "ข้อมูลขนาดใหญ่" (Big Data) ในห้องประชุมคณะกรรมการบริหาร การประชุมเชิงกลยุทธ์ และการดำเนินงานอื่น ๆ ขององค์กรทั่วโลก มีข้อสังเกตว่า ผู้บริหาร ผู้จัดการ และที่ปรึกษา อาจจะมีความเข้าใจที่แตกต่างกันมาก ในสิ่งที่เป็นข้อมูลขนาดใหญ่ เมื่อเทียบกับนักเทคโนโลยีและนักวิทยาศาสตร์ข้อมูล ที่อยู่ในองค์กรของพวกเขา ความเข้าใจที่แตกต่างกันเหล่านี้ มาจากการขาดคำนิยามที่ได้รับการยอมรับของข้อมูลขนาดใหญ่ ทำให้เกิดความเข้าใจร่วมกันน้อยมากระหว่างผู้บริหาร ผู้จัดการ และที่ปรึกษา ที่ไม่ได้มีส่วนเกี่ยวข้องกับเทคโนโลยีการทำงานของข้อมูลขนาดใหญ่ในชีวิตประจำวัน บทความนี้ เป็นการอธิบายคำว่า ข้อมูลขนาดใหญ่ (Big Data) ในภาษาคนธรรมดา (จากมุมมองของคนไม่มีความรู้ด้านเทคนิค) ถึงลักษณะที่แตกต่างจากข้อมูลขนาดใหญ่ กับรูปแบบฐานข้อมูลแบบดั้งเดิม ว่า 1. อะไรคือข้อมูลขนาดใหญ่? และลักษณะของข้อมูลขนาดใหญ่ (ปริมาณ ความแตกต่าง ความเร็ว และการตรวจสอบ) 2. แนวคิดการทำงานข้ามสายงาน ทักษะใหม่ และการลงทุน 3. วิธีการแสวงหาข้อมูลที่เกี่ยวข้อง 4. พื้นฐานของการทำงานด้านเทคโนโลยีของข้อมูลขนาดใหญ่ Big Data: A Business and Legal Guide James R. Kalyvas and Michael R. Overly CRC Press, 2015







































































![10. สมุททกสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ].docx](https://cdn.slidesharecdn.com/ss_thumbnails/10-250914134055-45782608-thumbnail.jpg?width=640&height=640&fit=bounds)
![21. ฆัตวาสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ].docx](https://cdn.slidesharecdn.com/ss_thumbnails/21-250915142508-0fee33dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![15. รามเณยยกสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ]....](https://cdn.slidesharecdn.com/ss_thumbnails/15-250914134958-32f78cef-thumbnail.jpg?width=640&height=640&fit=bounds)
![11. ปฐมเทวสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ].docx](https://cdn.slidesharecdn.com/ss_thumbnails/11-250914134242-8f41b43b-thumbnail.jpg?width=640&height=640&fit=bounds)
![14. ทฬิททสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ].docx](https://cdn.slidesharecdn.com/ss_thumbnails/14-250914134808-b1864751-thumbnail.jpg?width=640&height=640&fit=bounds)
![16. ยชมานสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ].docx](https://cdn.slidesharecdn.com/ss_thumbnails/16-250915140947-2b3e1077-thumbnail.jpg?width=640&height=640&fit=bounds)
![24. อัจจยสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ].docx](https://cdn.slidesharecdn.com/ss_thumbnails/24-250916141141-50005481-thumbnail.jpg?width=640&height=640&fit=bounds)
![22. ทุพพัณณิยสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ]...](https://cdn.slidesharecdn.com/ss_thumbnails/22-250915142706-5bff2ba3-thumbnail.jpg?width=640&height=640&fit=bounds)
![09. อารัญญกสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ].docx](https://cdn.slidesharecdn.com/ss_thumbnails/09-250914133914-d37b0f6e-thumbnail.jpg?width=640&height=640&fit=bounds)
![13. ตติยเทวสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ].docx](https://cdn.slidesharecdn.com/ss_thumbnails/13-250914134616-e0628736-thumbnail.jpg?width=640&height=640&fit=bounds)
![25. อักโกธสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ].docx](https://cdn.slidesharecdn.com/ss_thumbnails/25-250916141407-e2e334a5-thumbnail.jpg?width=640&height=640&fit=bounds)



![12. ทุติยเทวสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ]....](https://cdn.slidesharecdn.com/ss_thumbnails/12-250914134430-e99e23fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![17. วันทนาสูตร พระไตรปิฎกเล่มที่ ๑๕ พระสุตตันตปิฎกเล่มที่ ๗ [ฉบับมหาจุฬาฯ].docx](https://cdn.slidesharecdn.com/ss_thumbnails/17-250915141136-db1fe528-thumbnail.jpg?width=640&height=640&fit=bounds)