Downloaded 85 times


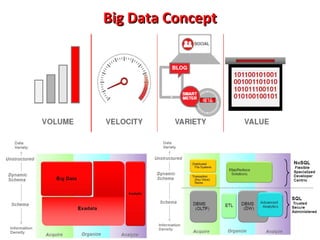
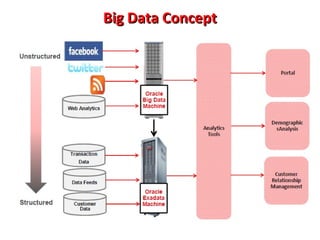
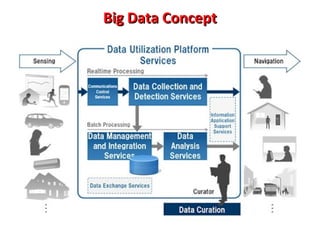
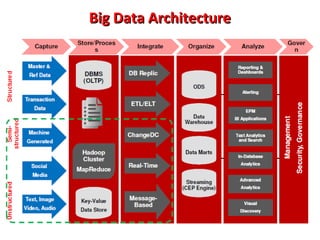
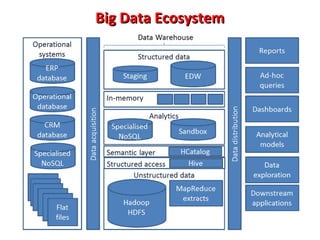
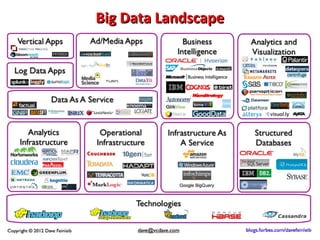
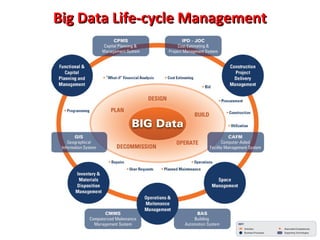
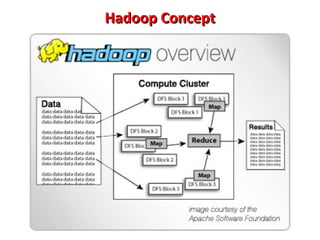
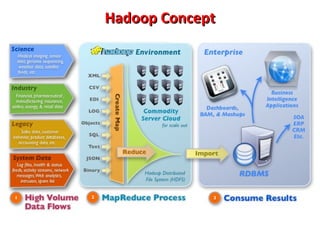
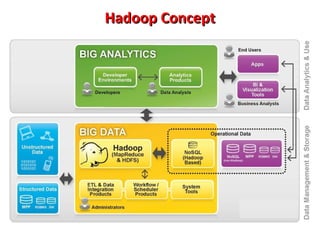
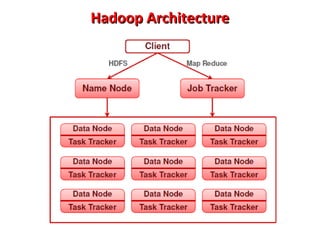
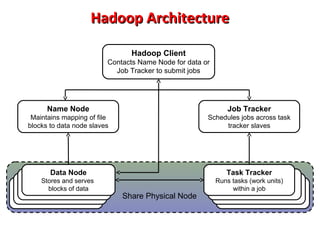

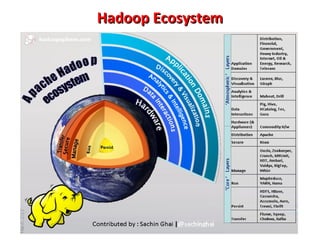
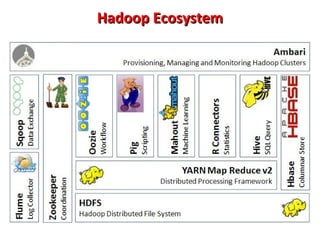
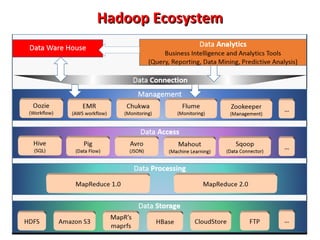


This document provides an overview of big data and Hadoop. It introduces big data concepts and architectures, describes the Hadoop ecosystem including its core components of HDFS and MapReduce. It also provides an example of how MapReduce works for a word count problem, splitting the documents, mapping to count word frequencies, and reducing to sum the counts. The document aims to give the reader an understanding of big data and how Hadoop is used for distributed storage and processing of large datasets.

































![[4차]왓챠 알고리즘 분석(151106)](https://cdn.slidesharecdn.com/ss_thumbnails/4-151106-160217170557-thumbnail.jpg?width=640&height=640&fit=bounds)
![[4차]넷플릭스 알고리즘 분석(151106)](https://cdn.slidesharecdn.com/ss_thumbnails/4-151106-160217170441-thumbnail.jpg?width=640&height=640&fit=bounds)










































![Technology Management and Strategy [Part IV]](https://cdn.slidesharecdn.com/ss_thumbnails/technologymanagementandstrategypartiv-140803030243-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















