Downloaded 107 times










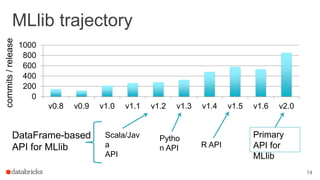





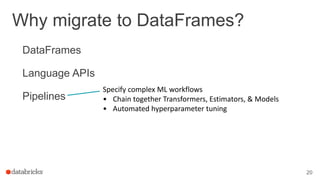



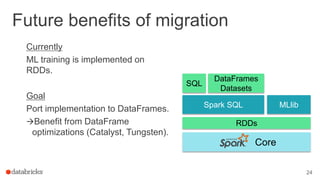
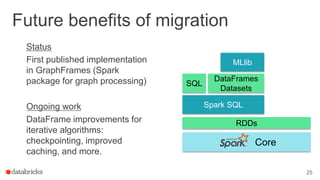

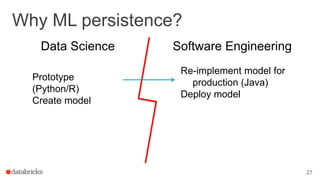
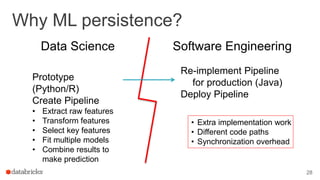
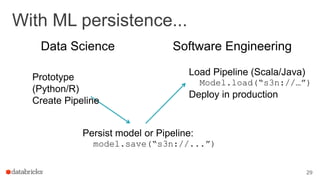
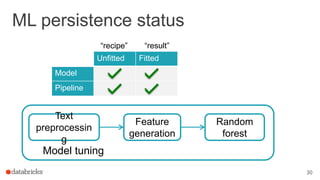


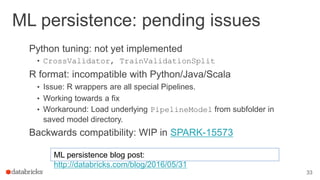







This document outlines a webinar featuring speakers Joseph Bradley and Jules S. Damji, who are experts in machine learning and Apache Spark. It covers the evolution of MLlib within Spark, including the migration from RDD-based APIs to DataFrame-based APIs and the implementation of machine learning pipelines. The document also highlights the future benefits of using DataFrames and the importance of model persistence within the Spark ecosystem.











































































































