Downloaded 75 times


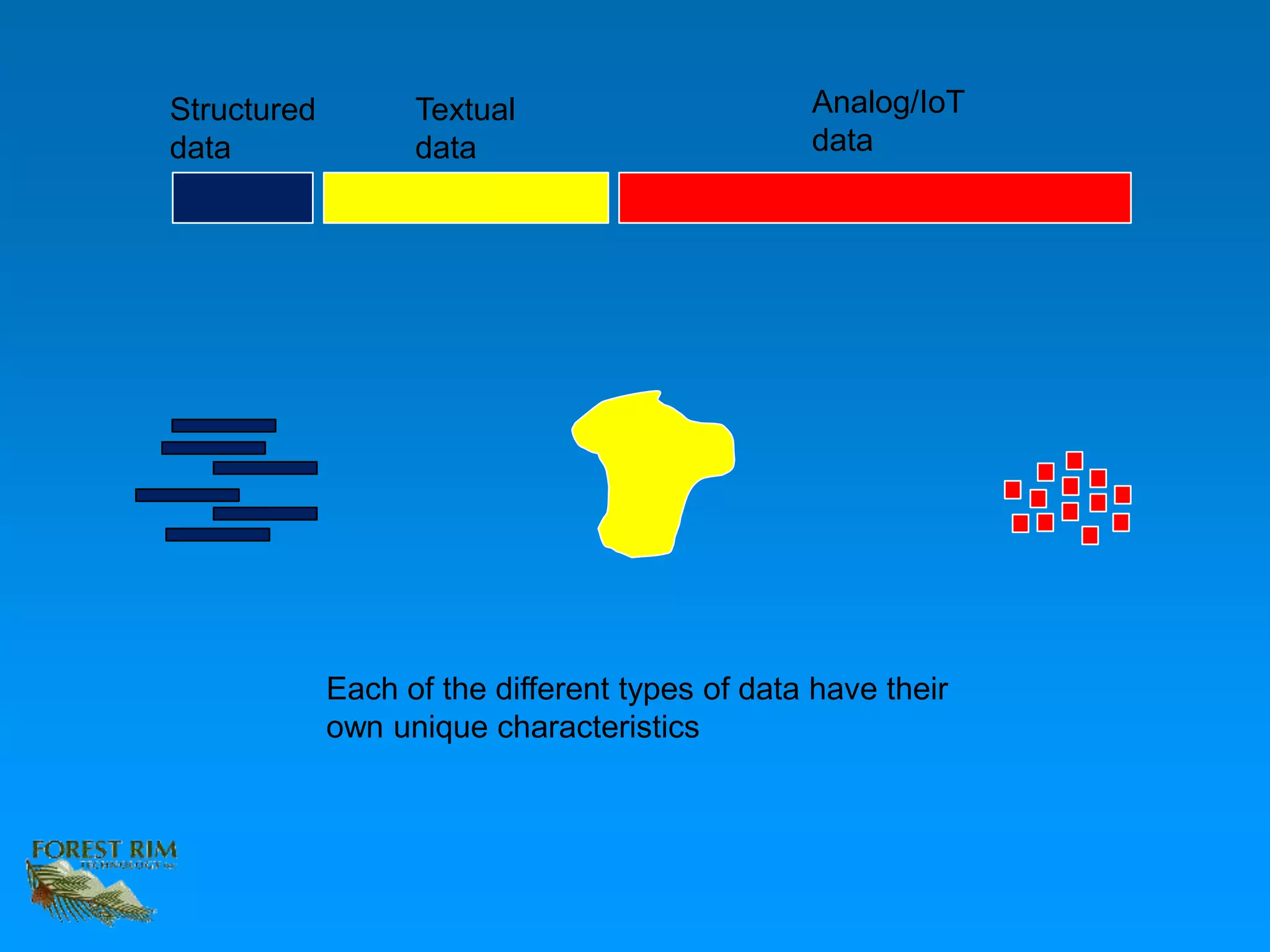
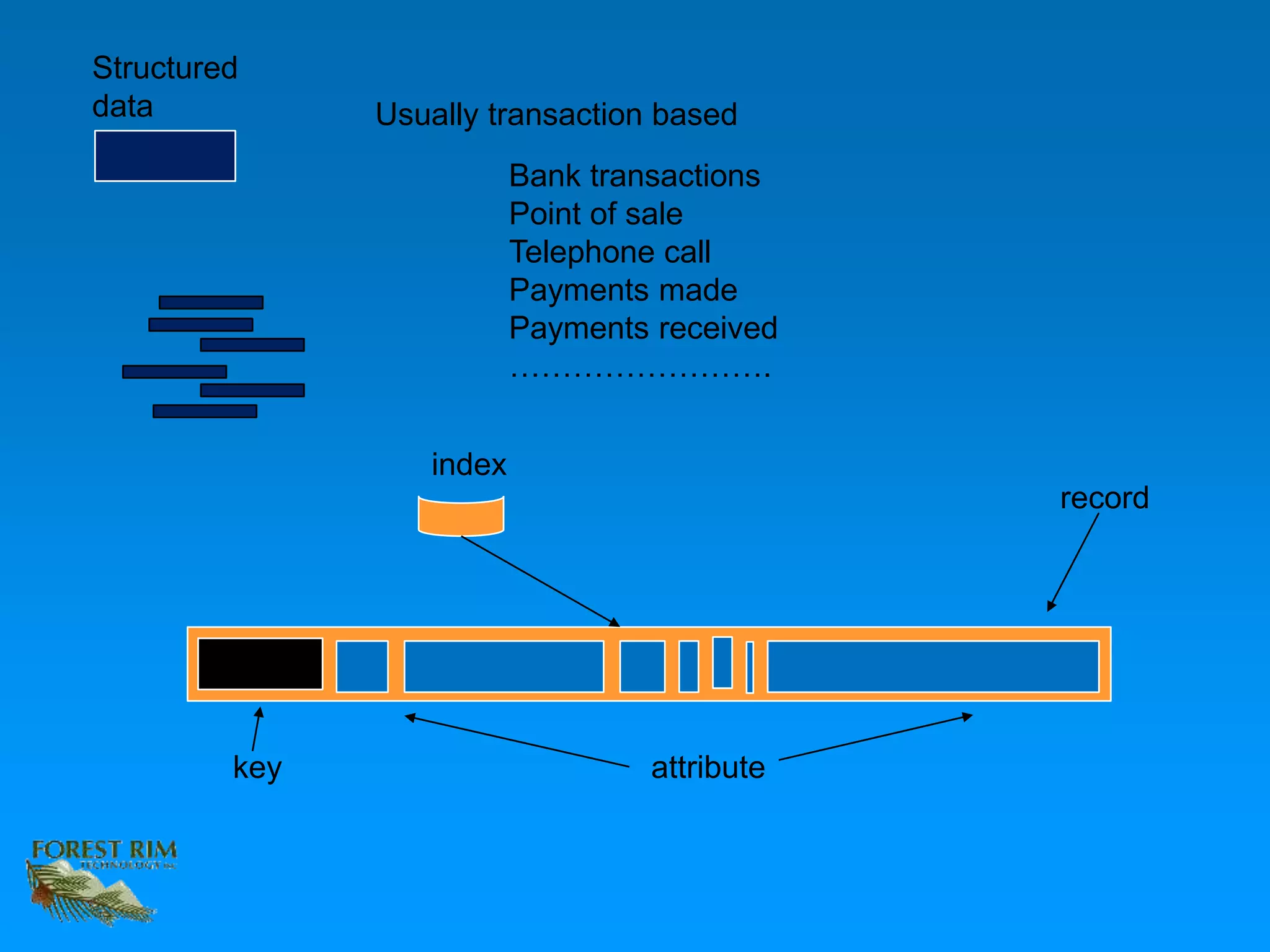


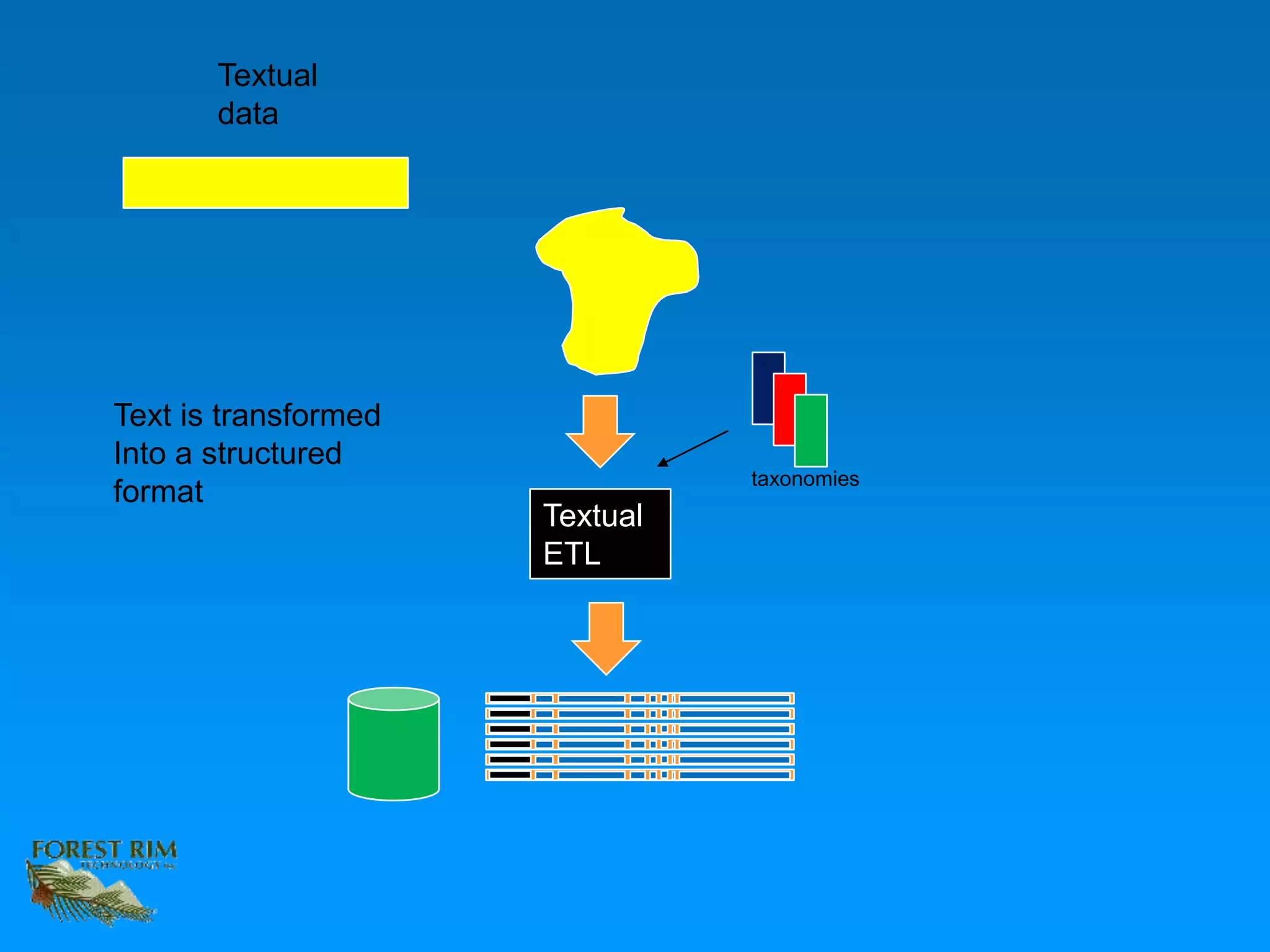
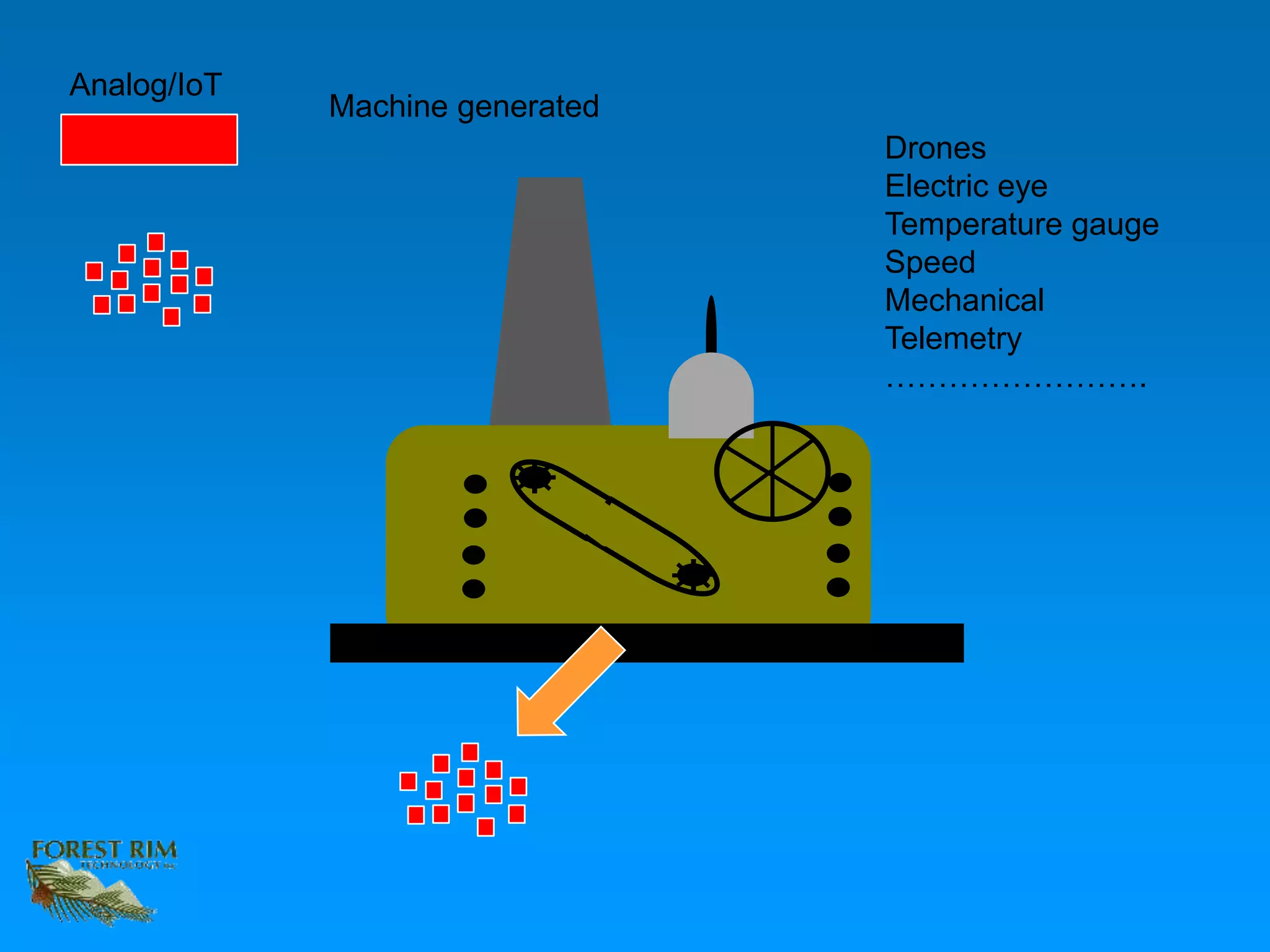

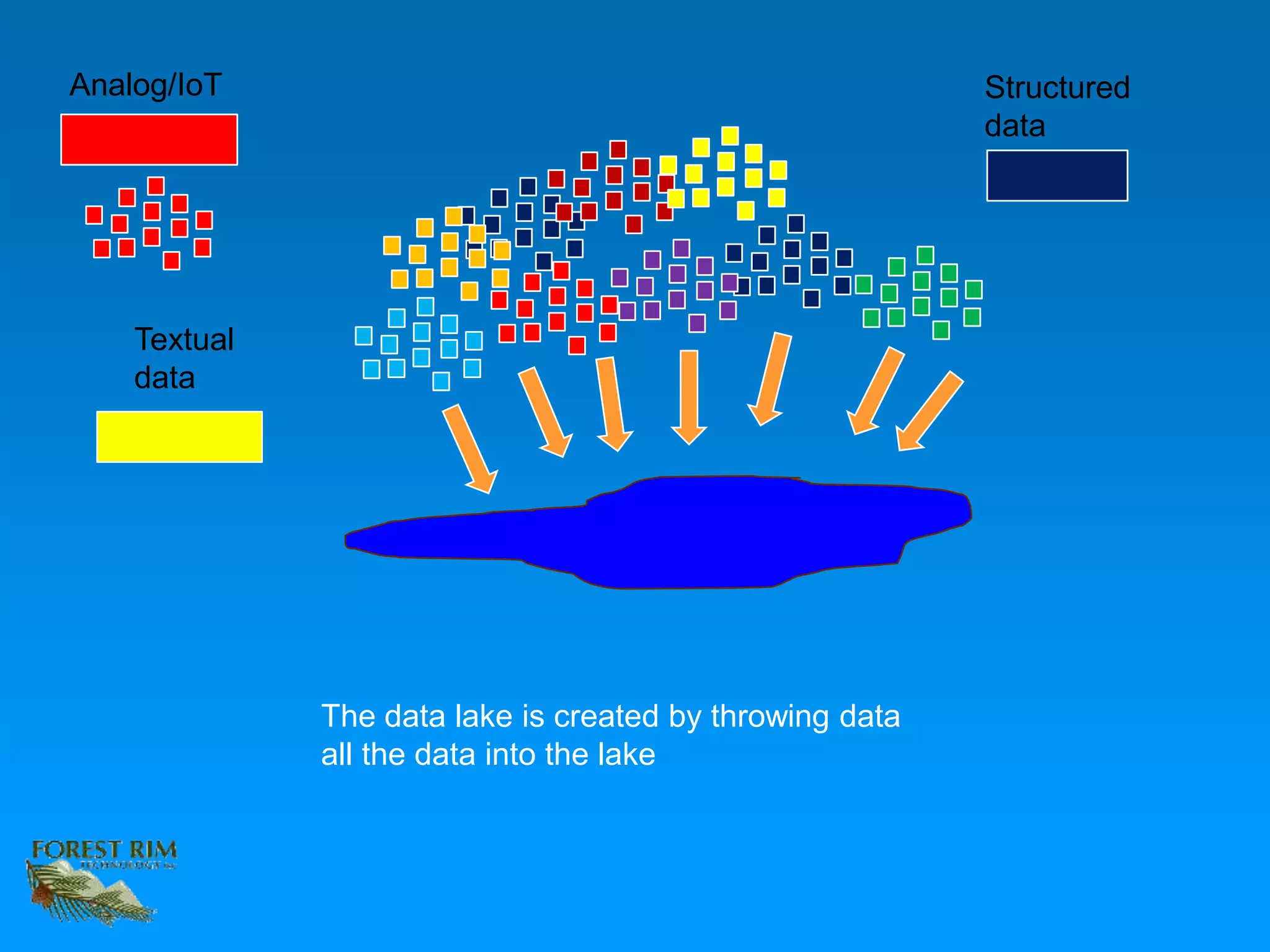




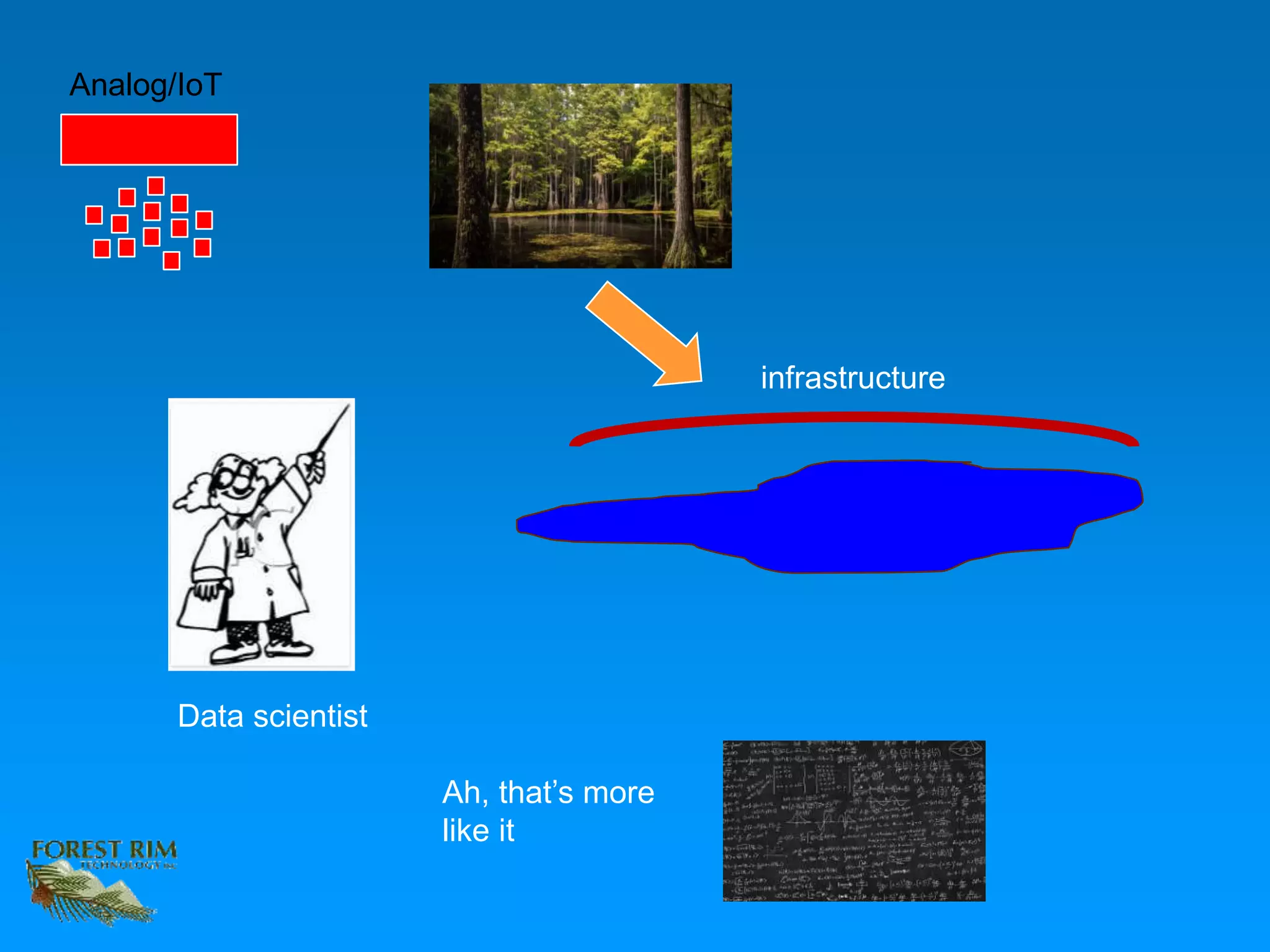
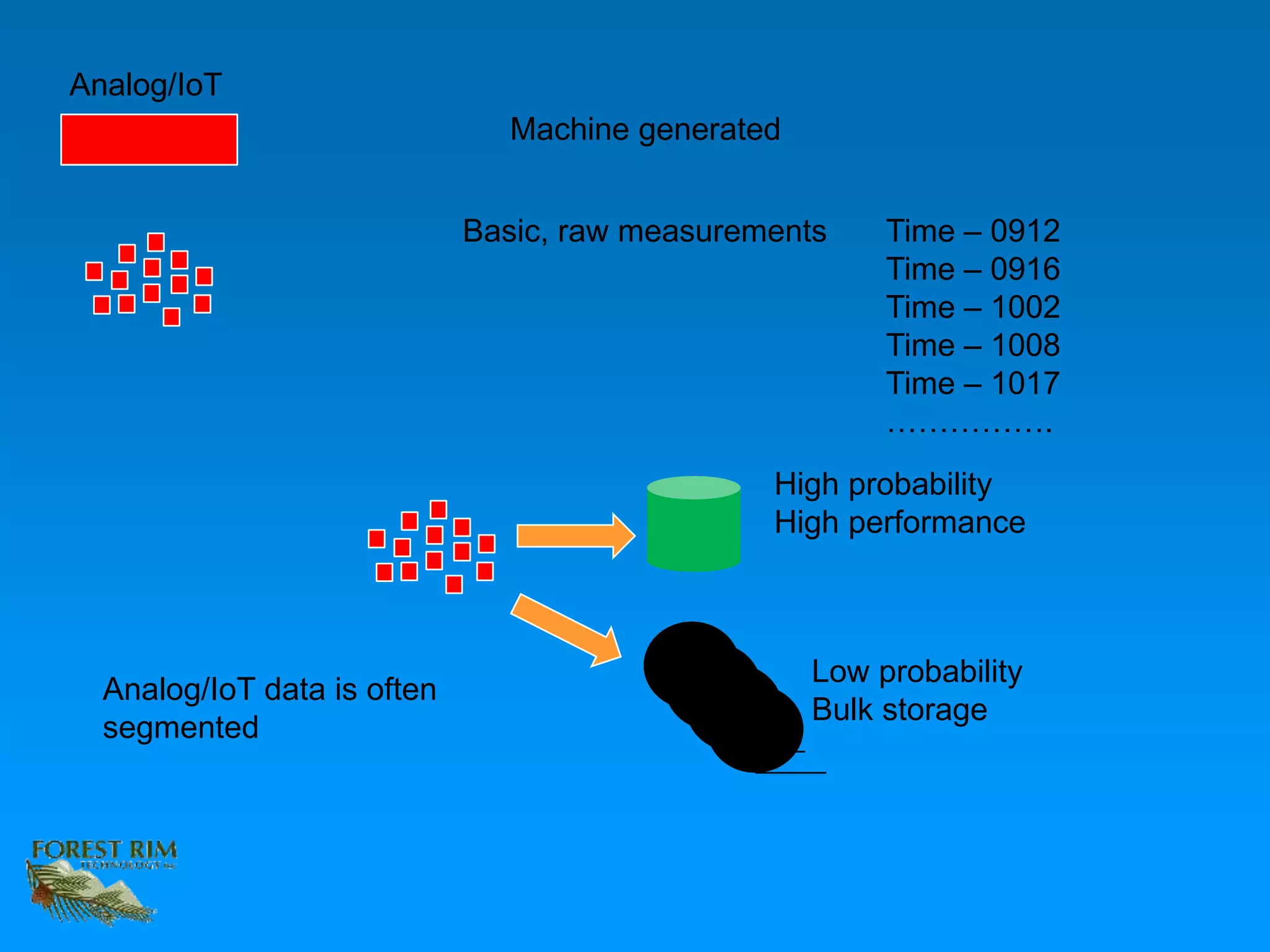
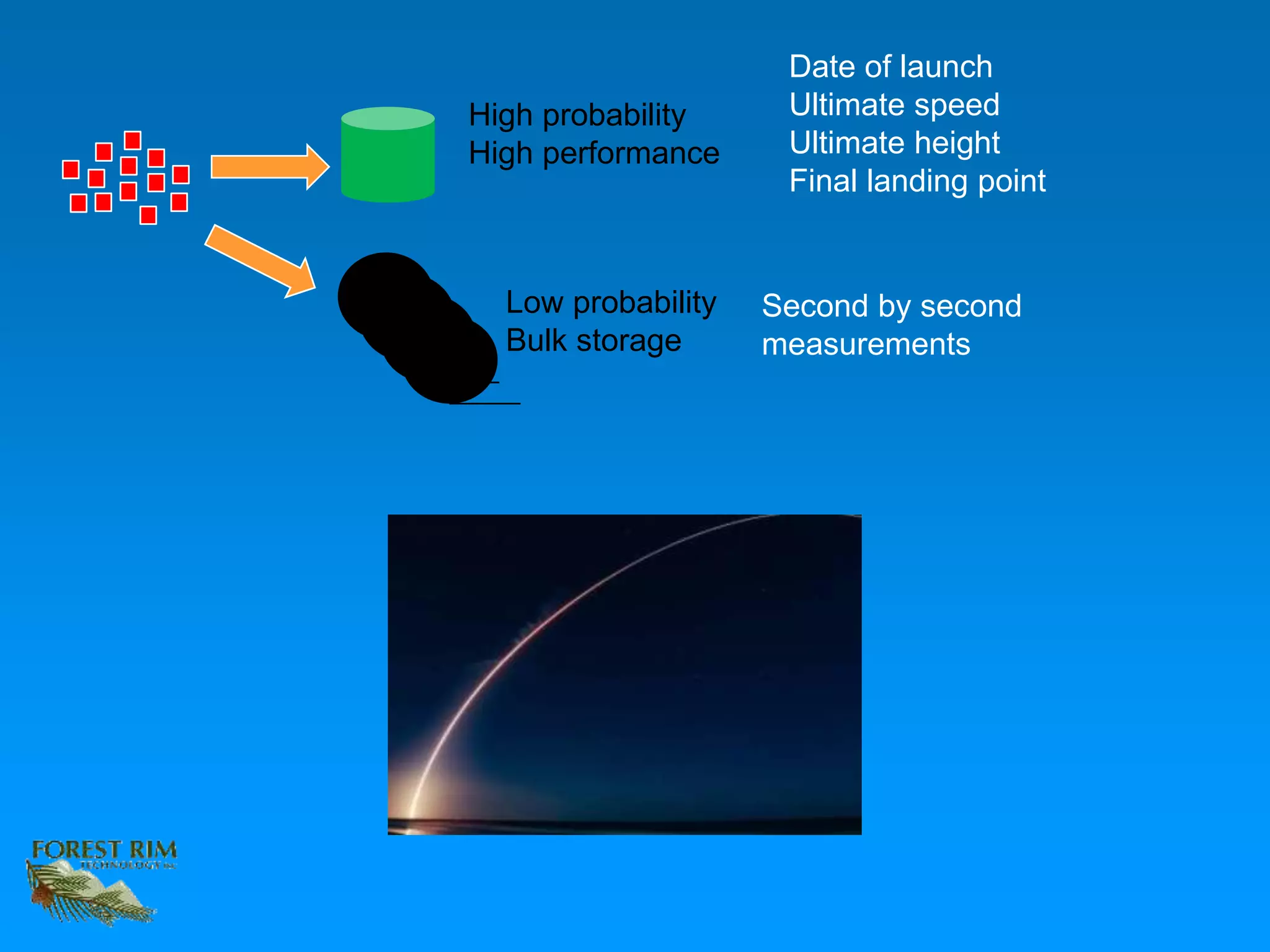

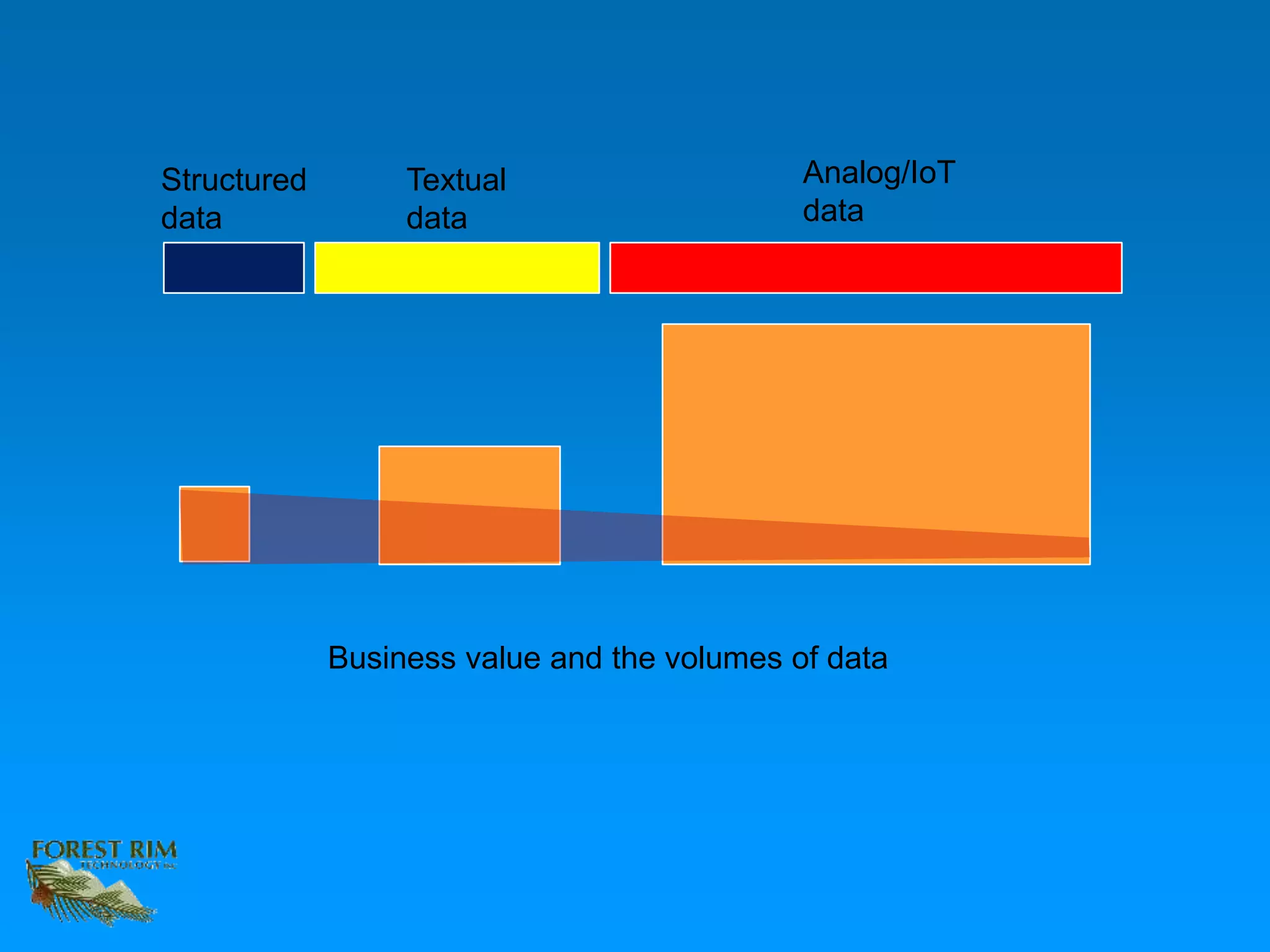
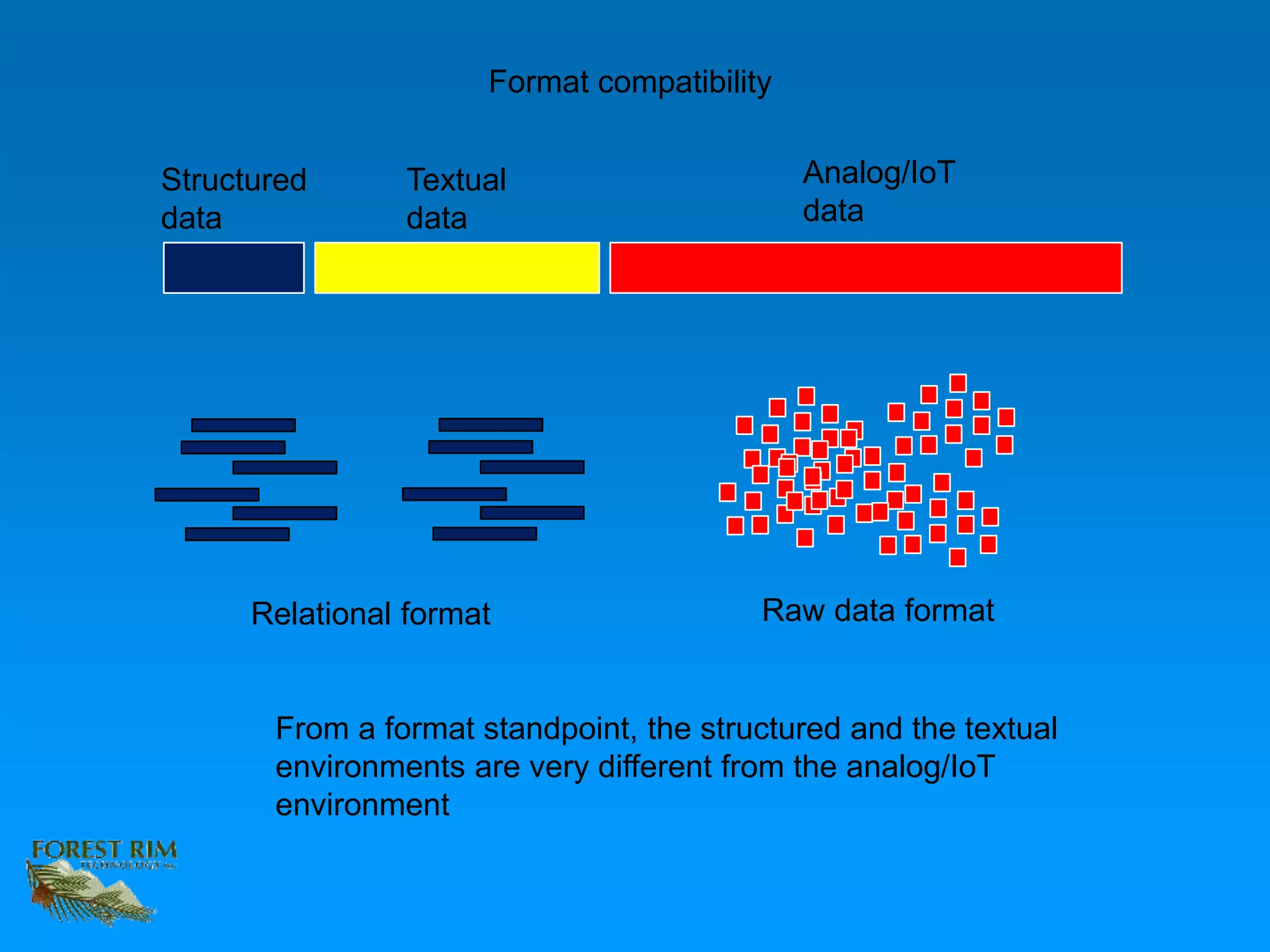
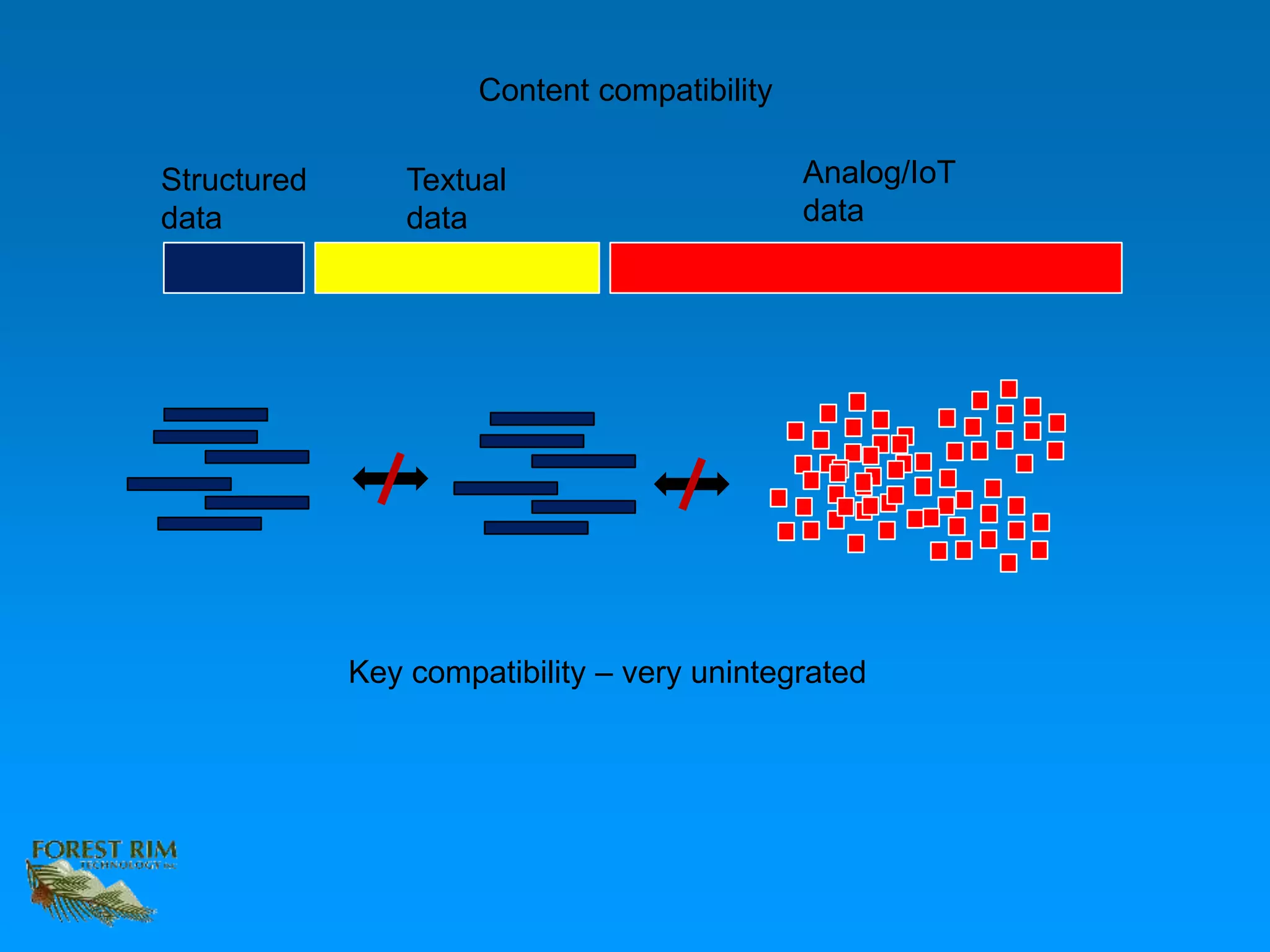


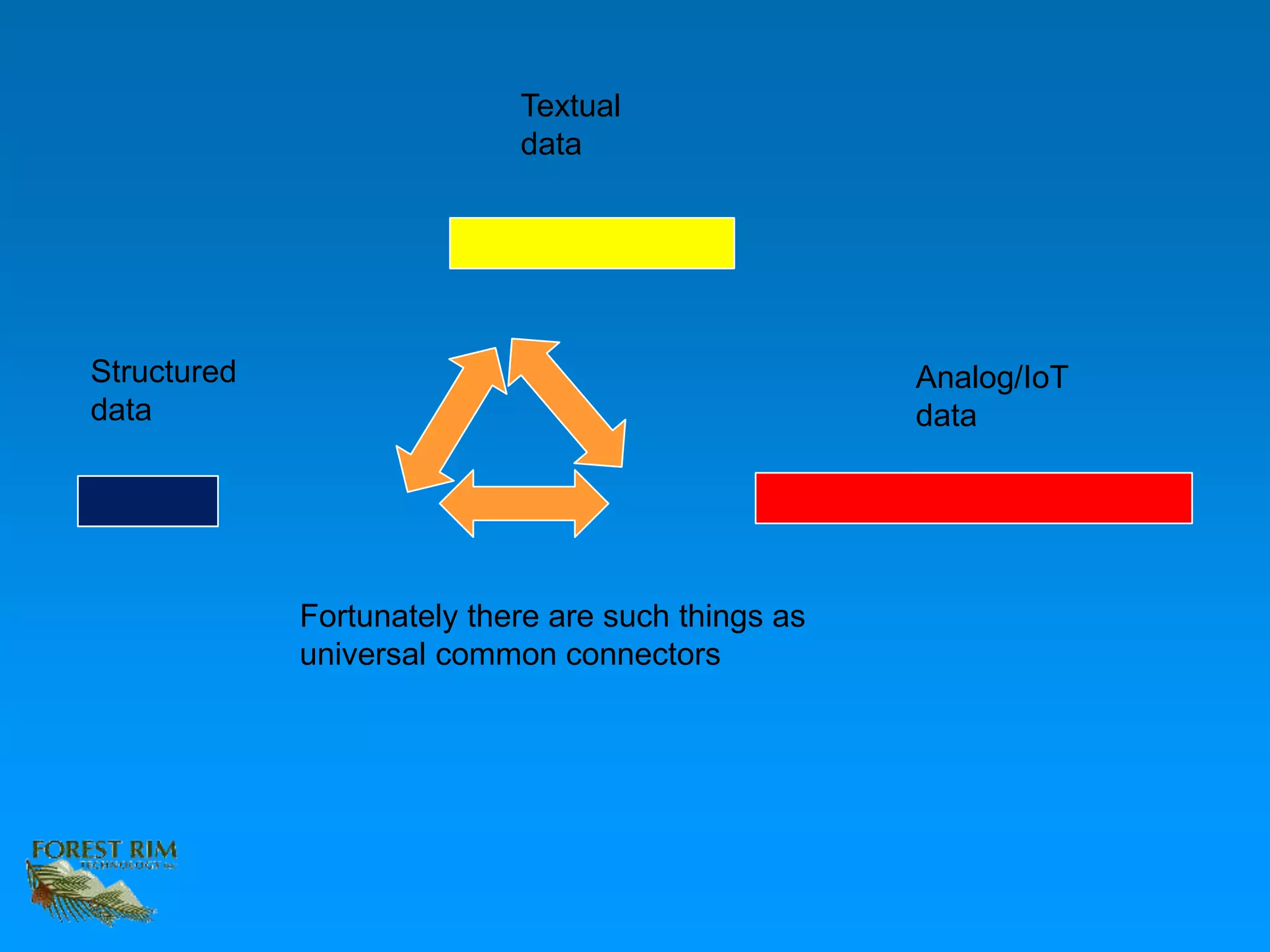

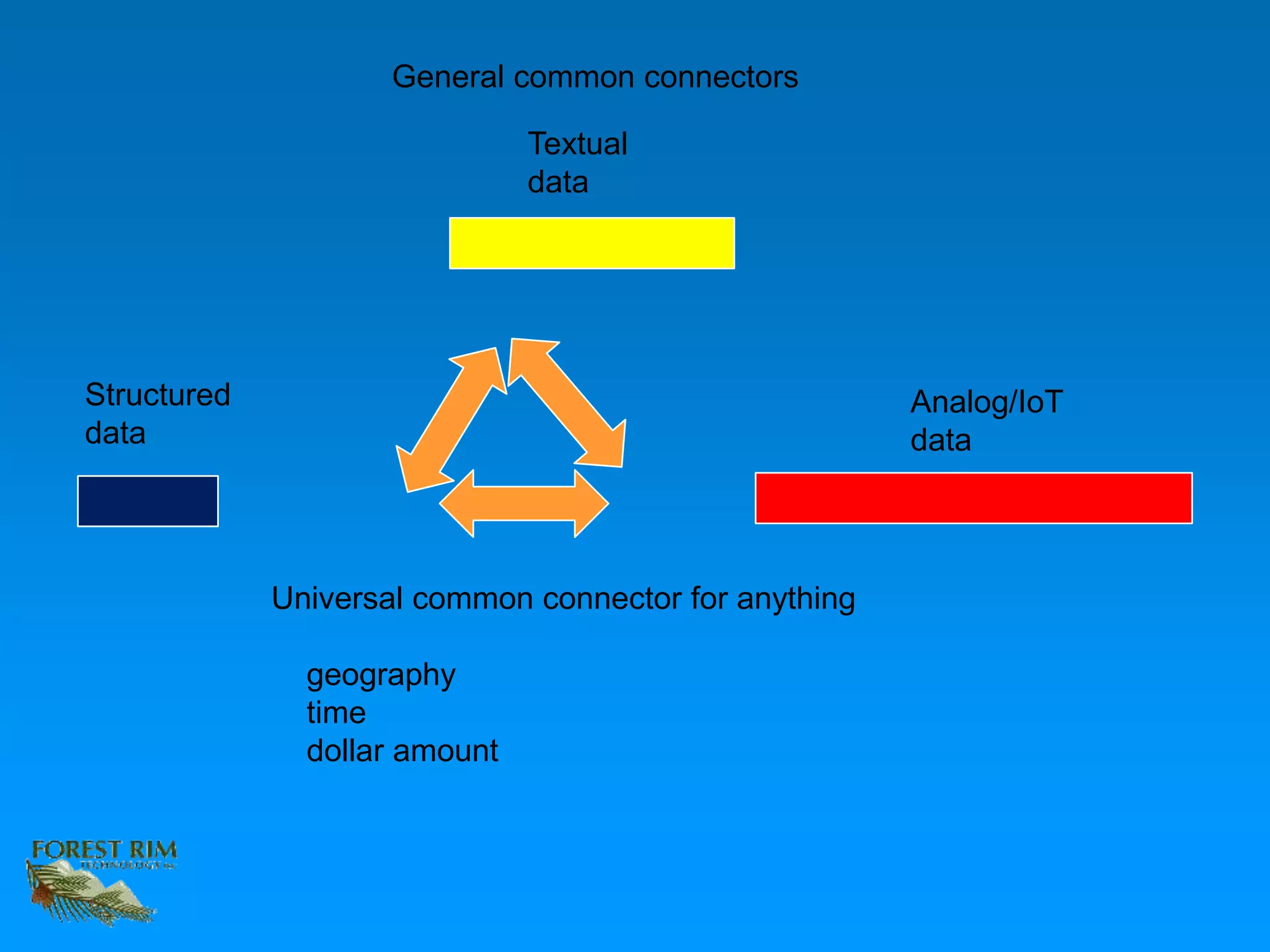
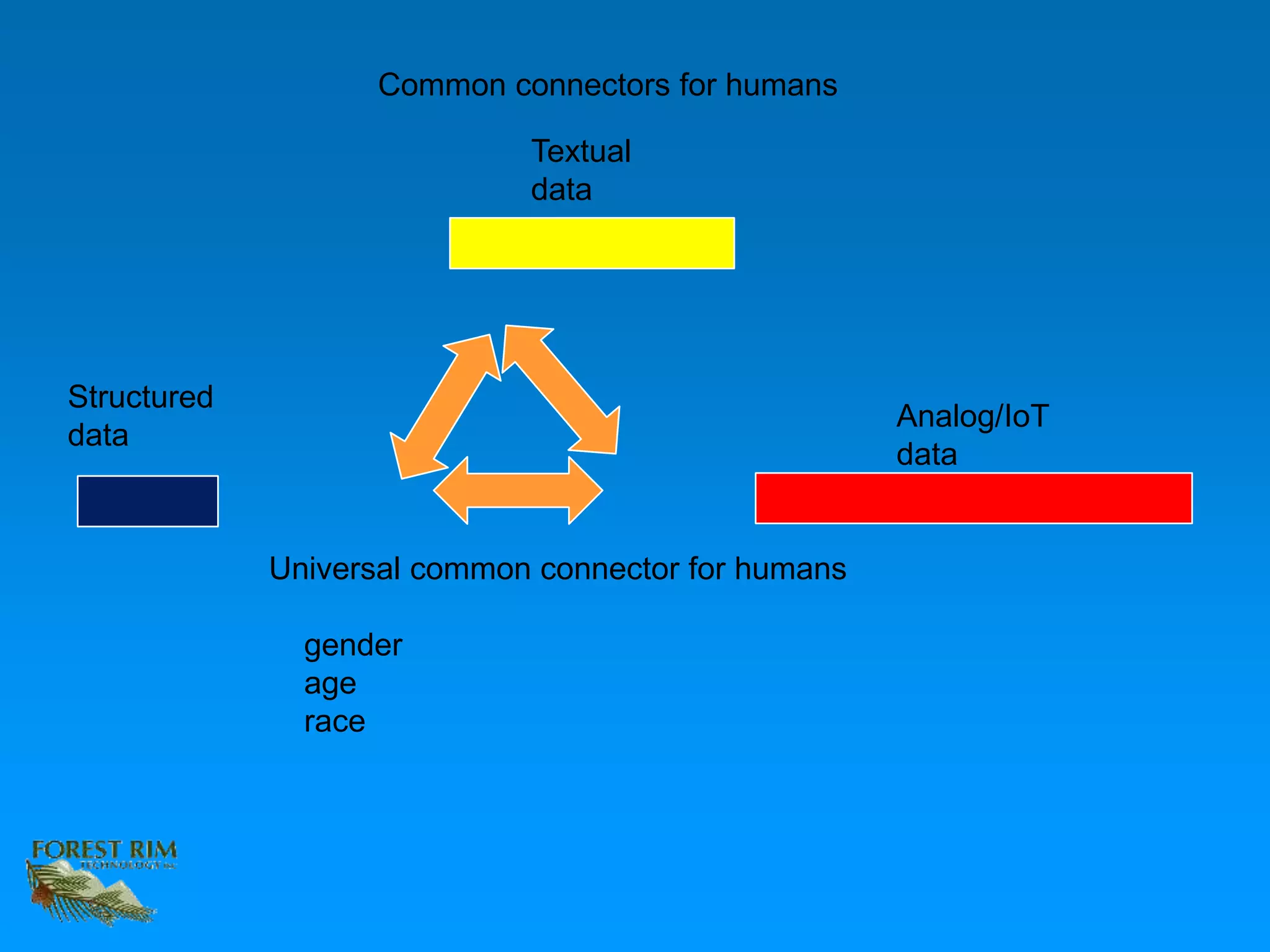
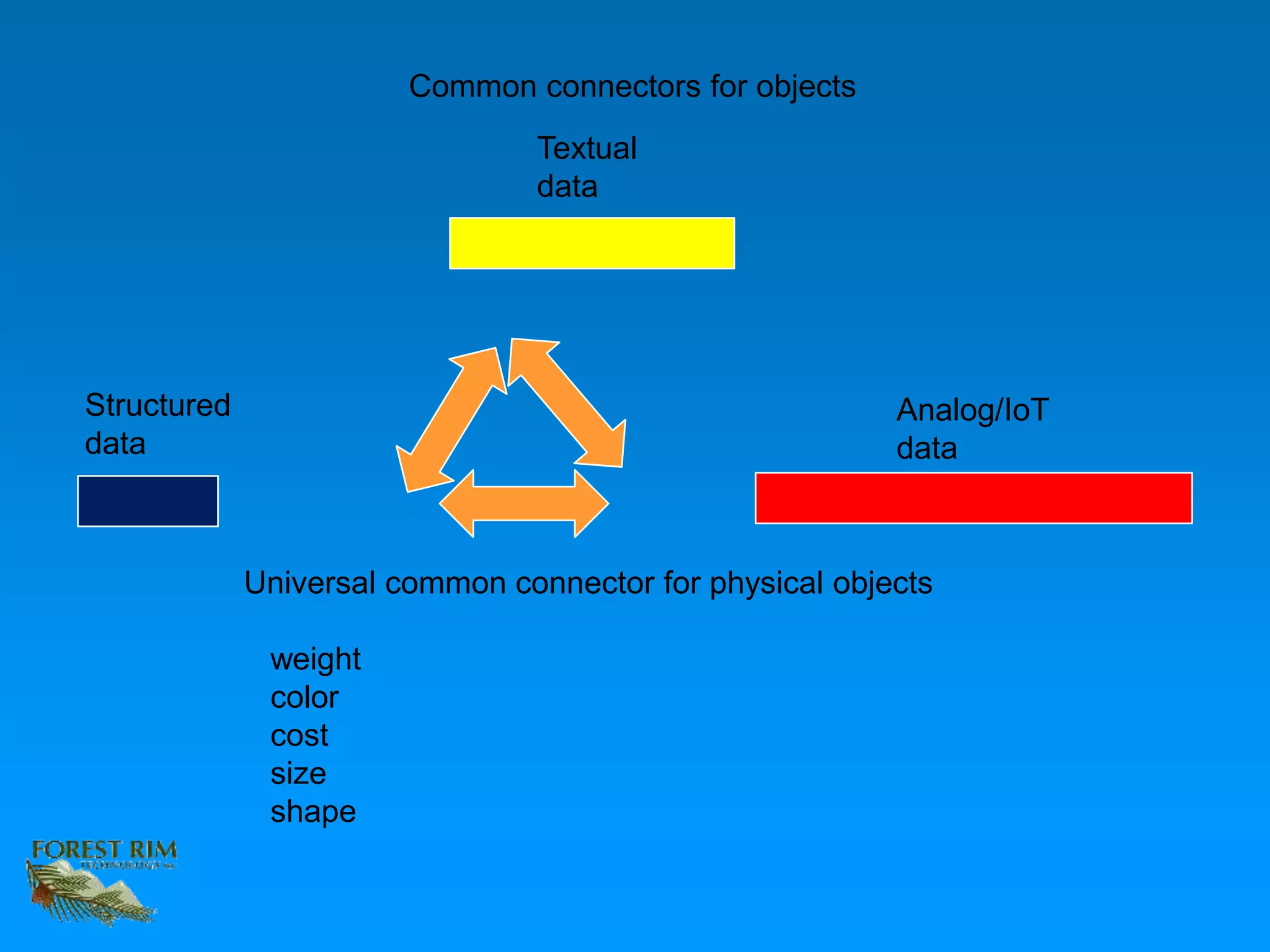



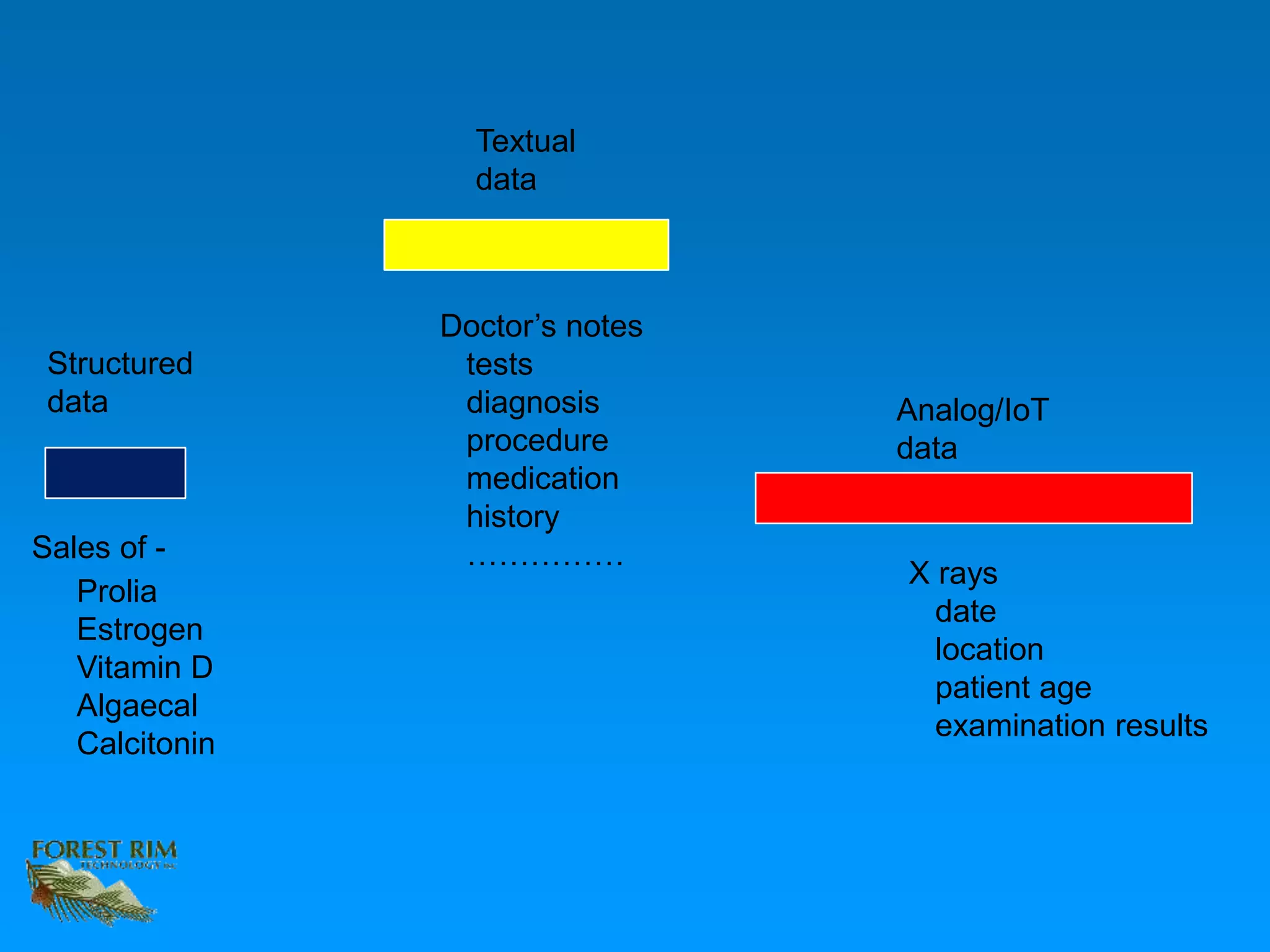





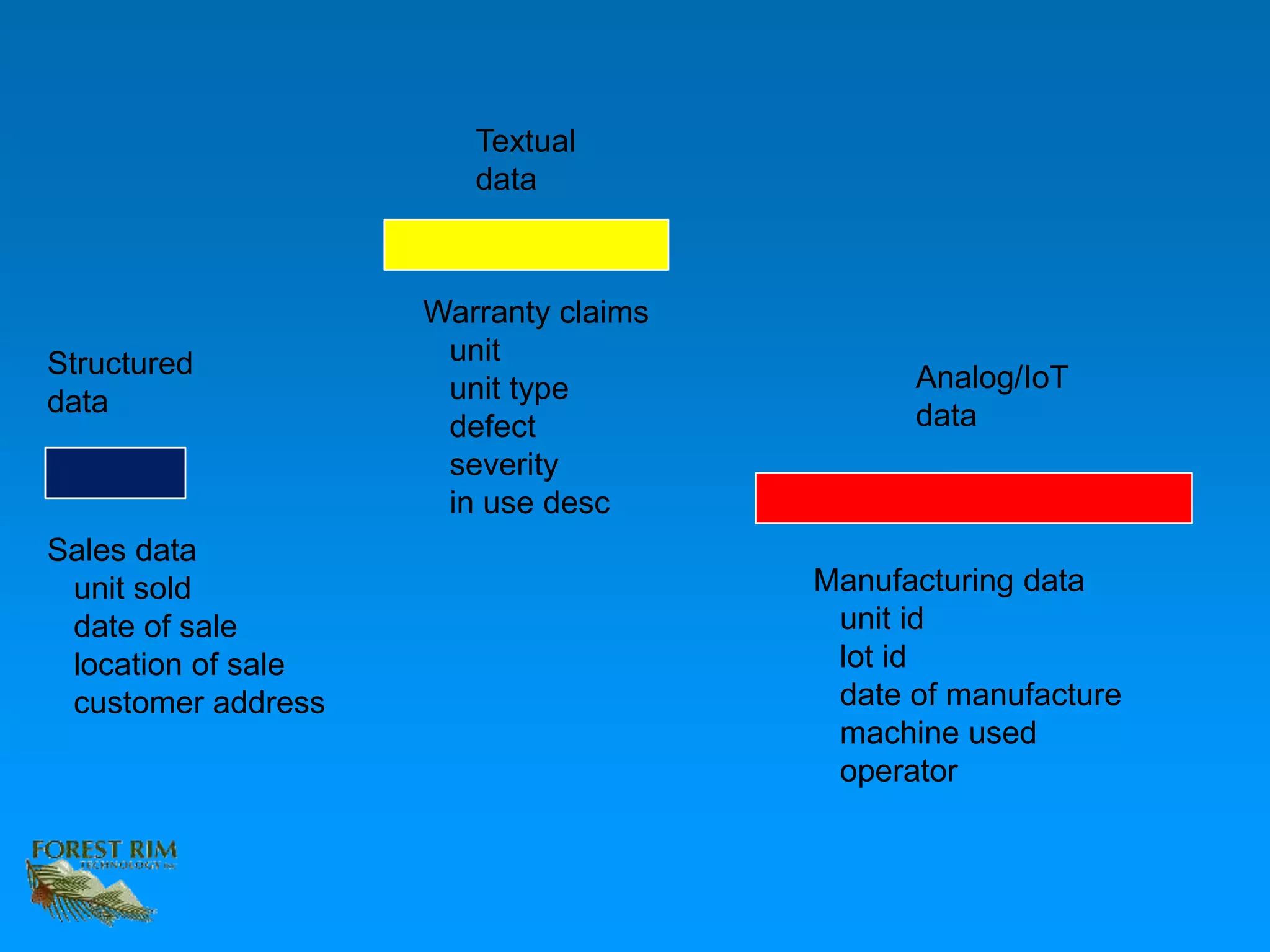

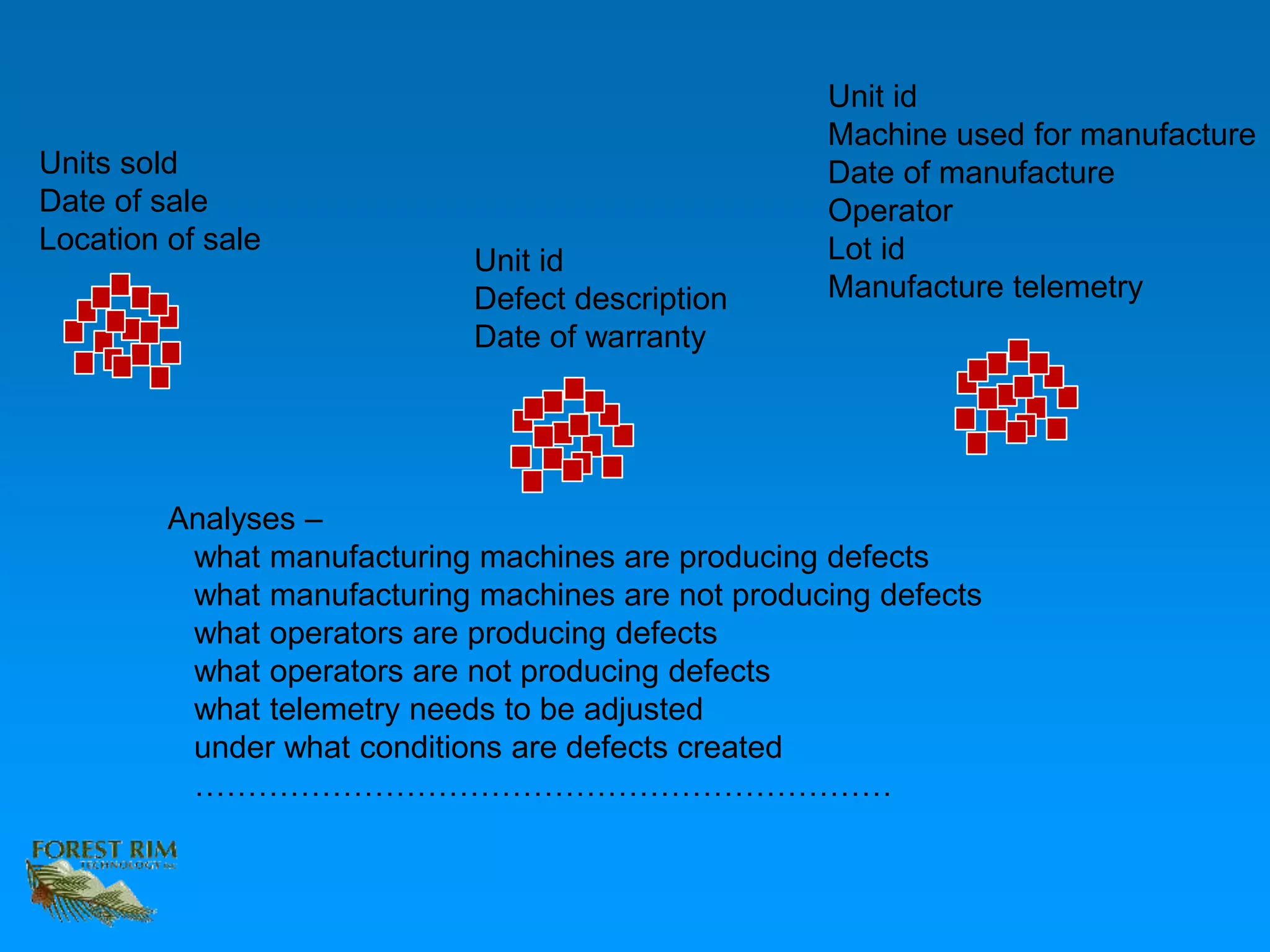
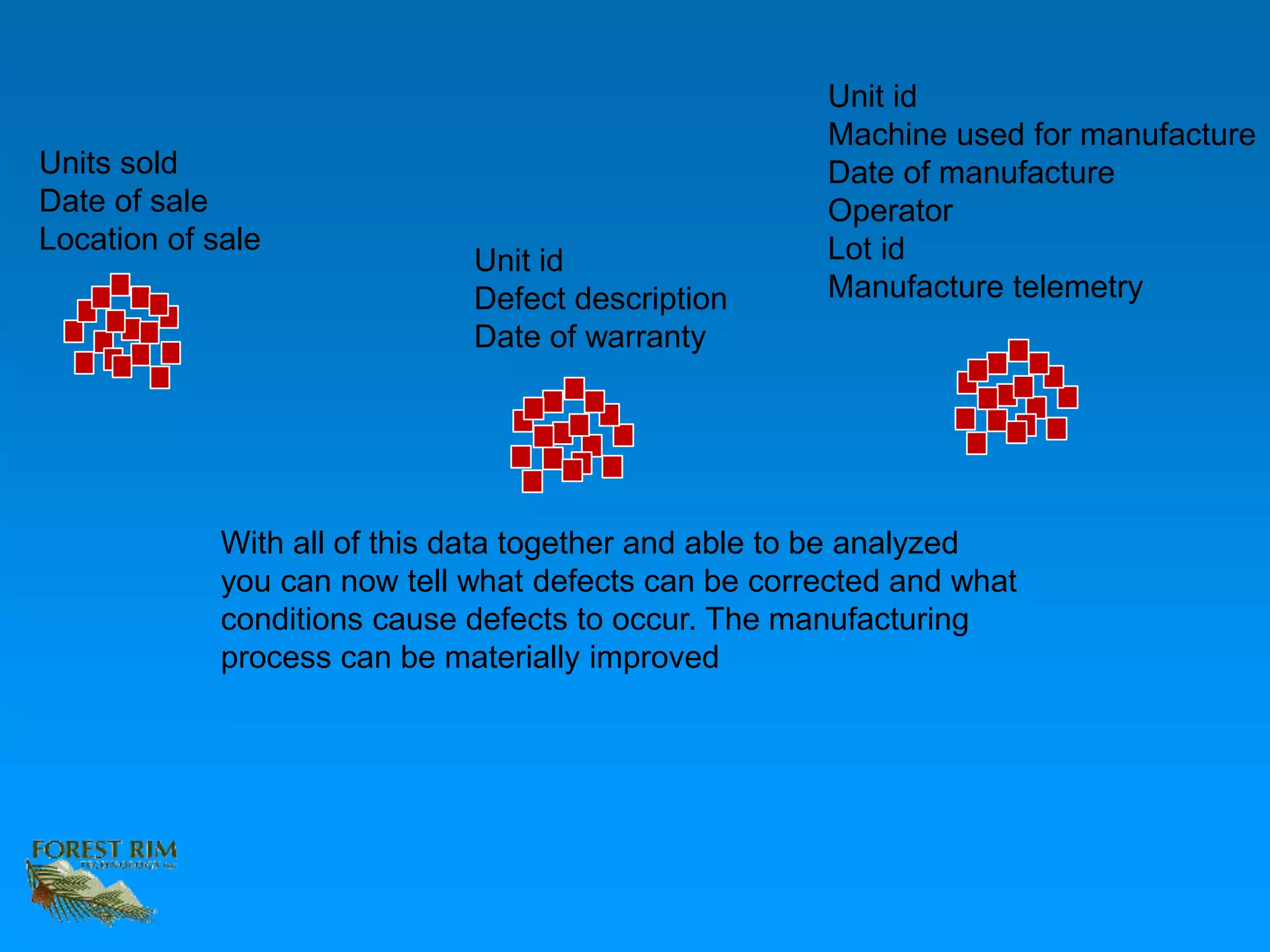


The document discusses the concept of a data lakehouse, highlighting the integration of structured, textual, and analog/IOT data. It emphasizes the importance of common identifiers and universal connectors for meaningful analytics across different data types, ultimately aiming to improve healthcare and manufacturing outcomes through effective data analysis. The presentation outlines the challenges of managing diverse data formats and the potential for data-driven insights to enhance quality of life.













![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)









































































