Downloaded 69 times







![Original Spark API
Functional operations on collections of Java/Python objects
(RDDs)
+ Expressive and concise
- Hard to automatically optimize
lines = spark.textFile(“hdfs://...”) // RDD[String]
points = lines.map(lambda line: parsePoint(line)) // RDD[Point]
points.filter(lambda p: p.x > 100).count()](https://image.slidesharecdn.com/odsc-2017-170504185008/85/Large-Scale-Data-Science-in-Apache-Spark-2-0-7-320.jpg)

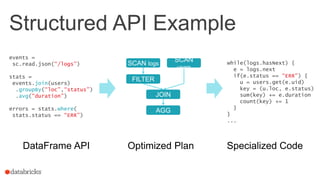
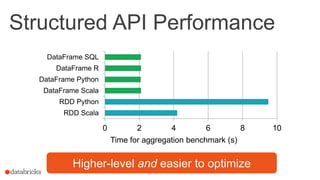


![Structured APIs Elsewhere
ML Pipelines on DataFrames
• Pipeline API based on scikit-
learn
• Grid search, cross-validation,
etc
GraphFrames for graph
analytics
• Pattern matching à la Neo4J
tokenizer = Tokenizer()
tf = HashingTF(numFeatures=1000)
lr = LogisticRegression()
pipe = Pipeline([tokenizer, tf, lr])
model = pipe.fit(df)
tokenizer TF LR
modelDataFrame](https://image.slidesharecdn.com/odsc-2017-170504185008/85/Large-Scale-Data-Science-in-Apache-Spark-2-0-13-320.jpg)




![Parallelizing Existing Libraries
Spark Python/R APIs let
you scale out existing
libraries
• spark-sklearn for arbitrary
scikit-learn models
• SparkR dapply
from sklearn import svm, datasets
from spark_sklearn import GridSearchCV
iris = datasets.load_iris()
model = svm.SVC()
params = {
'kernel': ['linear', 'rbf’],
'C': [1, 10]
}
gs = GridSearchCV(sc, model, params)
gs.fit(iris.data, iris.target)
github.com/databricks/spark-sklearn](https://image.slidesharecdn.com/odsc-2017-170504185008/85/Large-Scale-Data-Science-in-Apache-Spark-2-0-18-320.jpg)




This document discusses the enhancements in Apache Spark 2.0, focusing on its scalability for large-scale data science and AI through improved hardware and user scalability. It emphasizes the use of structured APIs for efficient data manipulation and introduces new features for deep learning and integration with existing Python and R libraries. The content highlights Spark's capabilities in parallelizing computations and the ease of building complex data science models with high-level APIs.





































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)
















