Downloaded 137 times








![New in 2.0
Whole-stage code generation
• Fuse across multiple operators
• Optimized Parquet I/O
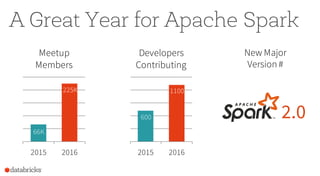
Spark 1.6 14M
rows/s
Spark 2.0 125M
rows/s
Parquet
in 1.6
11M
rows/s
Parquet
in 2.0
90M
rows/s
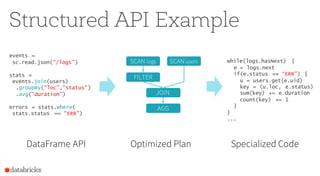
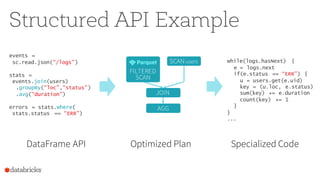
Merging DataFrame & Dataset
• DataFrame = Dataset[Row]](https://image.slidesharecdn.com/sparksummiteu2016keynote-simplifyingbigdatainapachespark2-161026131548/85/Spark-Summit-EU-2016-Keynote-Simplifying-Big-Data-in-Apache-Spark-2-0-11-320.jpg)
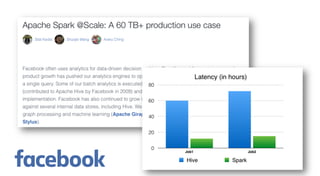





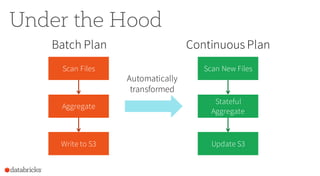
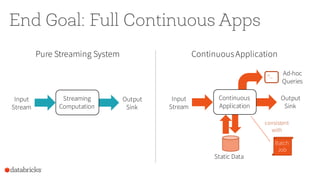



Apache Spark 2.0 simplifies big data processing with a unified engine that enhances productivity and performance through improvements in high-level APIs like DataFrames and structured streaming. New features include whole-stage code generation, support for structured streaming, and optimizations that increase performance significantly, allowing for complex operations such as joins and aggregations. The version is designed to integrate seamlessly with existing applications and support diverse workloads, ultimately facilitating both batch and real-time processing.











































































































