Downloaded 115 times

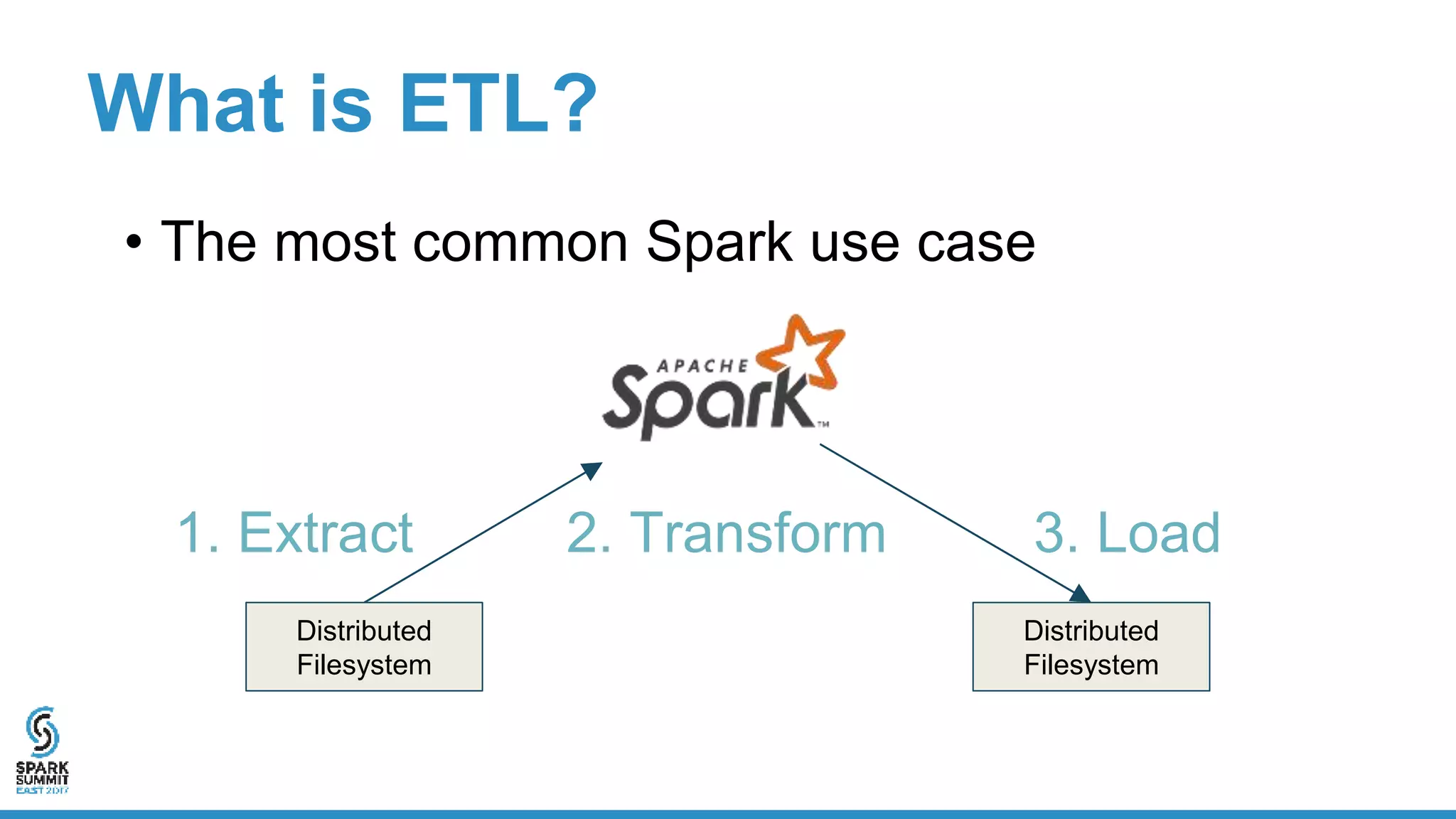

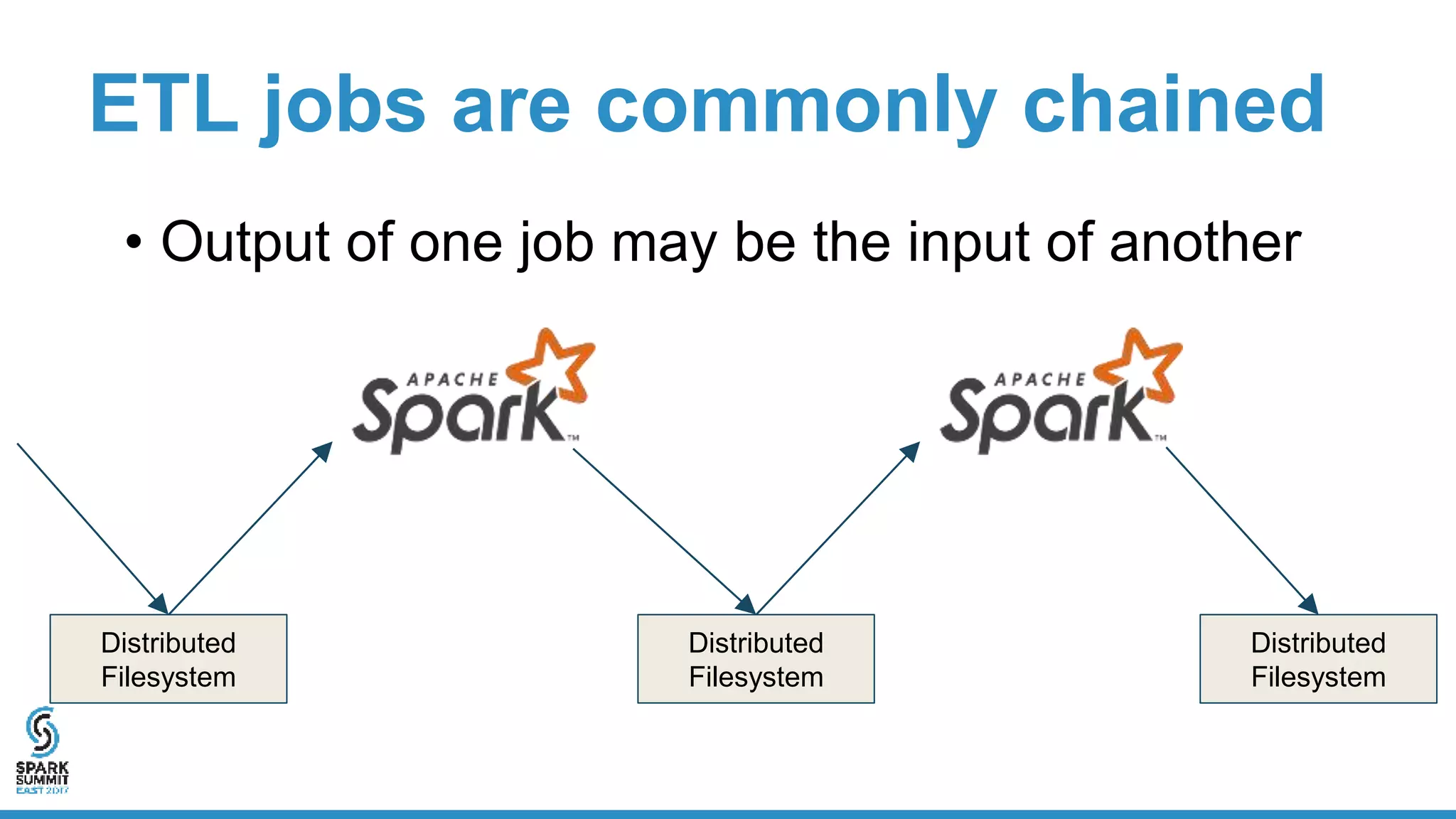
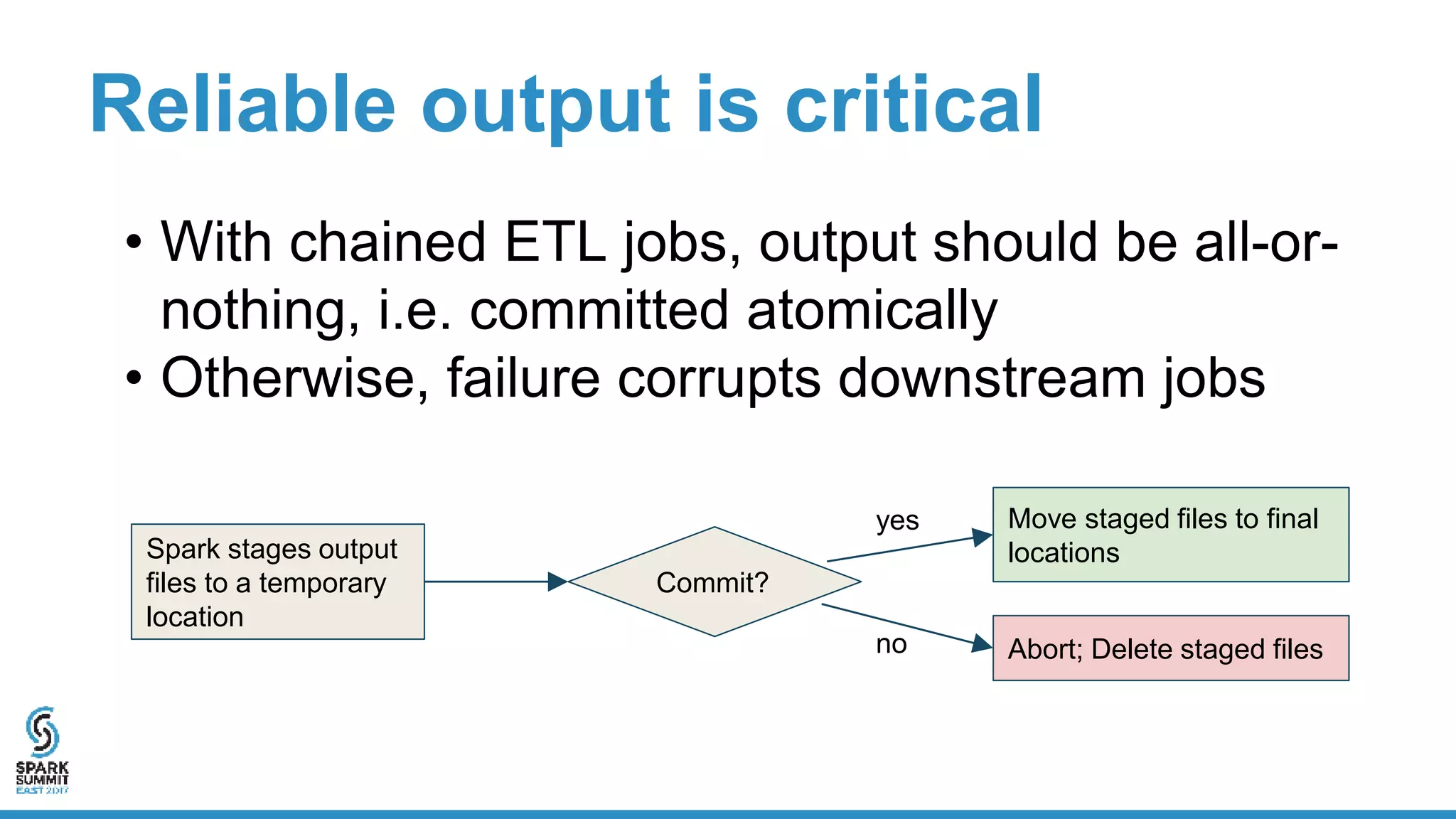











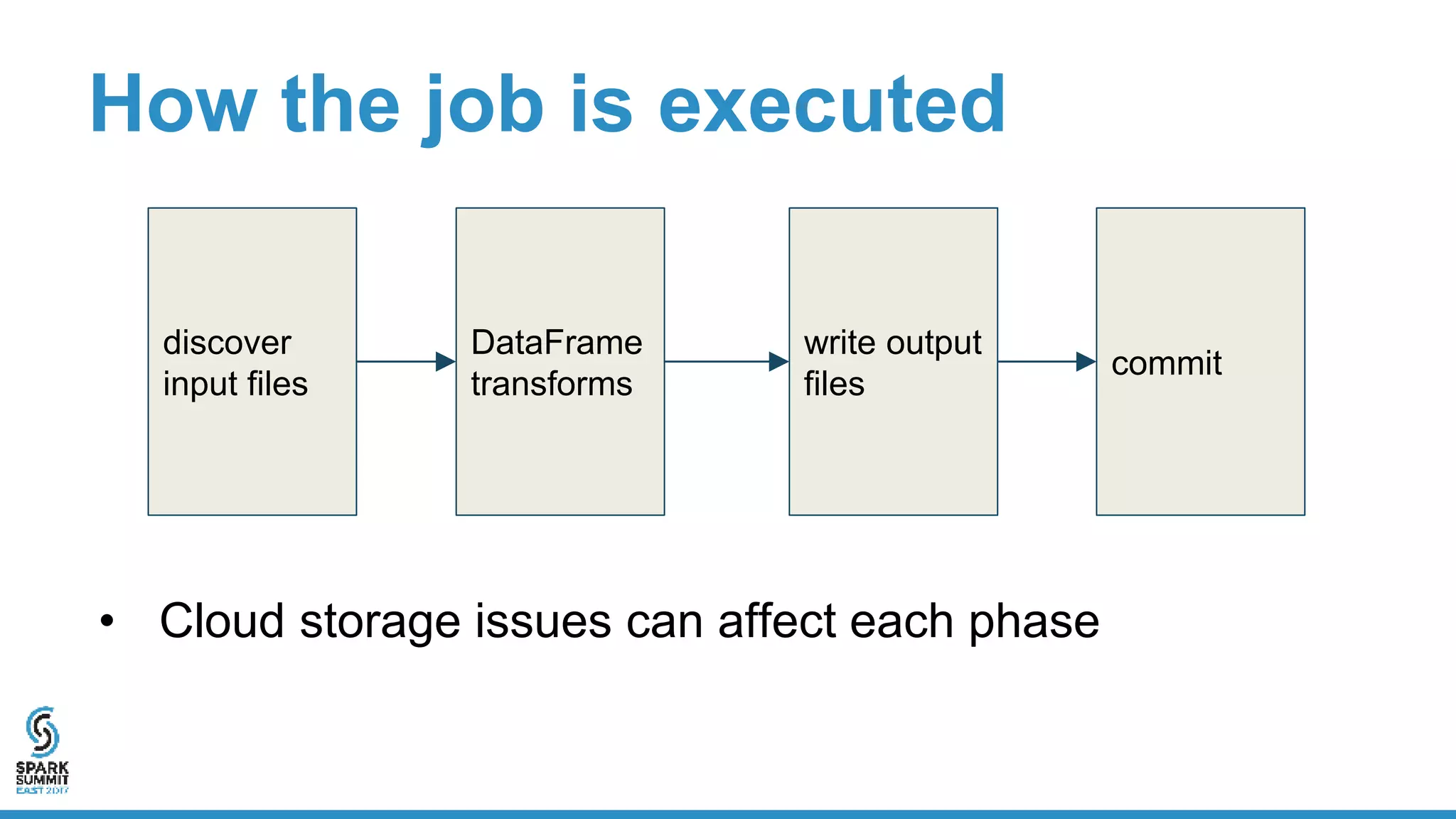





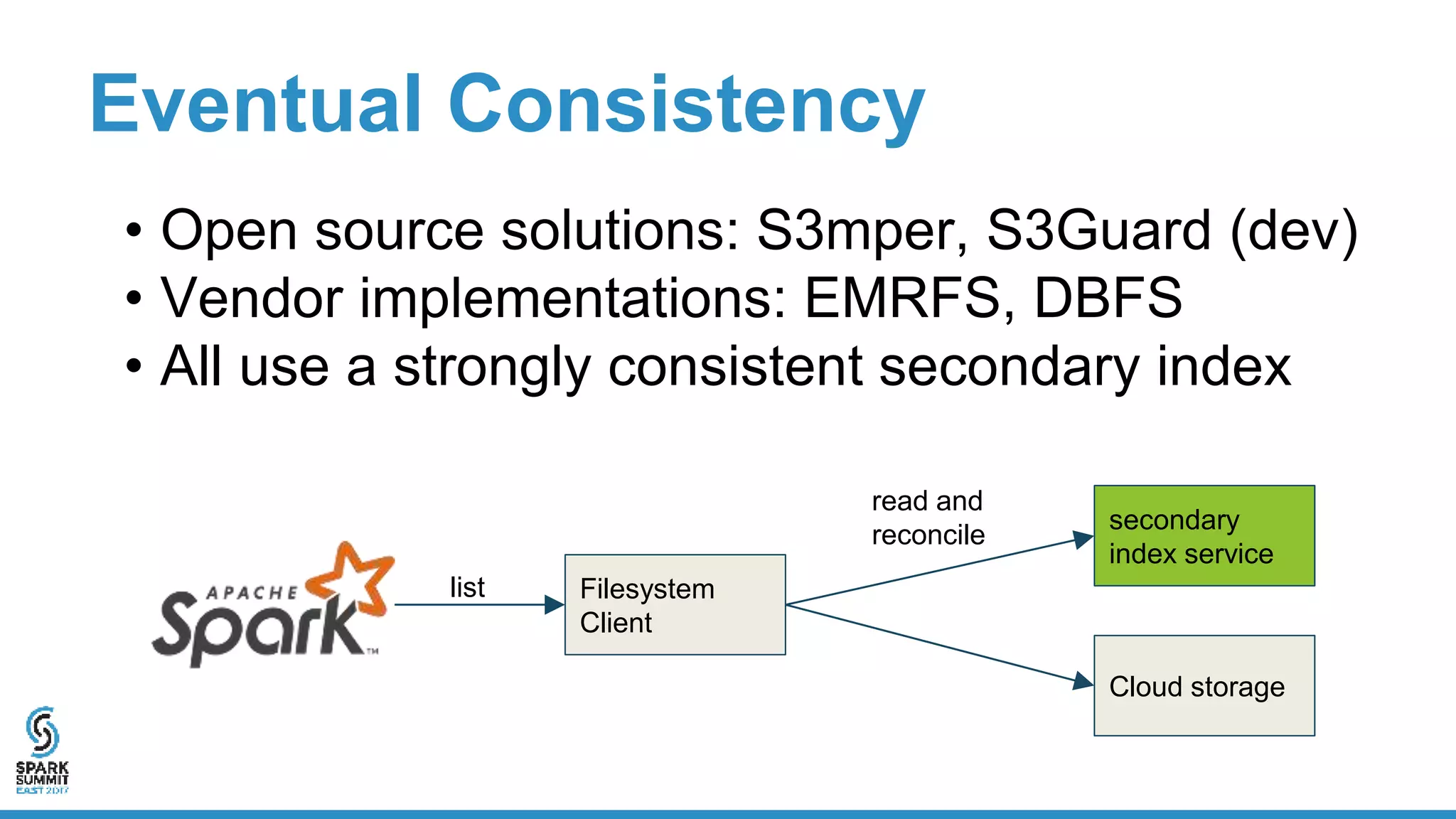


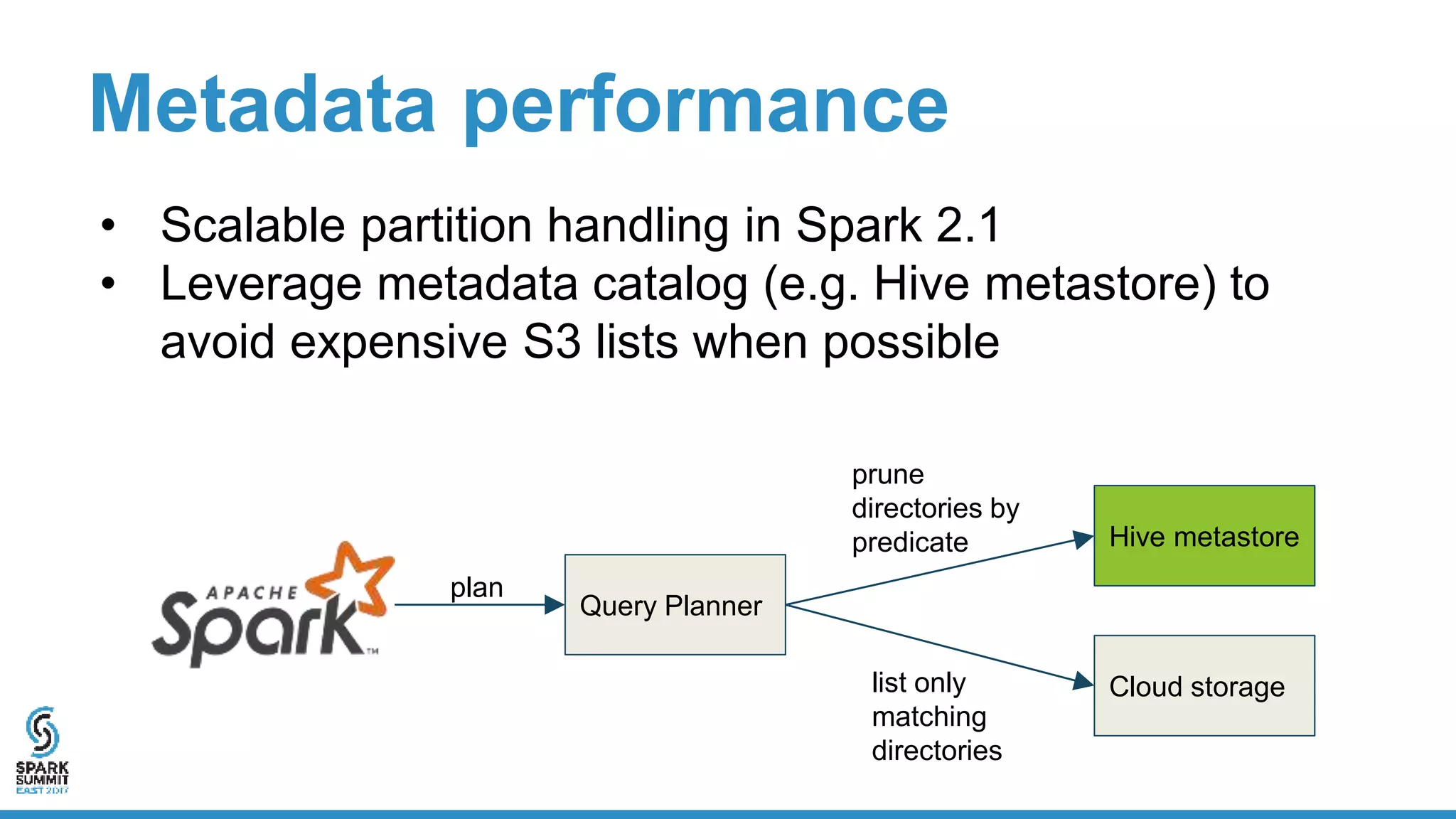
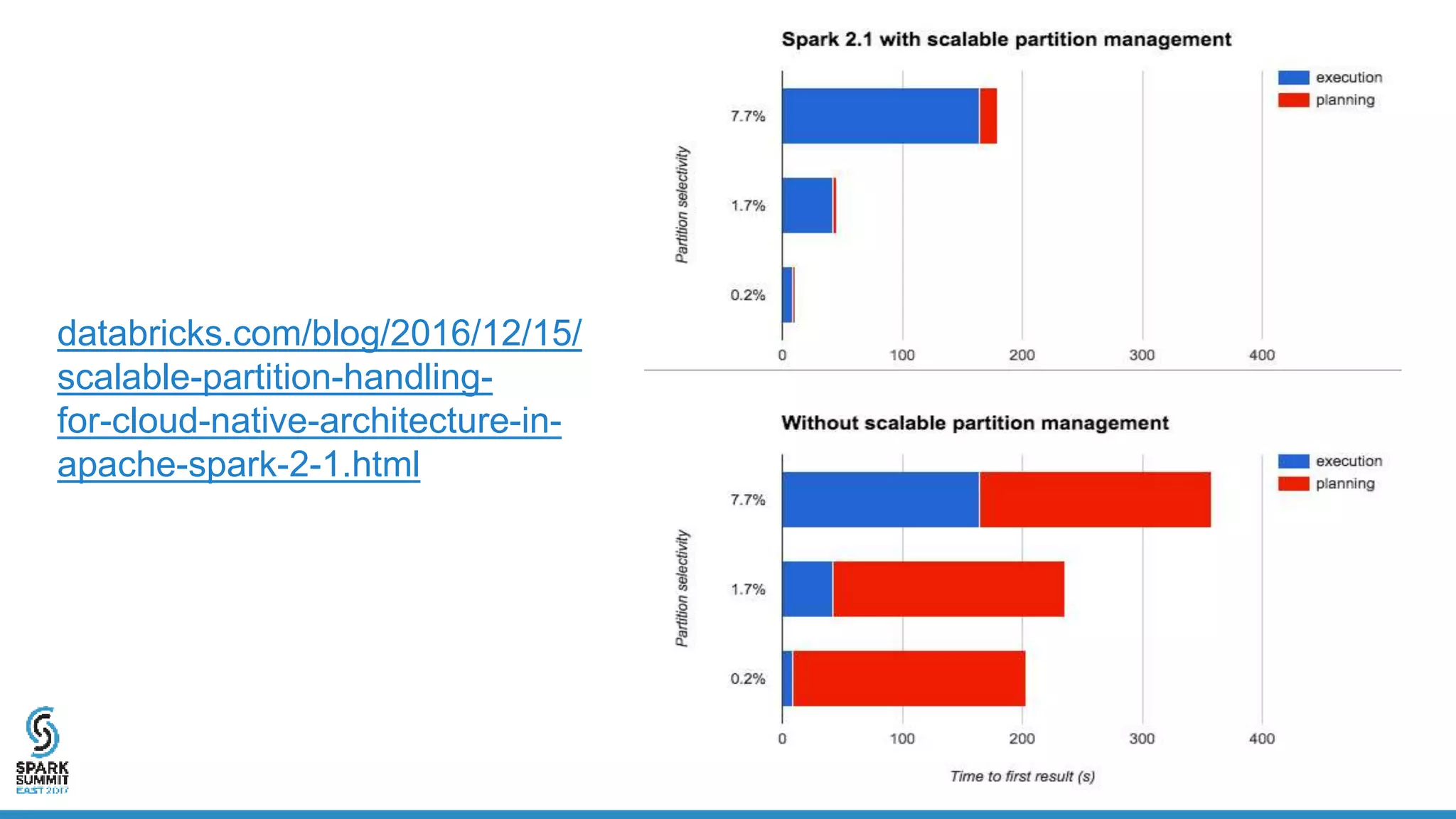





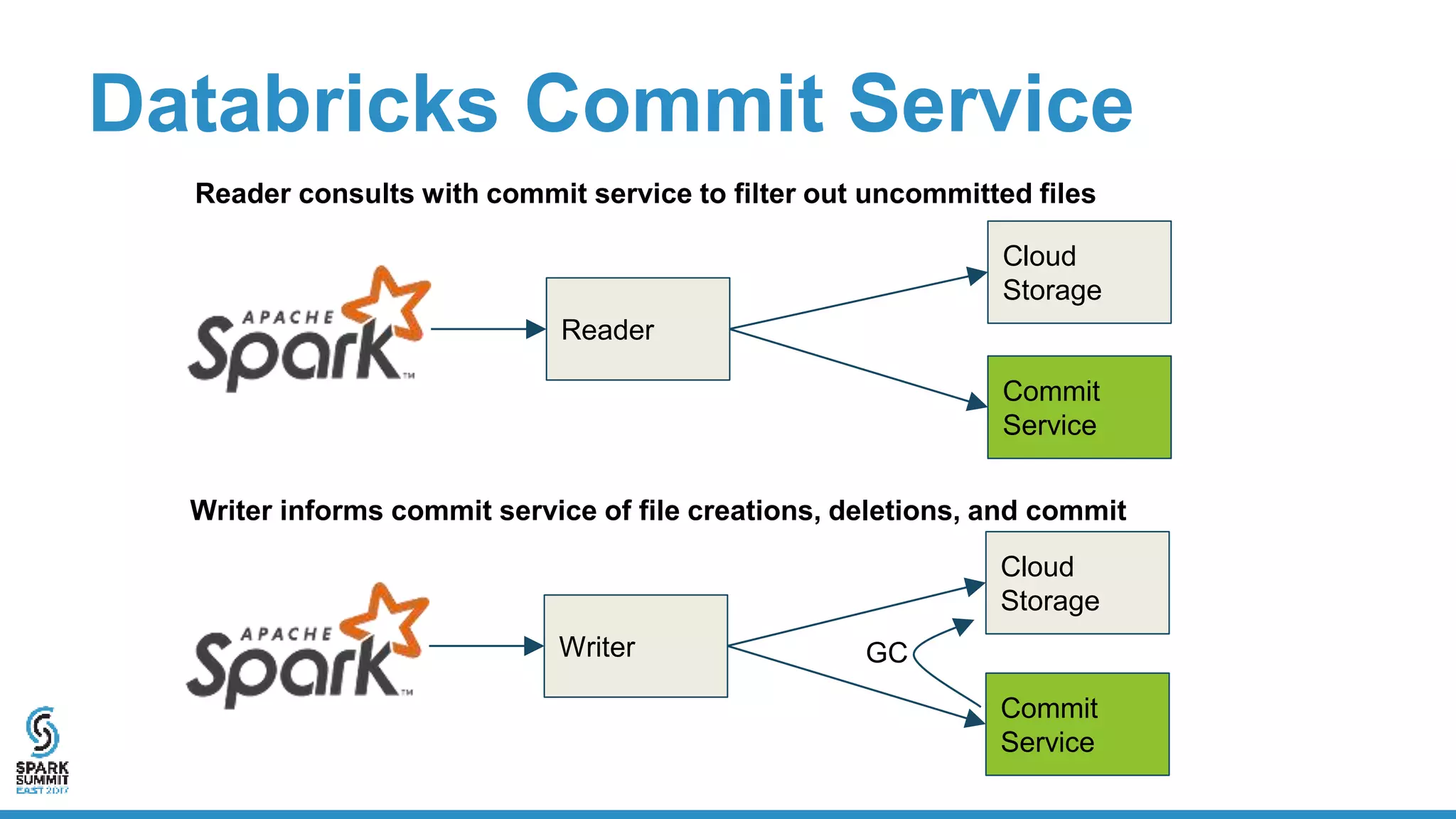
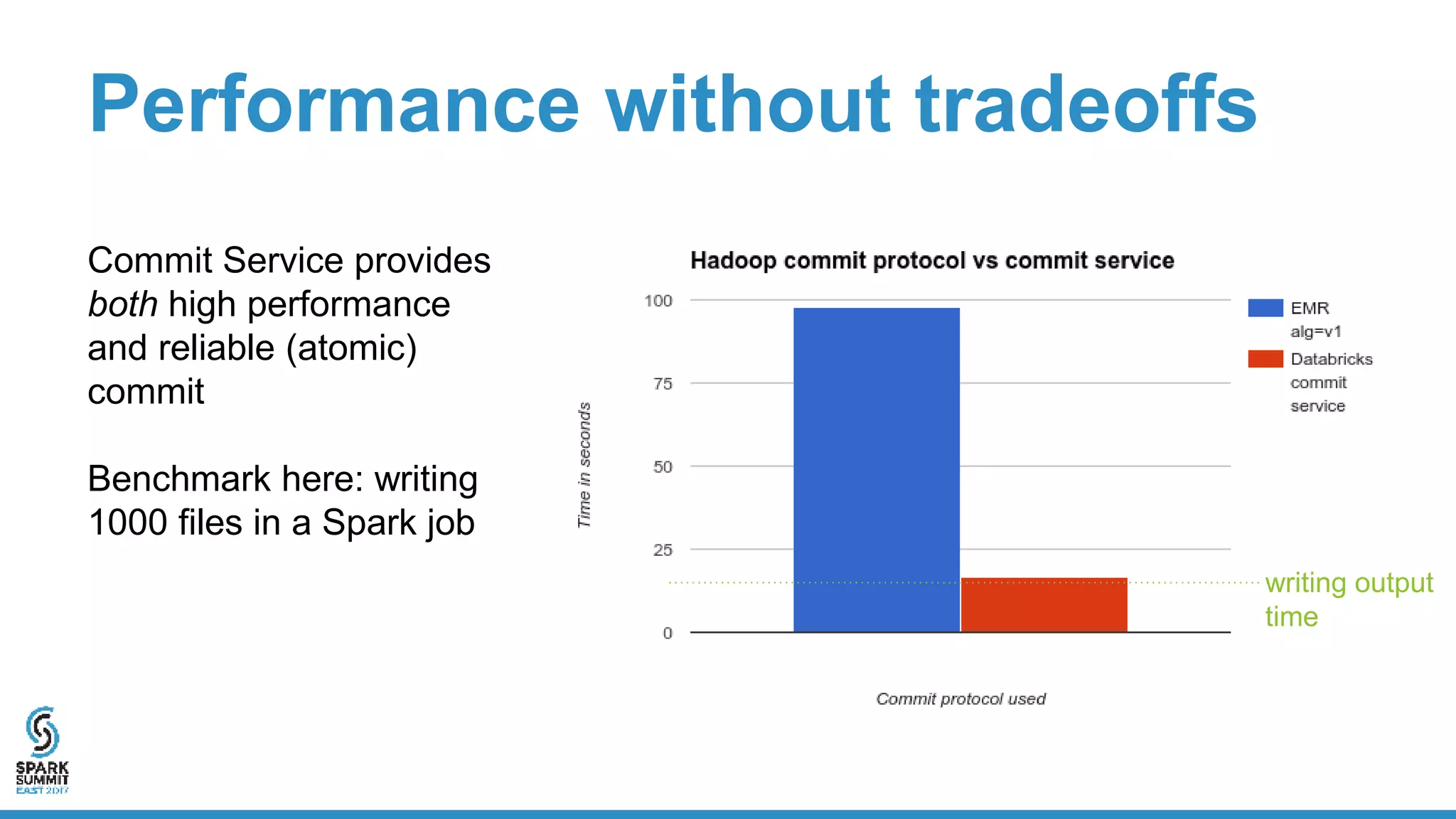



The document discusses the implementation of ETL (Extract, Transform, Load) processes on cloud storage using Databricks and highlights the challenges of reliability and performance with cloud-native storage compared to HDFS. It examines the trade-offs regarding costs, availability, durability, and metadata performance, proposing solutions such as the Databricks commit service to ensure atomic commits and manage eventual consistency. Overall, the document advocates for leveraging cloud storage while addressing its limitations to achieve efficient and reliable ETL operations.

























































![[262] netflix 빅데이터 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/226netflix-150915054913-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

















































