Downloaded 57 times


























![Demo: PySpark Streaming Network Word Count
import sys!
from pyspark import SparkContext!
from pyspark.streaming import StreamingContext!
!
sc = SparkContext(appName="PyStreamNWC", master="local[*]")!
ssc = StreamingContext(sc, Seconds(5))!
!
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))!
!
counts = lines.flatMap(lambda line: line.split(" ")) !
.map(lambda word: (word, 1)) !
.reduceByKey(lambda a, b: a+b)!
!
counts.pprint()!
!
ssc.start()!
ssc.awaitTermination()
34](https://image.slidesharecdn.com/lastreaming-141211013356-conversion-gate02/85/Databricks-Meetup-Los-Angeles-Apache-Spark-User-Group-34-320.jpg)
![Demo: PySpark Streaming Network Word Count - Stateful
import sys!
from pyspark import SparkContext!
from pyspark.streaming import StreamingContext!
!
def updateFunc (new_values, last_sum):!
return sum(new_values) + (last_sum or 0)!
!
sc = SparkContext(appName="PyStreamNWC", master="local[*]")!
ssc = StreamingContext(sc, Seconds(5))!
ssc.checkpoint("checkpoint")!
!
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))!
!
counts = lines.flatMap(lambda line: line.split(" ")) !
.map(lambda word: (word, 1)) !
.updateStateByKey(updateFunc) !
.transform(lambda x: x.sortByKey())!
!
counts.pprint()!
!
ssc.start()!
ssc.awaitTermination()
35](https://image.slidesharecdn.com/lastreaming-141211013356-conversion-gate02/85/Databricks-Meetup-Los-Angeles-Apache-Spark-User-Group-35-320.jpg)

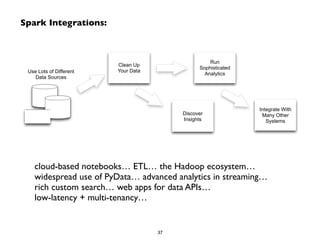
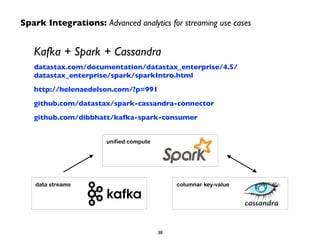












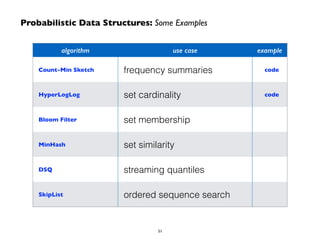





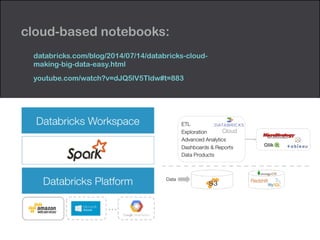







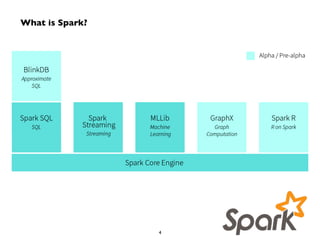
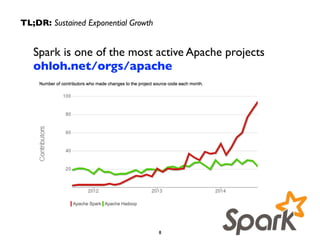
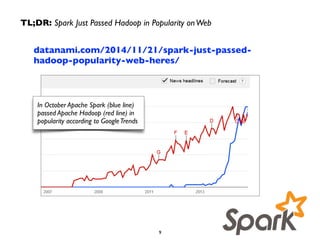
This document summarizes a presentation on Apache Spark and Spark Streaming. It provides an overview of Spark, describing it as an in-memory cluster computing framework. It then discusses Spark Streaming, explaining that it runs streaming computations as small batch jobs to provide low latency processing. Several use cases for Spark Streaming are presented, including from companies like Stratio, Pearson, Ooyala, and Sharethrough. The presentation concludes with a demonstration of Python Spark Streaming code.

























































































