Downloaded 544 times






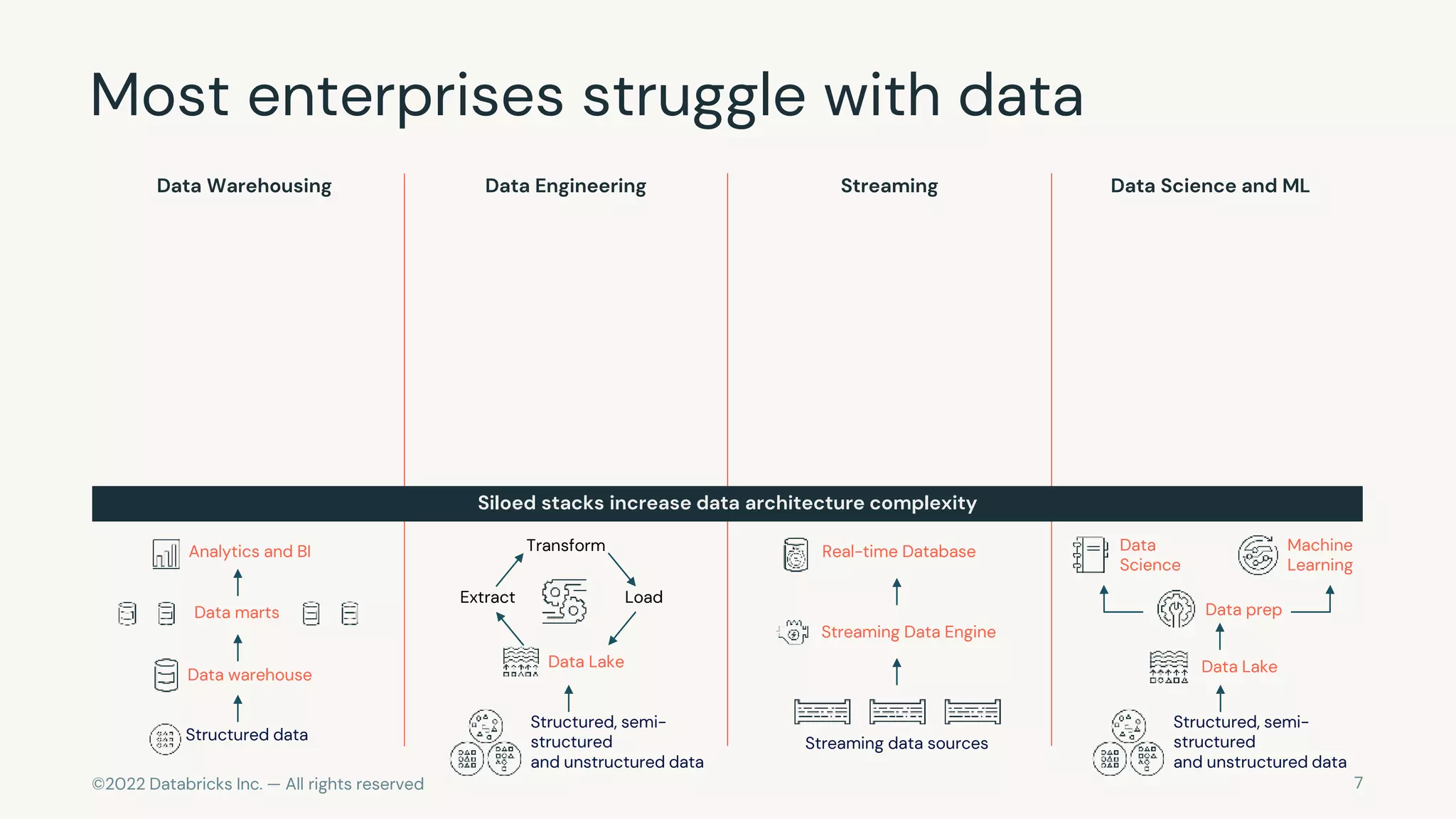
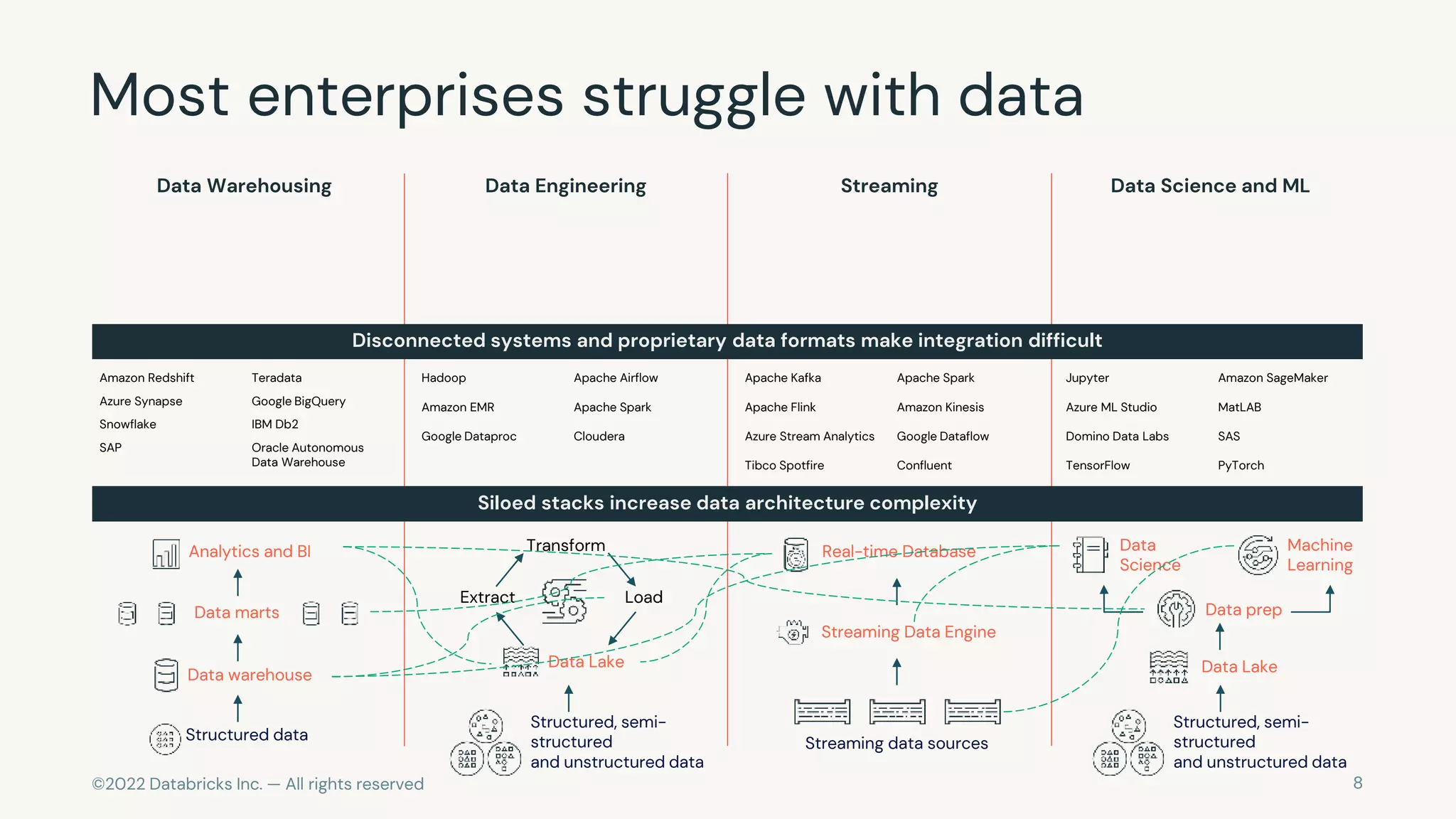
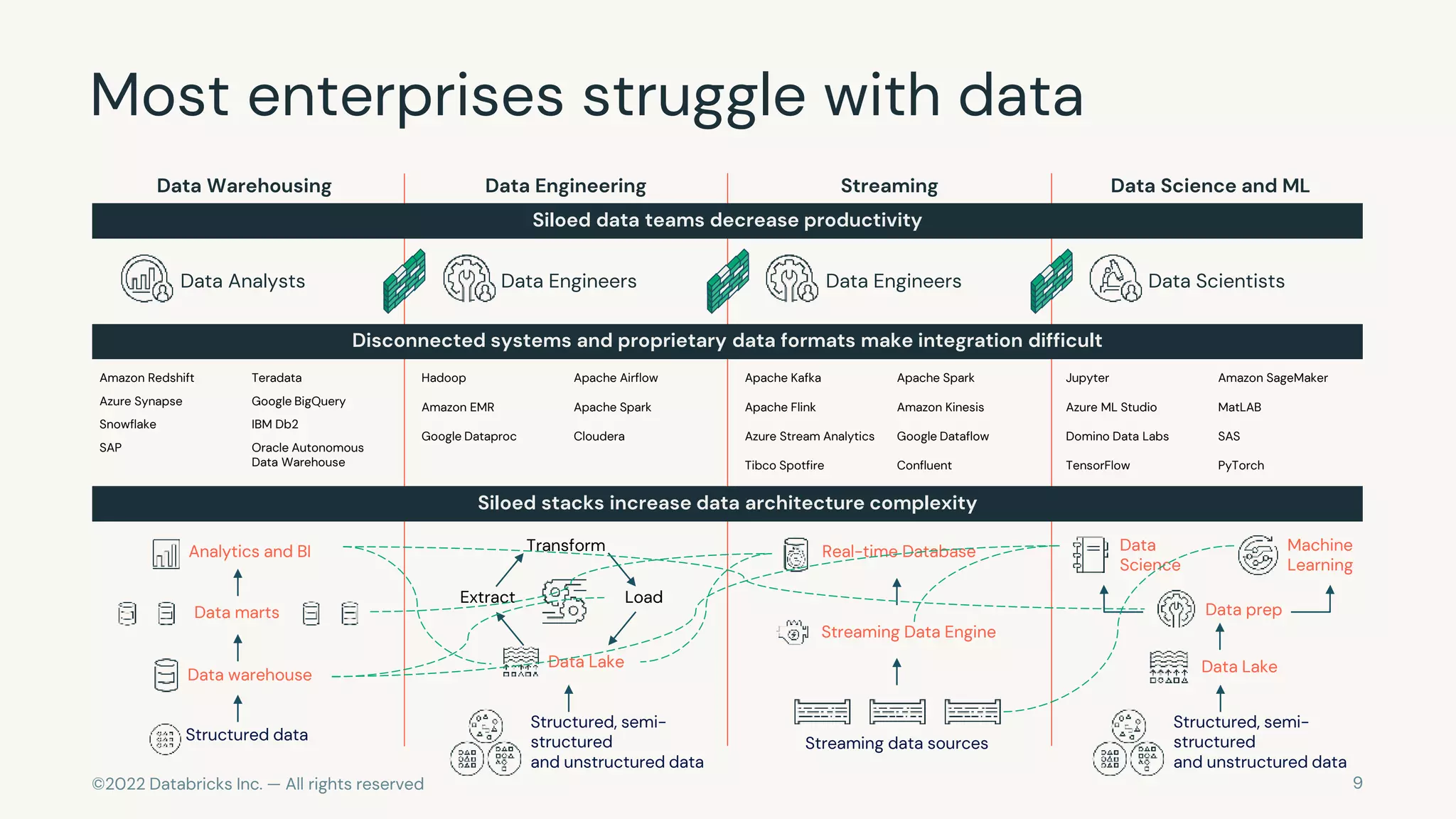



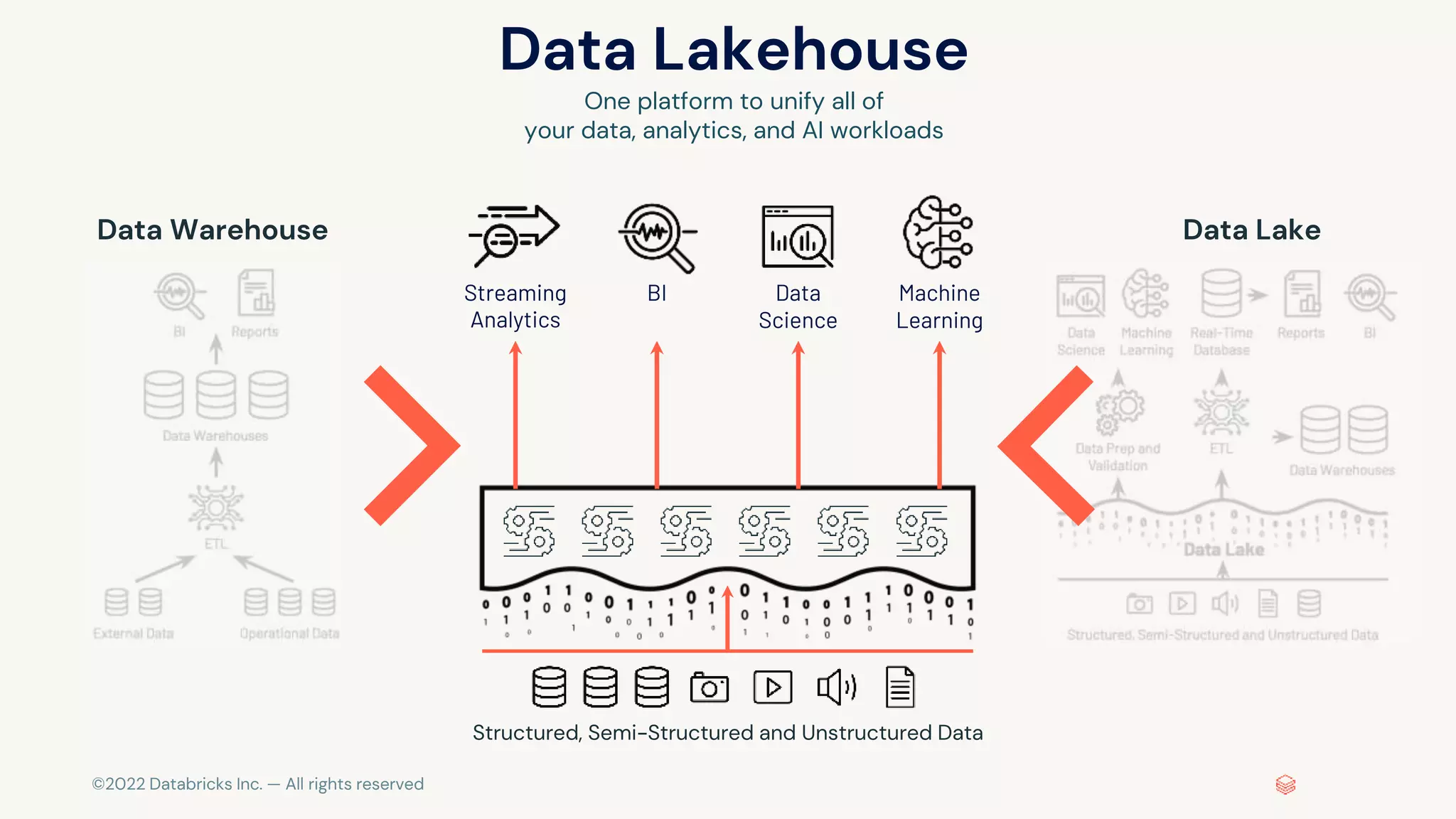




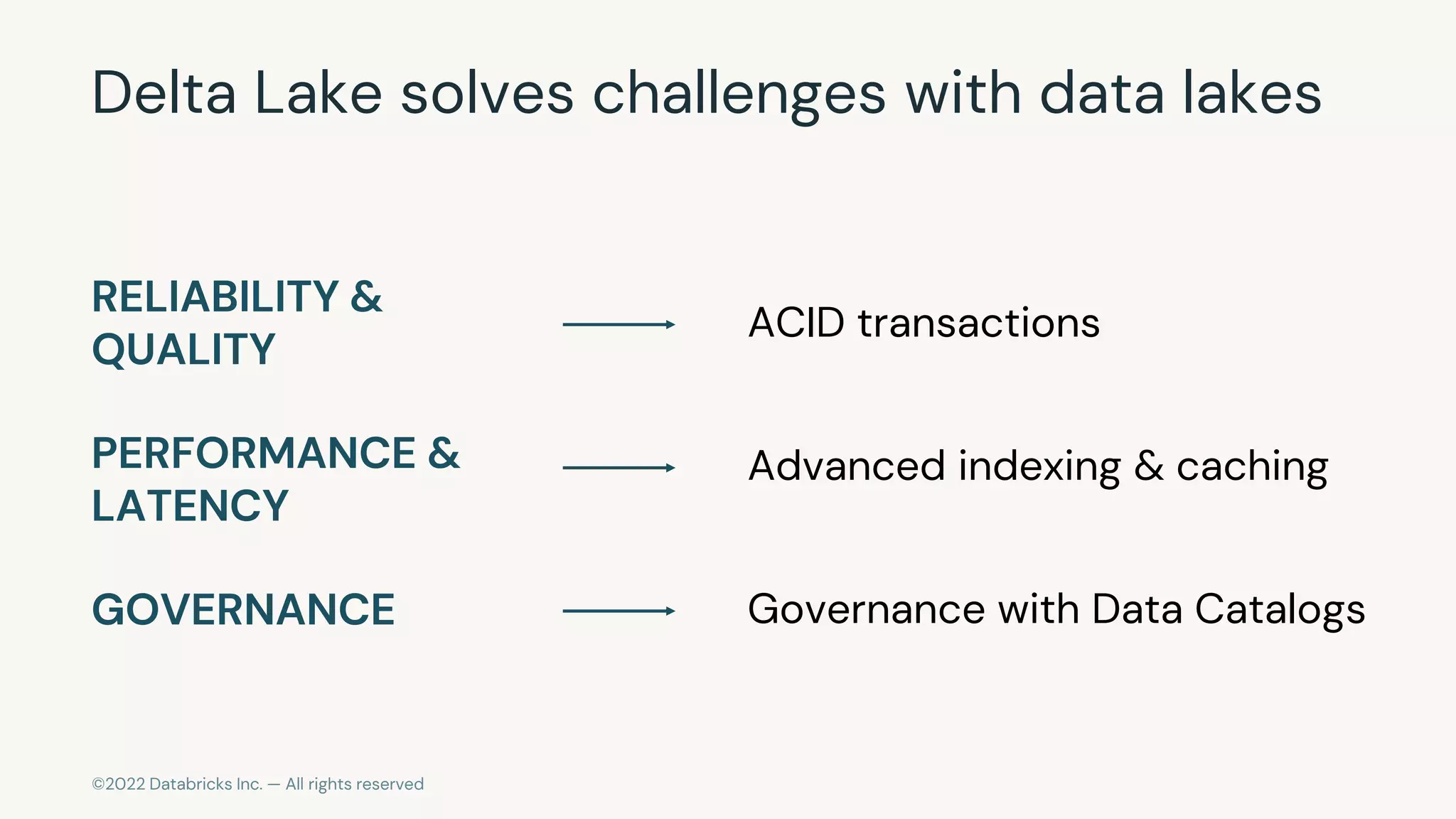














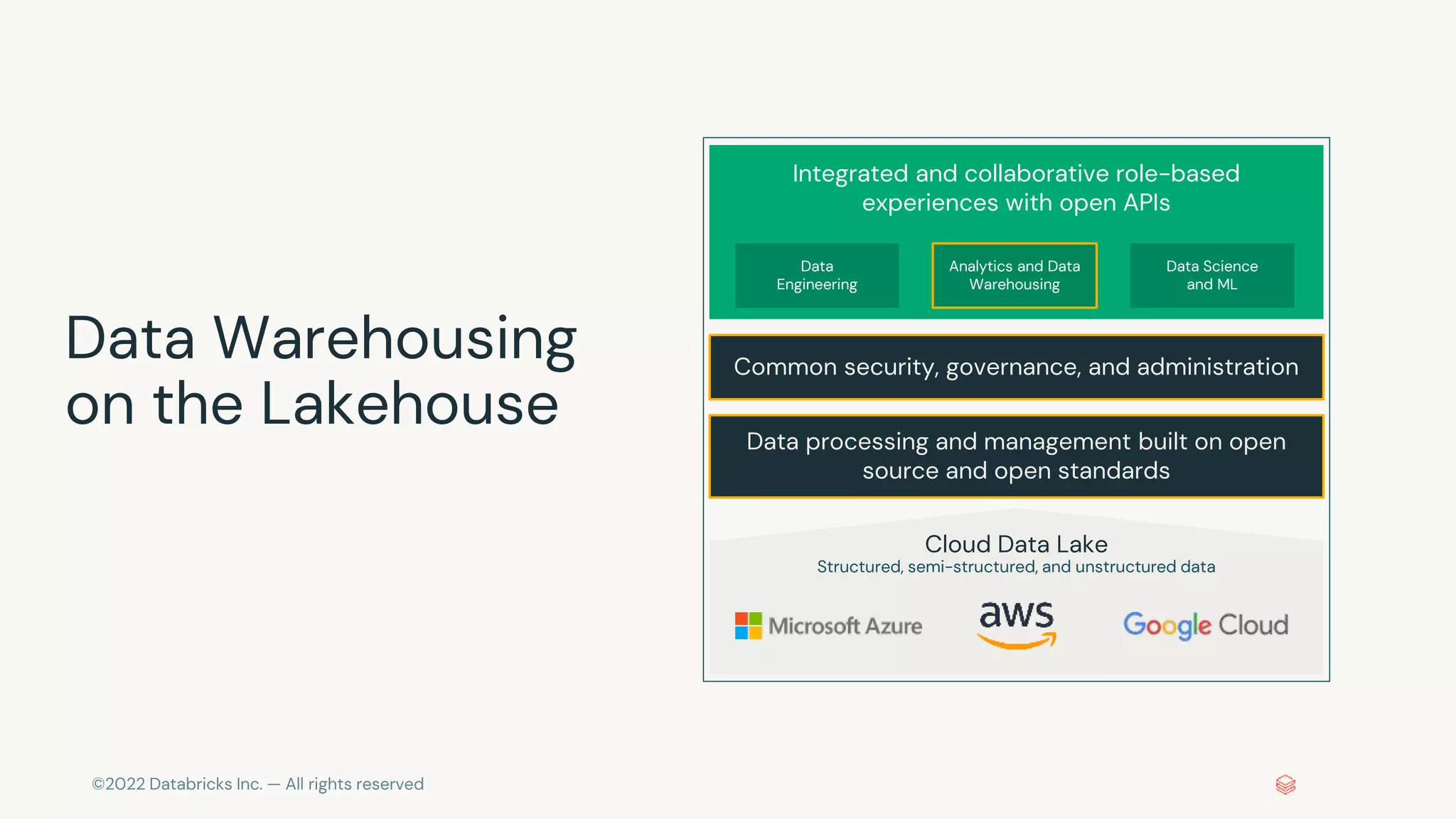













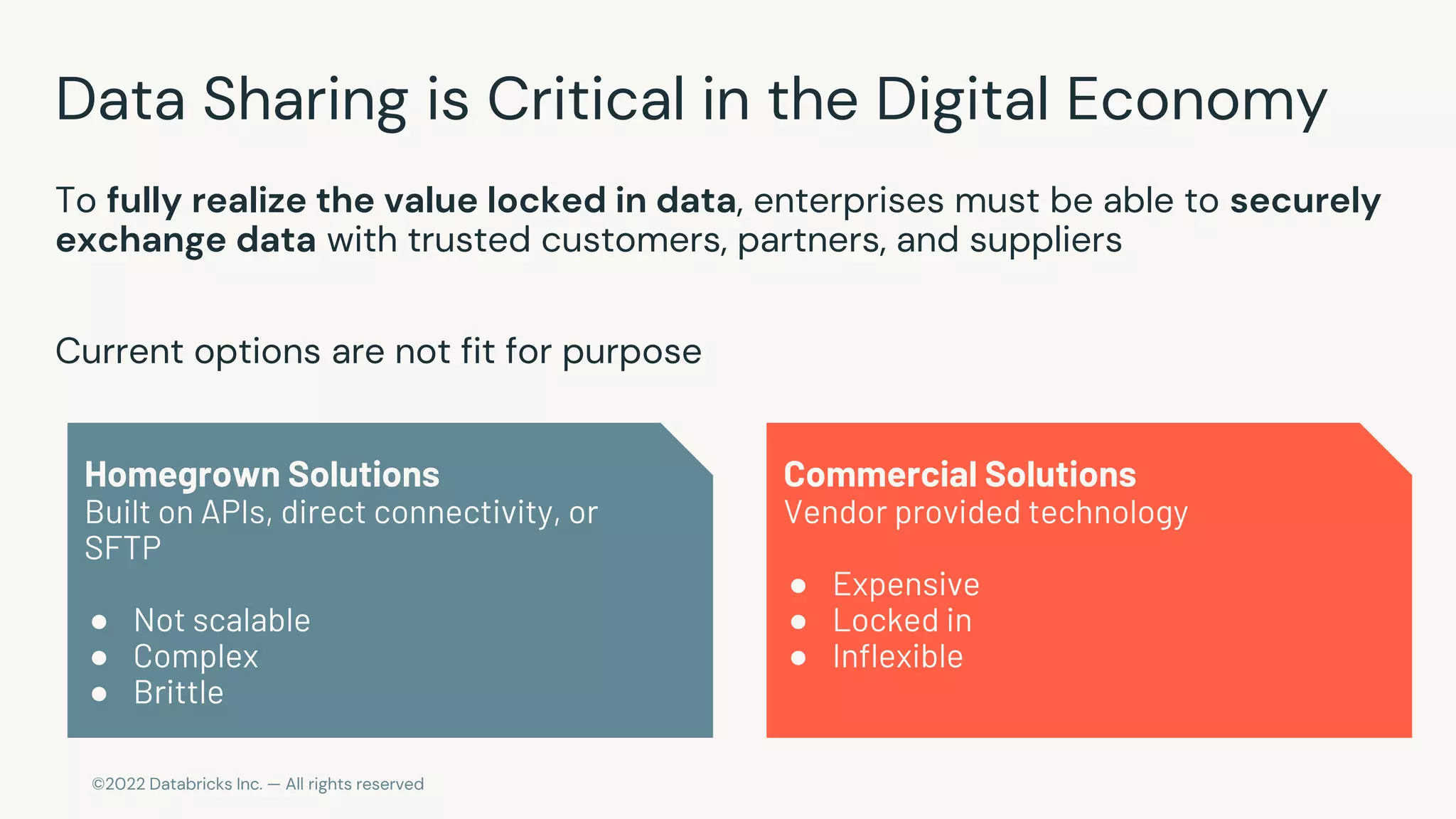






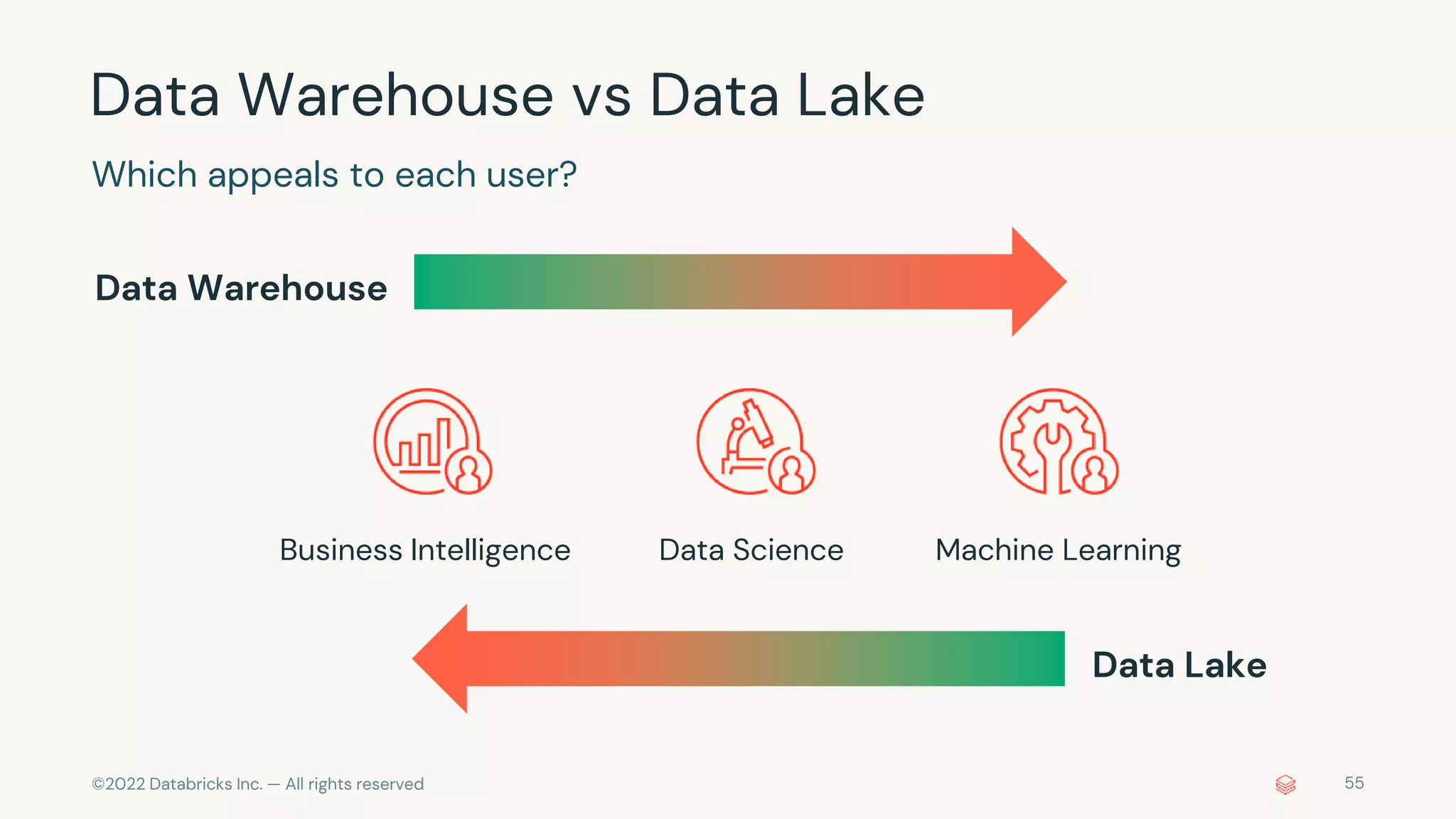





















The document discusses the challenges of modern data, analytics, and AI workloads. Most enterprises struggle with siloed data systems that make integration and productivity difficult. The future of data lies with a data lakehouse platform that can unify data engineering, analytics, data warehousing, and machine learning workloads on a single open platform. The Databricks Lakehouse platform aims to address these challenges with its open data lake approach and capabilities for data engineering, SQL analytics, governance, and machine learning.













![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DSC Europe 23] Milos Solujic - Data Lakehouse Revolutionizing Data Managemen...](https://cdn.slidesharecdn.com/ss_thumbnails/xihnewjtu6mlbi5hbkoq-milos-solujic-data-lakehouse-revolutionizing-data-management-231129142742-90fb161d-thumbnail.jpg?width=640&height=640&fit=bounds)


















































