Downloaded 449 times


![About Me
Richard L Garris
• rlgarris@databricks.com
• @rlgarris [Twitter]
Big Data Solutions Architect @ Databricks
12+ years designing Enterprise Data Solutions for everyone from
startups to Global 2000
Prior Work Experience PwC, Google, Skytree
Ohio State Buckeye and CMU Alumni
2](https://image.slidesharecdn.com/bayareasparkmeetupsapjune302016-160706192856/85/Apache-Spark-Model-Deployment-2-320.jpg)




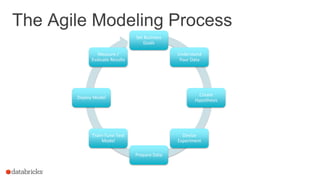
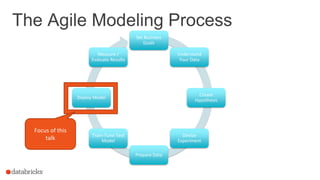
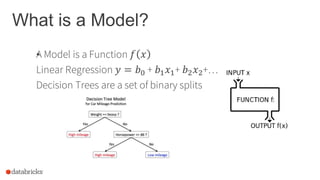

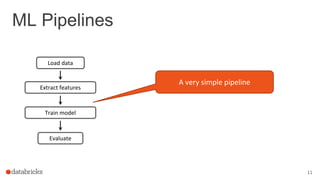
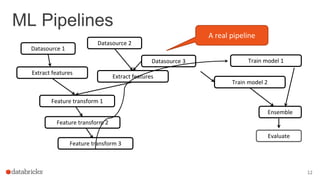
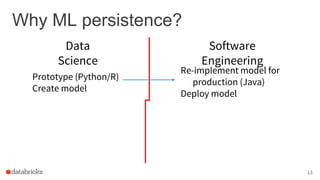
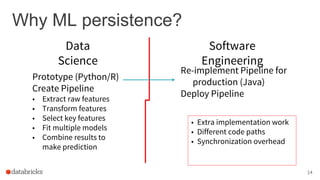
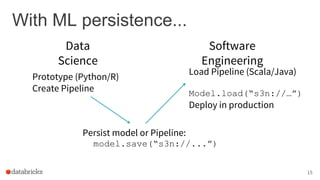







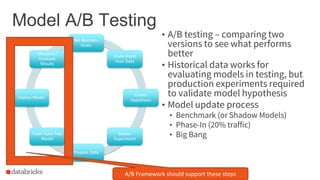

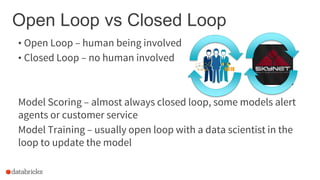


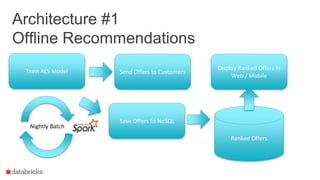
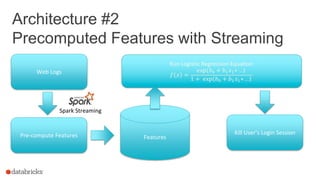
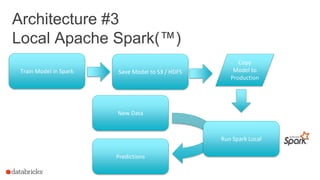




The document discusses the deployment of Apache Spark models, covering tools and libraries such as MLlib and Spark ML for building scalable machine learning models. It emphasizes the agile modeling process, the importance of model governance, monitoring, and considerations for model scoring and architecture choices. Additionally, it highlights the need for proper model persistence and deployment strategies in production environments.











































































































