Download as PDF, PPTX




![Run as many queries as possible in parallel on top a
denormalized dataframe
• foo = 1
Query 1
• bar.baz > 120
Query 2
• state in [CA, NY]
Query 3
Query 1000
ProfileIds field1 field1000 eventsArray
a@a.com a x [e1,2,3]
b@g.com b x [e1]
d@d.com d y [e1,2,3]
z@z.com z y [e1,2,3,5,7]](https://image.slidesharecdn.com/298yeshwanthvijayakumar-210616155314/75/Redis-Apache-Spark-Swiss-Army-Knife-Meets-Kitchen-Sink-5-2048.jpg)




![Session Workflow – Spark
Continuous Session
10
Submit
Query API
Spark Driver
Executor 1
Executor N
Fetch
Results
Executor Logic
API
1. POST /preview
2. Check if result in Cache
1. GET /preview/<previewID> 2. Fetch Counters from Redis
3. Push <query> into queue
4. Pop queries till
queue is empty
[q1, q2, q3, q100]
Sample
Dataframe
Sample
Dataframe
partition
1
partition
2
partition
1](https://image.slidesharecdn.com/298yeshwanthvijayakumar-210616155314/75/Redis-Apache-Spark-Swiss-Army-Knife-Meets-Kitchen-Sink-10-2048.jpg)

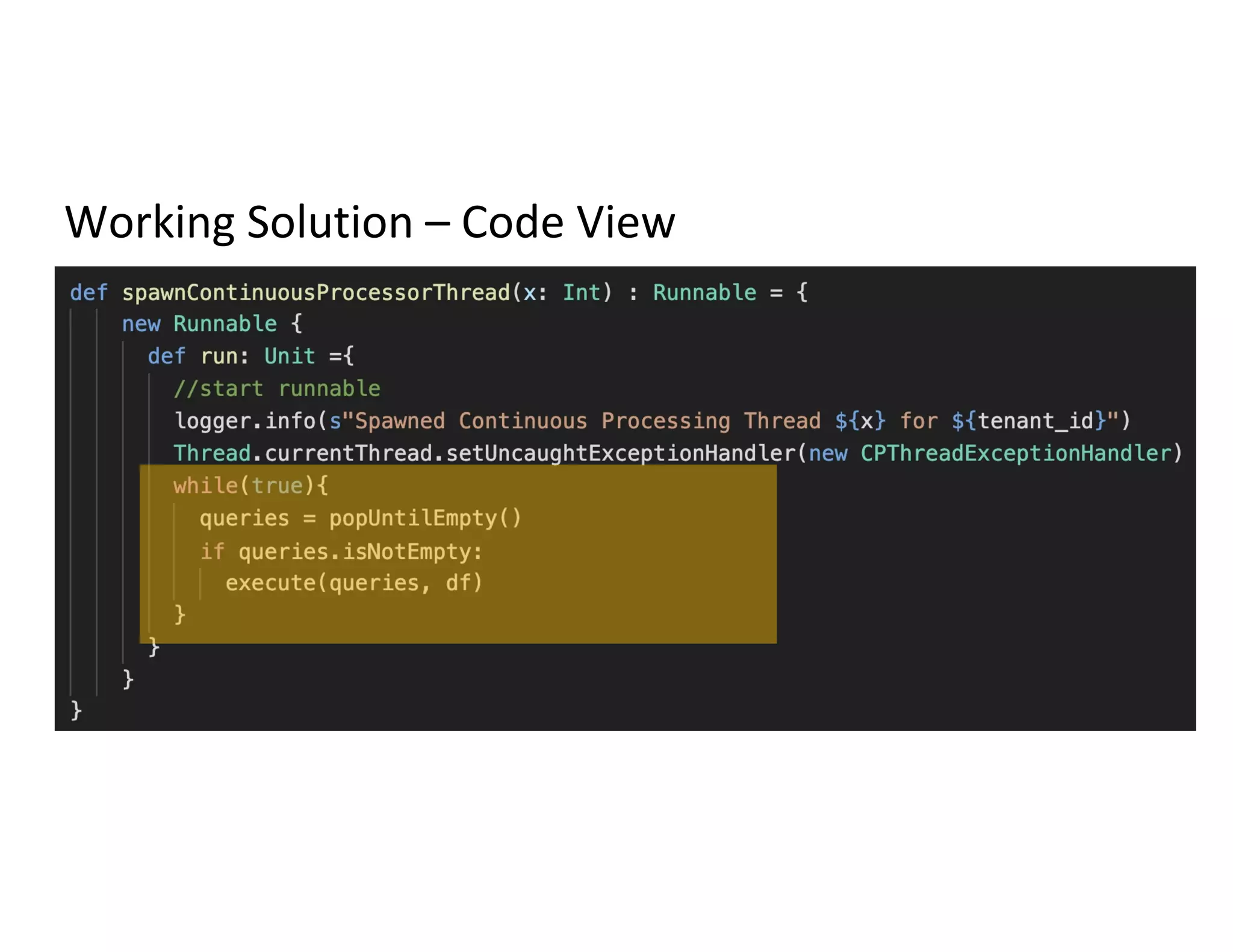
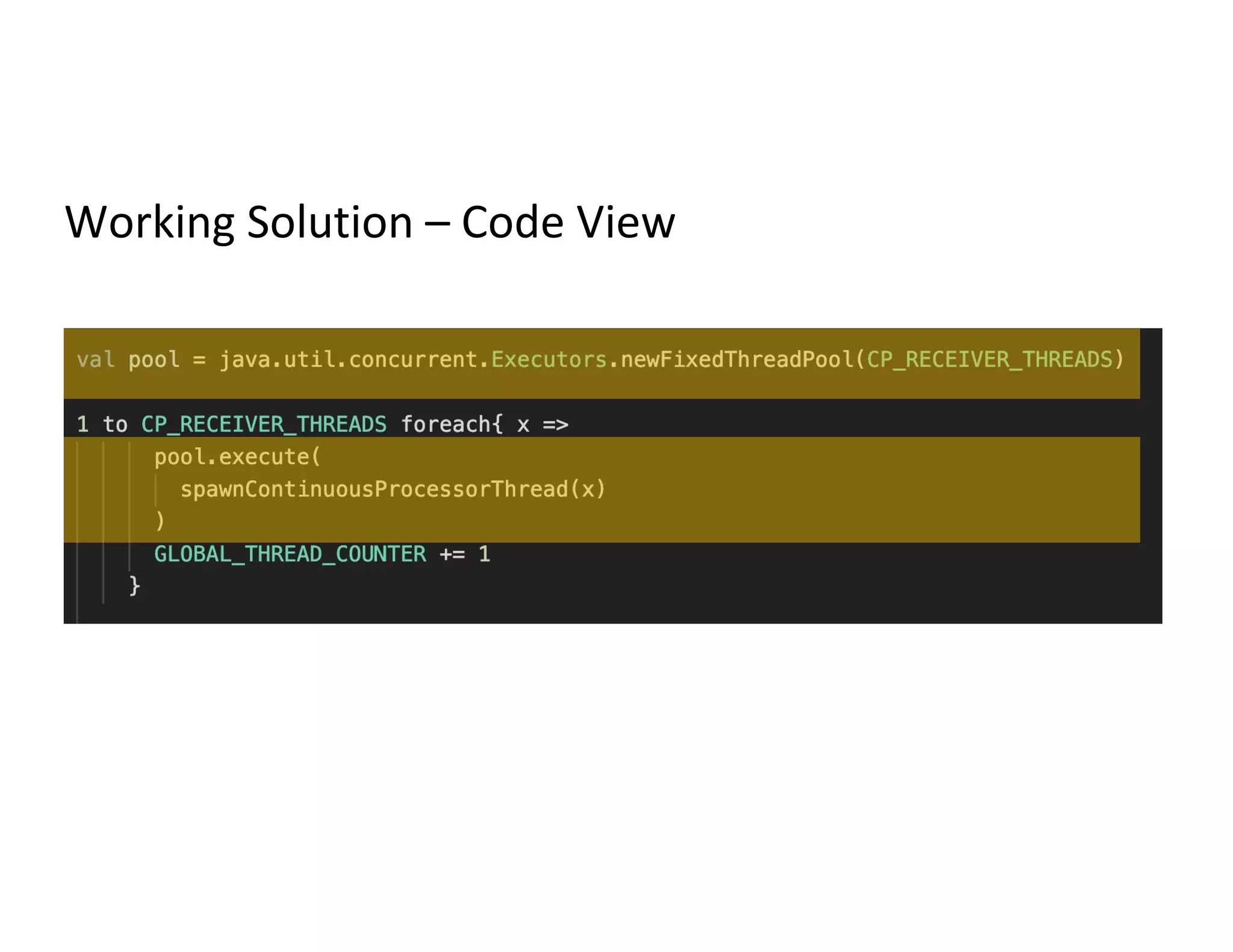





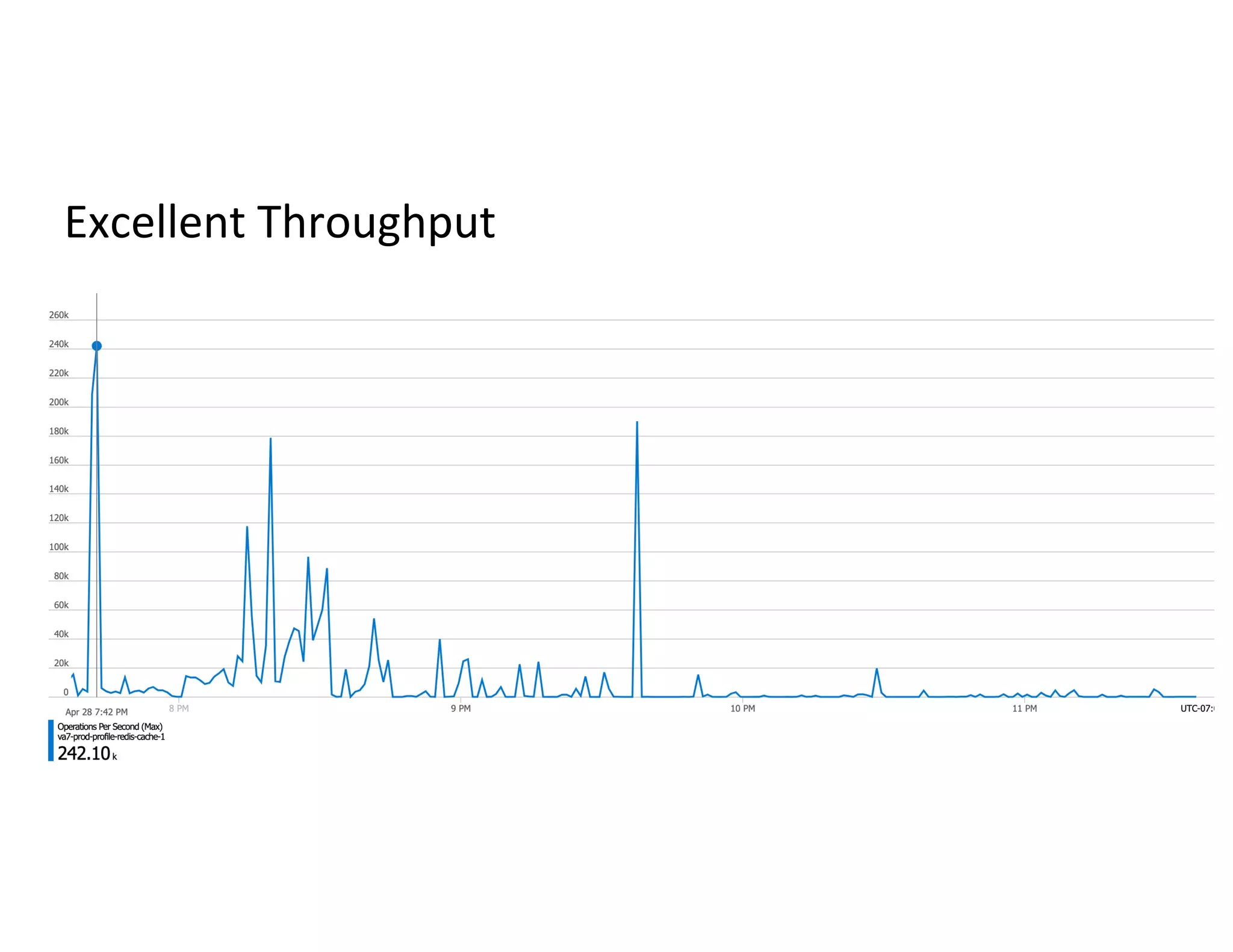





The document discusses the integration of Redis with Apache Spark for managing long-running batch jobs and distributed counters. It outlines the challenges faced in submitting queries and the inefficiencies of existing solutions, proposing a system that utilizes Redis for queuing and job status communication. Key workflows and code views are provided to demonstrate the proposed solutions for efficient query handling and data processing.




































































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)




