Downloaded 242 times



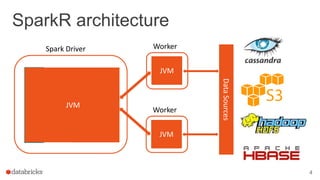
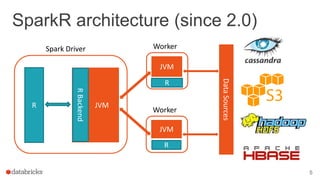

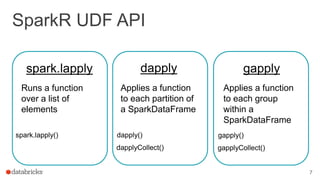

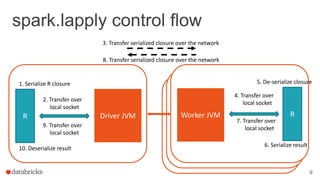
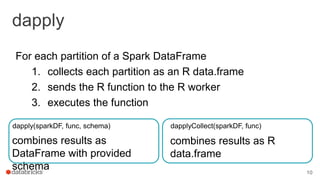
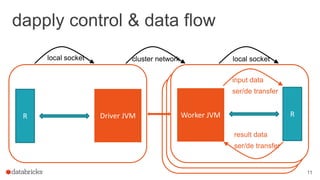
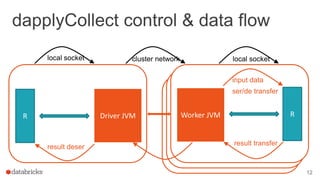

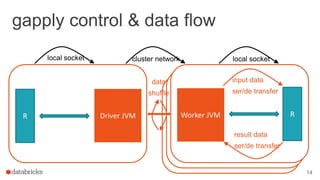






The document discusses the use of SparkR, an R package integrated with Apache Spark, which facilitates interoperability between R and Spark dataframes. It details the architecture of SparkR, its API functionalities for data manipulation and machine learning, as well as techniques for parallelizing computations with functions like spark.lapply, dapply, and gapply. The document also addresses considerations for debugging and managing package installations on SparkR workers.






























![[Sneak Preview] Apache Spark: Preparing for the next wave of Reactive Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/coll-report-typesafe-apache-spark-slide-share-150127023731-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)
![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)












