Download as PDF, PPTX



![Background: What is an RDD?
• Dependencies
• Partitions
• Compute function: Partition => Iterator[T]
3](https://image.slidesharecdn.com/sparksummiteast-sparksql-170209223852/85/SparkSQL-A-Compiler-from-Queries-to-RDDs-3-320.jpg)
![Background: What is an RDD?
• Dependencies
• Partitions
• Compute function: Partition => Iterator[T]
4
Opaque Computation](https://image.slidesharecdn.com/sparksummiteast-sparksql-170209223852/85/SparkSQL-A-Compiler-from-Queries-to-RDDs-4-320.jpg)
![Background: What is an RDD?
• Dependencies
• Partitions
• Compute function: Partition => Iterator[T]
5
Opaque Data](https://image.slidesharecdn.com/sparksummiteast-sparksql-170209223852/85/SparkSQL-A-Compiler-from-Queries-to-RDDs-5-320.jpg)




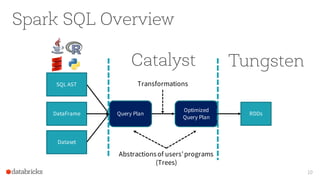
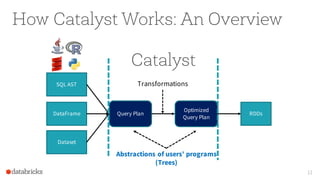


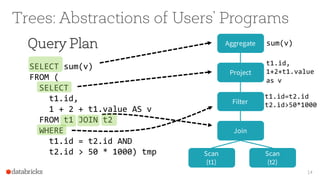
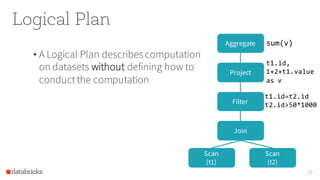
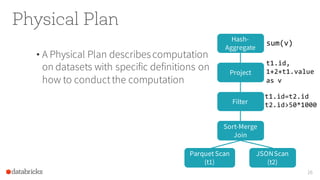
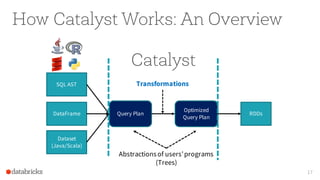
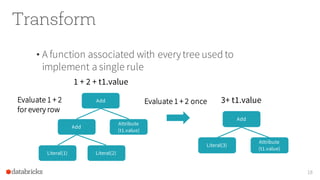

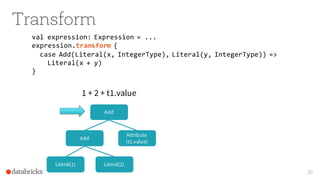
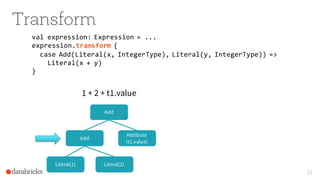
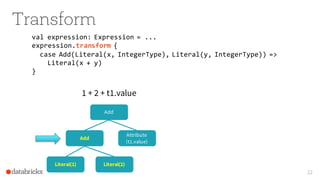
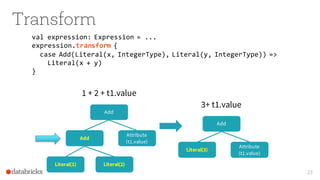
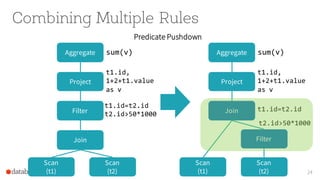
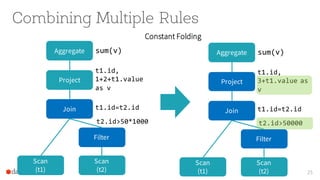
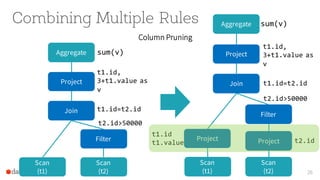
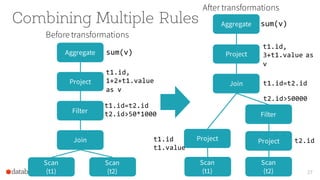
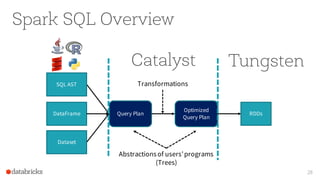
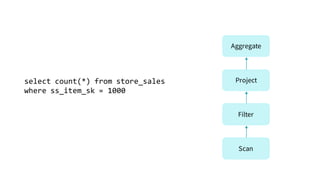







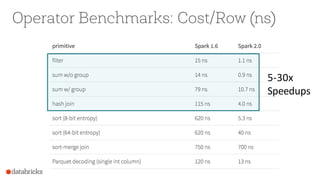
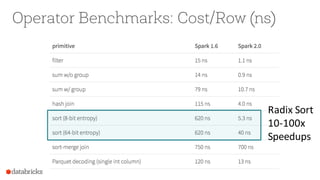
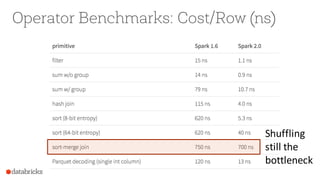
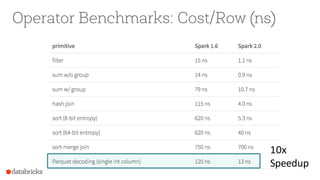
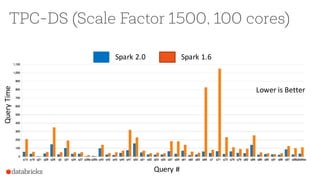




The document presents an overview of SparkSQL, detailing its transformation from queries to Resilient Distributed Datasets (RDDs) and discussing the effective use of high-level APIs for optimized query execution. It covers crucial concepts such as Abstract Syntax Trees (AST), logical and physical query plans, as well as optimization techniques like predicate pushdown and whole-stage code generation to enhance performance. Future developments for Spark include the introduction of cost-based optimizers and improvements for better performance on many-core machines.





















































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

