Downloaded 378 times




















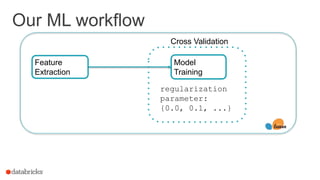
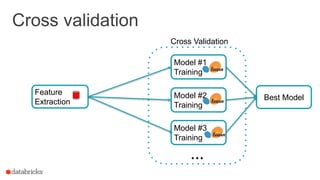
![ML Workflow
24
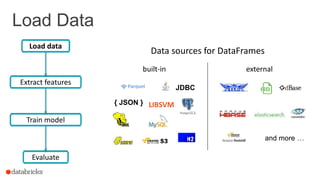
Train model
Evaluate
Load data
Extract features
Review: This product doesn't seem to be made to last… Rating: 2
feature_vector: [0.1 -1.3 0.23 … -0.74] rating: 2.0
Regression: (review: String) => Double](https://image.slidesharecdn.com/16-06-24hadoopsummit-160708174831/85/Combining-Machine-Learning-Frameworks-with-Apache-Spark-24-320.jpg)
![Extract Features
words: [this, product, doesn't, seem, to, …]
feature_vector: [0.1 -1.3 0.23 … -0.74]
Review: This product doesn't seem to be made to last… Rating: 2
Prediction: 3.0
Train model
Evaluate
Load data
Tokenizer
Hashed Term Frequ.](https://image.slidesharecdn.com/16-06-24hadoopsummit-160708174831/85/Combining-Machine-Learning-Frameworks-with-Apache-Spark-26-320.jpg)
![Extract Features
words: [this, product, doesn't, seem, to, …]
feature_vector: [0.1 -1.3 0.23 … -0.74]
Review: This product doesn't seem to be made to last… Rating: 2
Prediction: 3.0
Linear regression
Evaluate
Load data
Tokenizer
Hashed Term Frequ.](https://image.slidesharecdn.com/16-06-24hadoopsummit-160708174831/85/Combining-Machine-Learning-Frameworks-with-Apache-Spark-27-320.jpg)









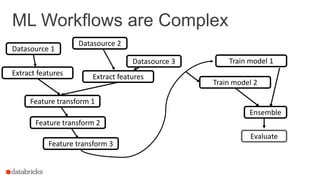
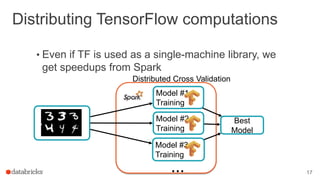
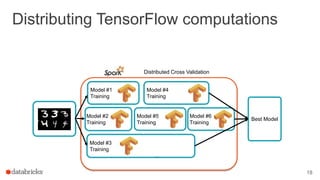
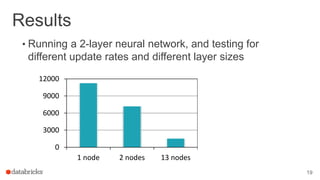
This document discusses combining machine learning frameworks with Apache Spark. It provides an overview of Apache Spark and MLlib, describes how to distribute TensorFlow computations using Spark, and discusses managing machine learning workflows with Spark through features like cross validation, persistence, and distributed data sources. The goal is to make machine learning easy, scalable, and integrate with existing workflows.



































































