Download as PDF, PPTX












![Extract features
Feature
extraction
Original
dataset
13
Predictive
model
Evaluation
Text Label Words Features
I bought the game... 4 “i",
“bought”,...
[1, 0, 3, 9, ...]
Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...]
this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...]
nevergot it.
Seller...
1 “never”, “got” [1, 2, 0, 0, ...]](https://image.slidesharecdn.com/16-06-24nycsparkmeetuptalk-160628190209/85/Distributed-ML-in-Apache-Spark-13-320.jpg)
![Fit a model
Feature
extraction
Original
dataset
14
Predictive
model
Evaluation
Text Label Words Features Prediction Probability
I bought the game... 4 “i",
“bought”,...
[1, 0, 3, 9, ...] 4 0.8
Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...] 2 0.6
this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...] 5 0.9
nevergot it.
Seller...
1 “never”, “got” [1, 2, 0, 0, ...] 1 0.7](https://image.slidesharecdn.com/16-06-24nycsparkmeetuptalk-160628190209/85/Distributed-ML-in-Apache-Spark-14-320.jpg)
![Evaluate
Feature
extraction
Original
dataset
15
Predictive
model
Evaluation
Text Label Words Features Prediction Probability
I bought the game... 4 “i",
“bought”,...
[1, 0, 3, 9, ...] 4 0.8
Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...] 2 0.6
this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...] 5 0.9
nevergot it.
Seller...
1 “never”, “got” [1, 2, 0, 0, ...] 1 0.7](https://image.slidesharecdn.com/16-06-24nycsparkmeetuptalk-160628190209/85/Distributed-ML-in-Apache-Spark-15-320.jpg)






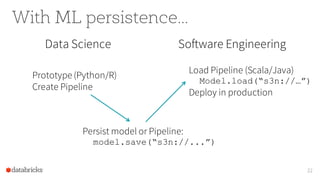









The document discusses Apache Spark, highlighting its role as a fast, easy-to-use engine for big data computing with a strong focus on machine learning (ML) support through its ML library, MLlib. It outlines common challenges in ML projects, the functionality of DataFrames for data manipulation, and key optimizations within the library. Additionally, the document outlines future developments and the collaborative community around Apache Spark.











































































































