Download as PDF, PPTX



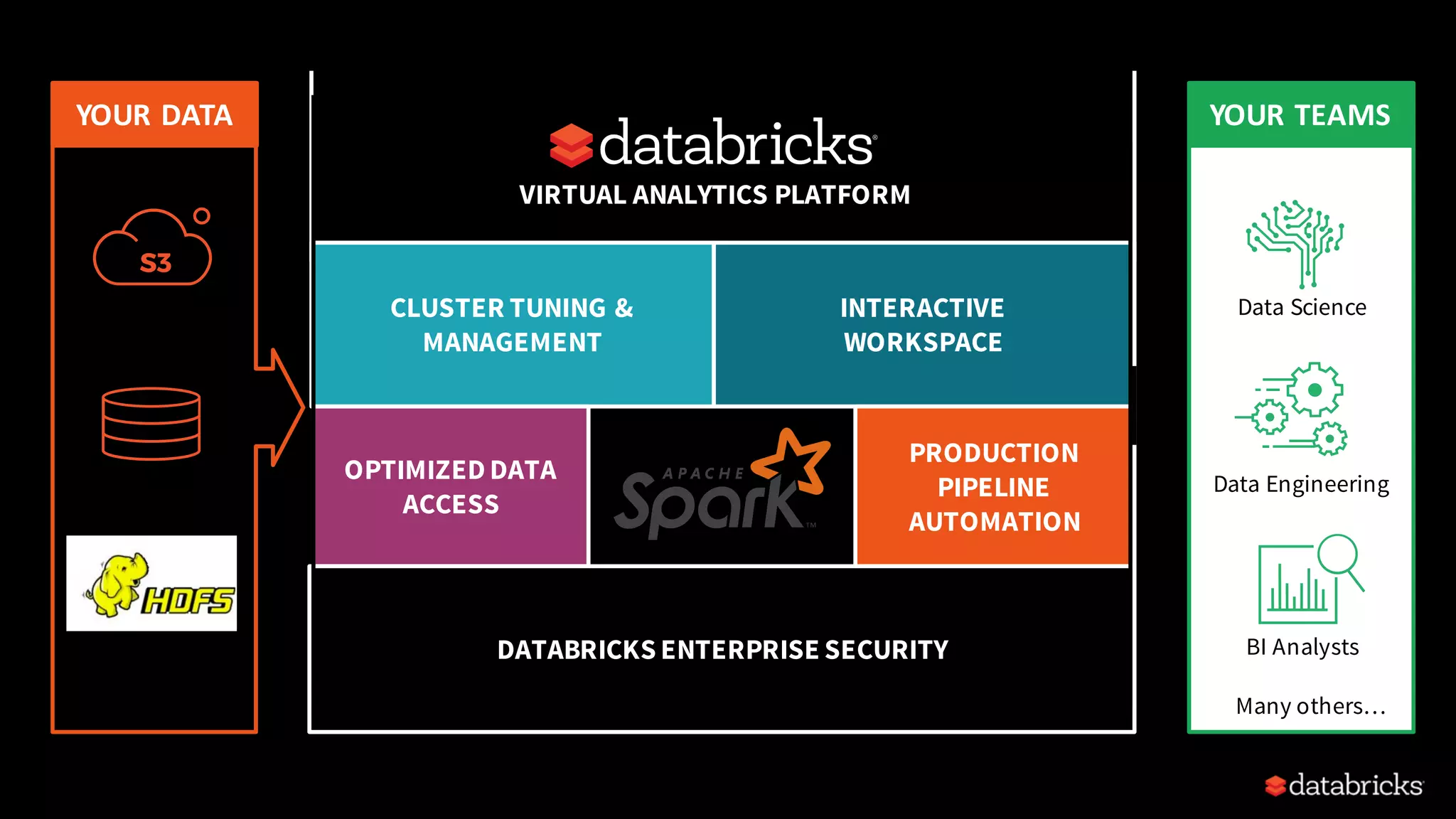






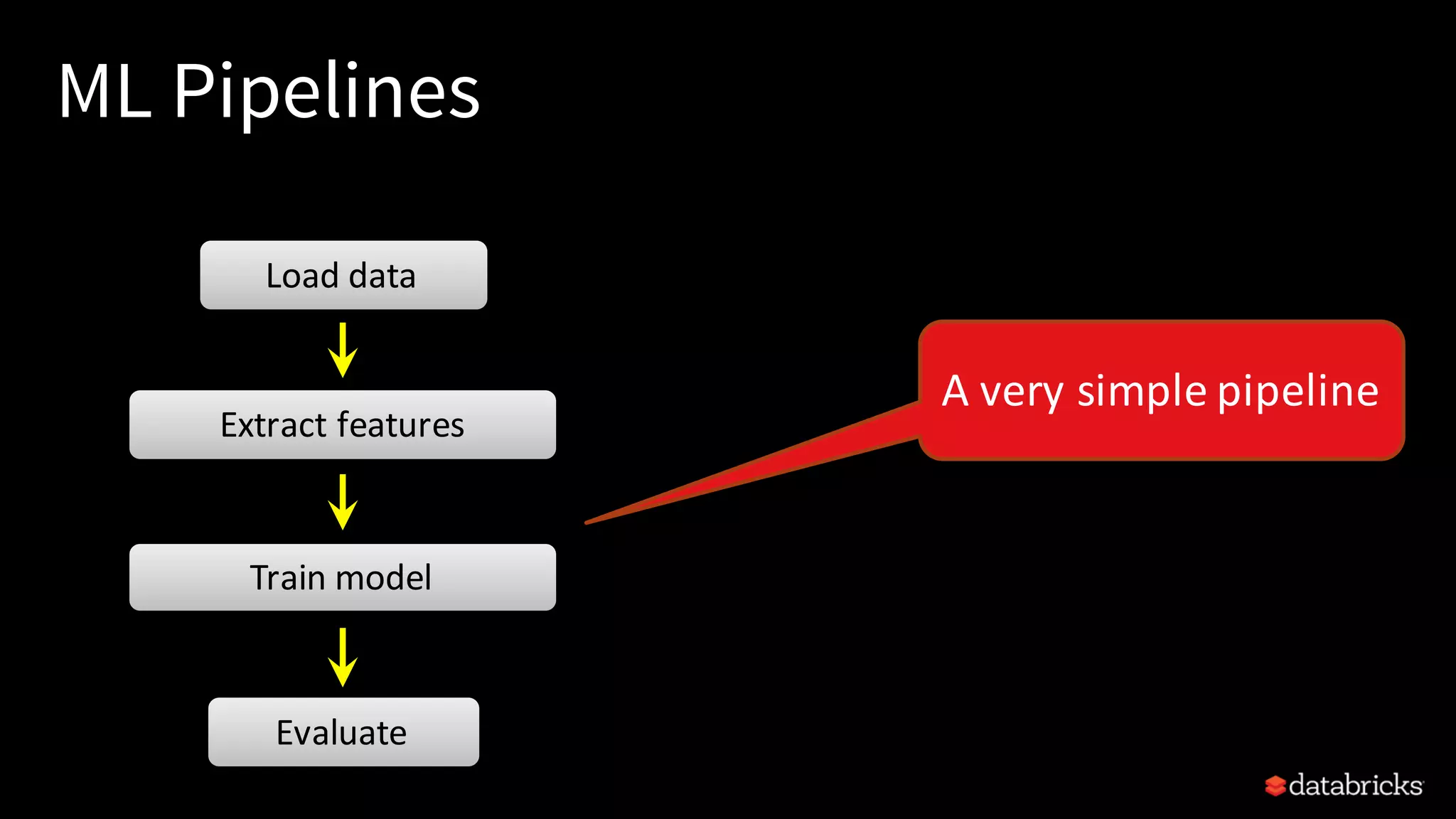
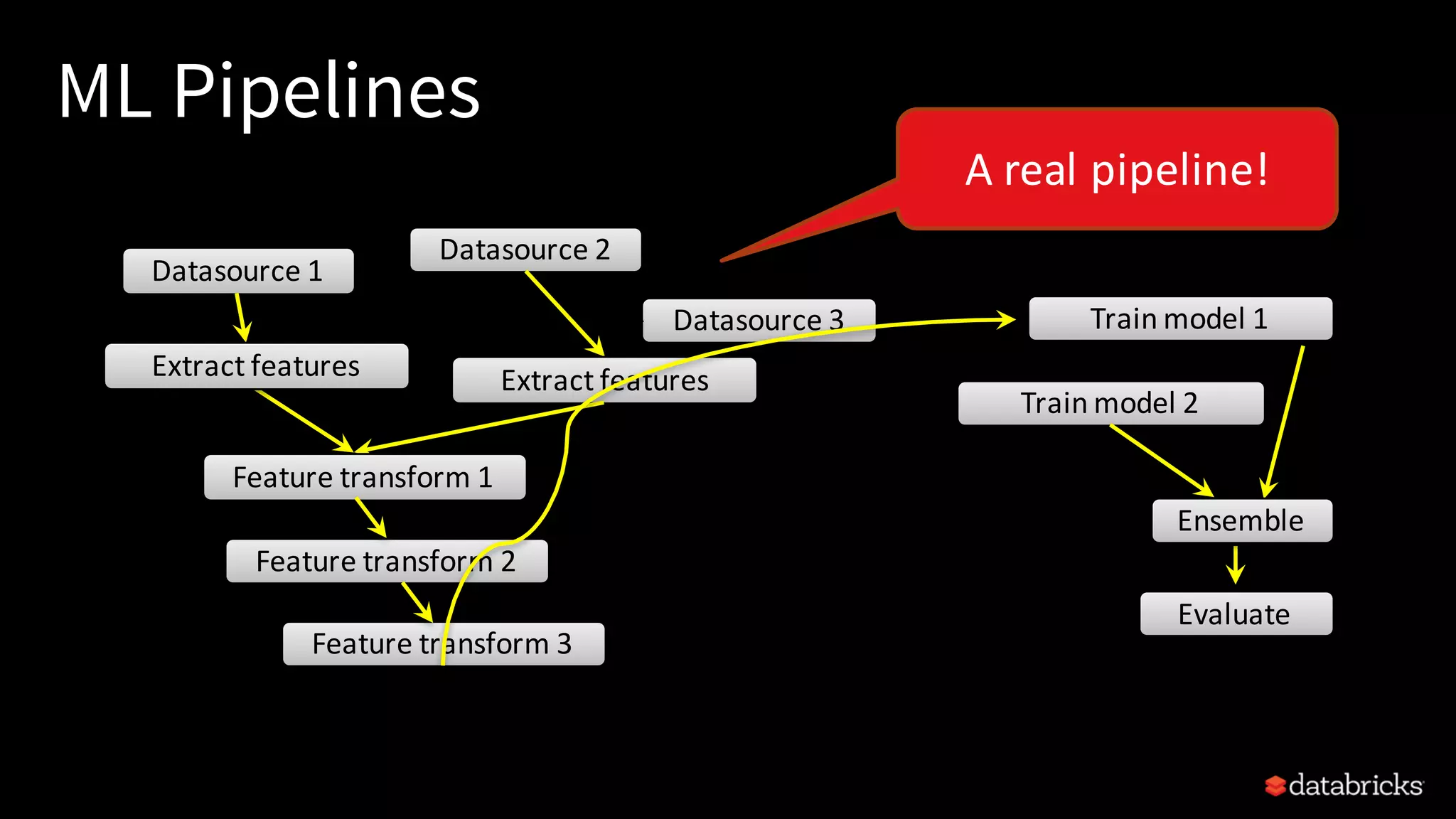
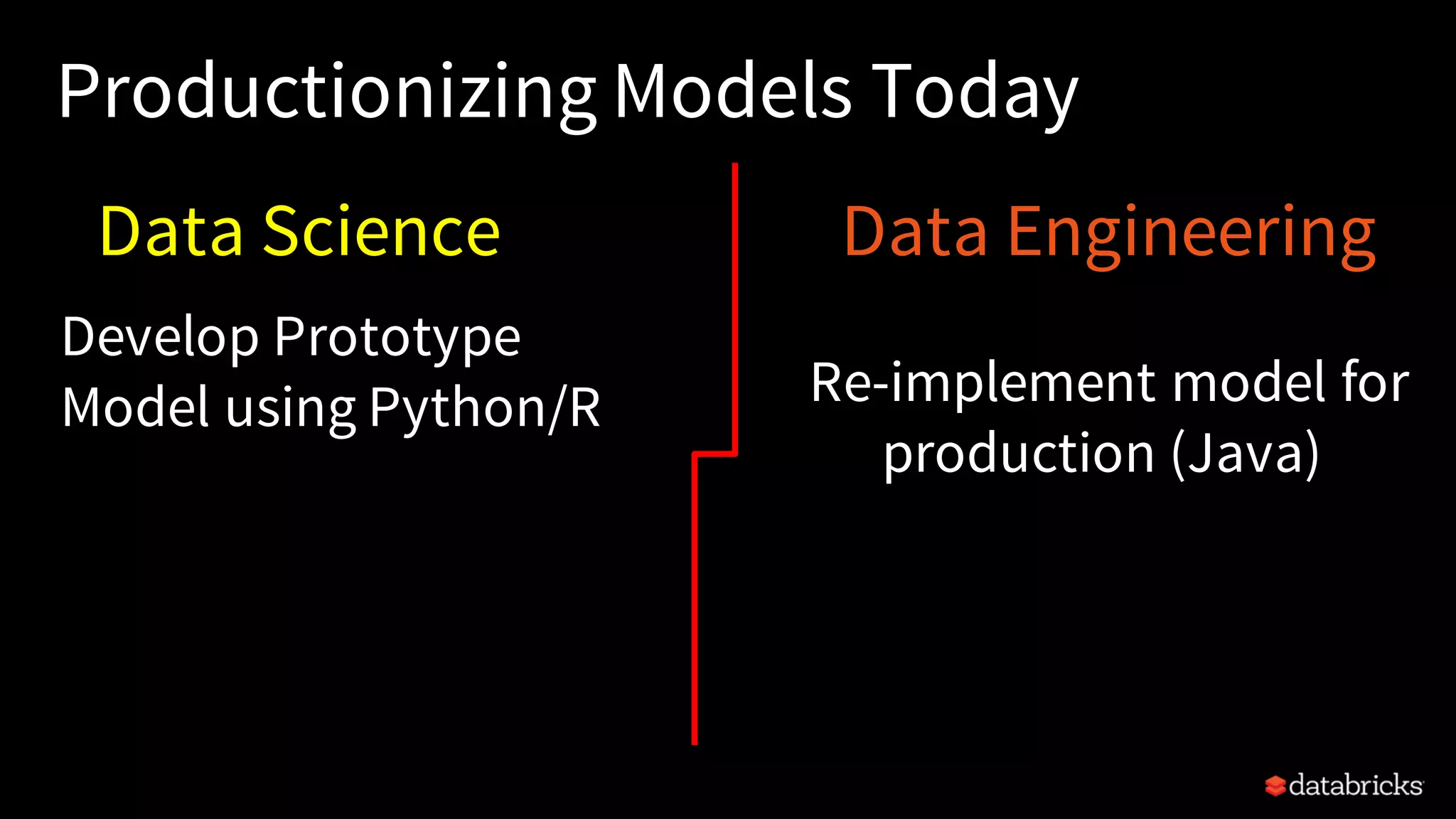
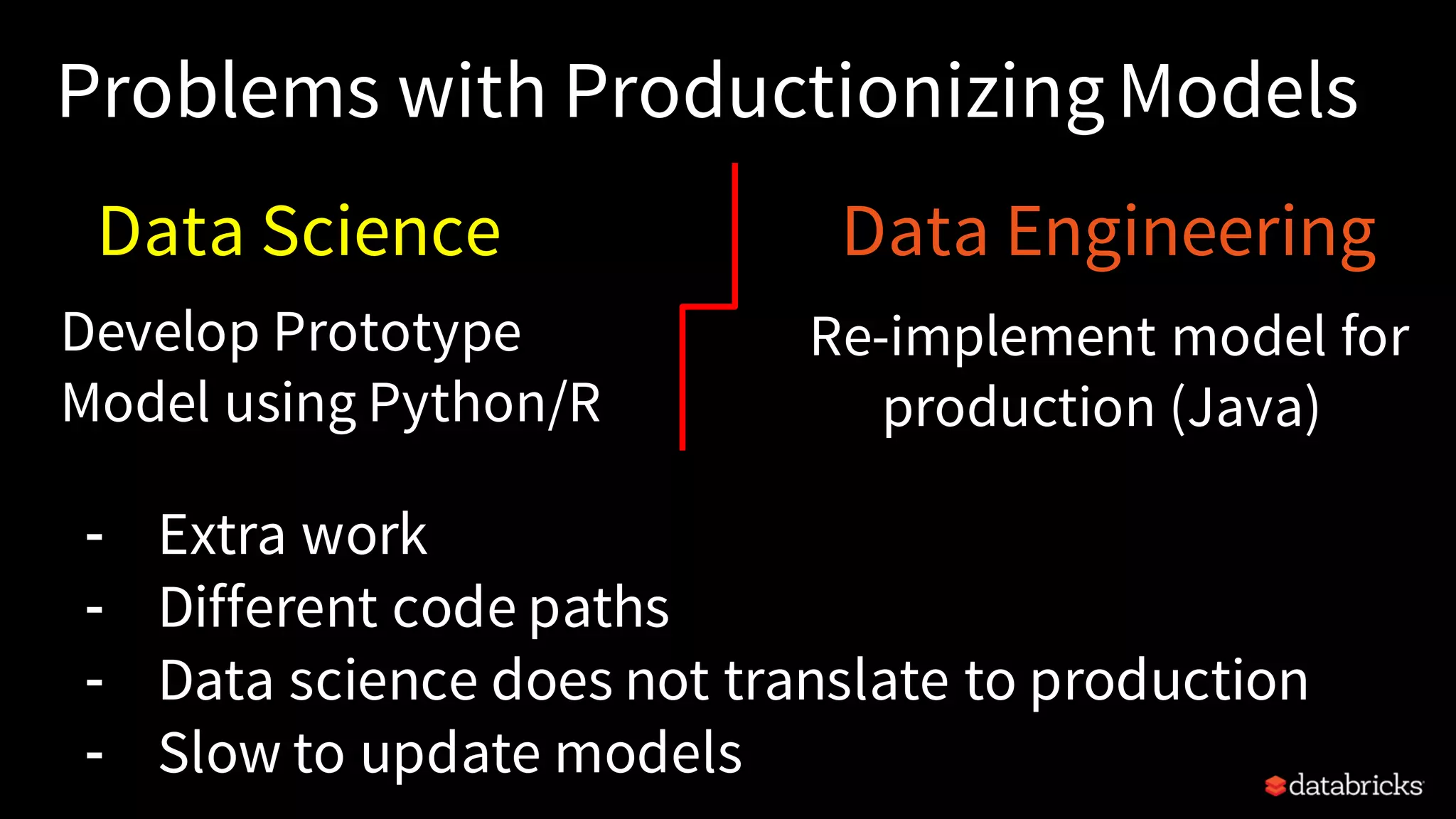


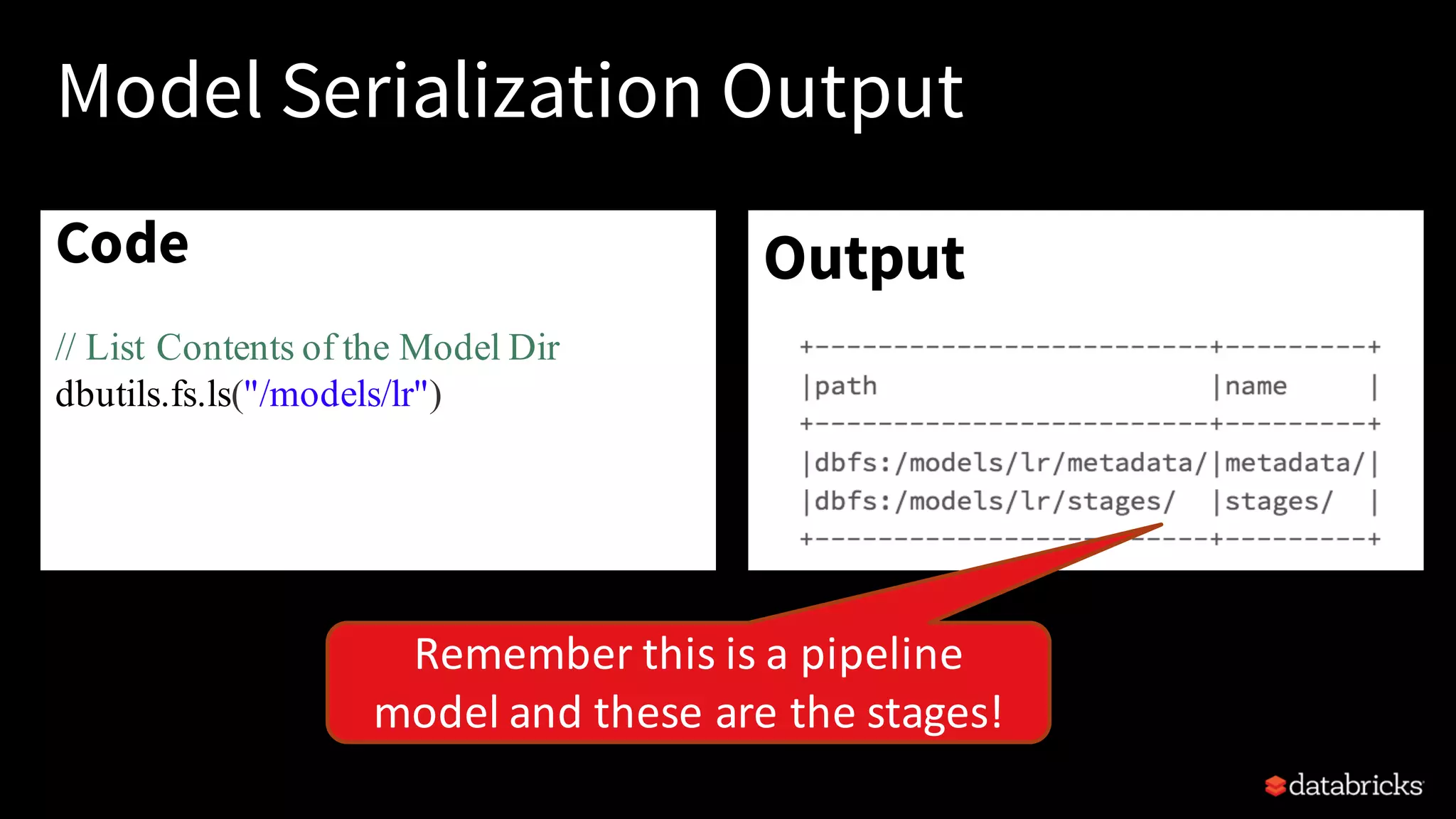


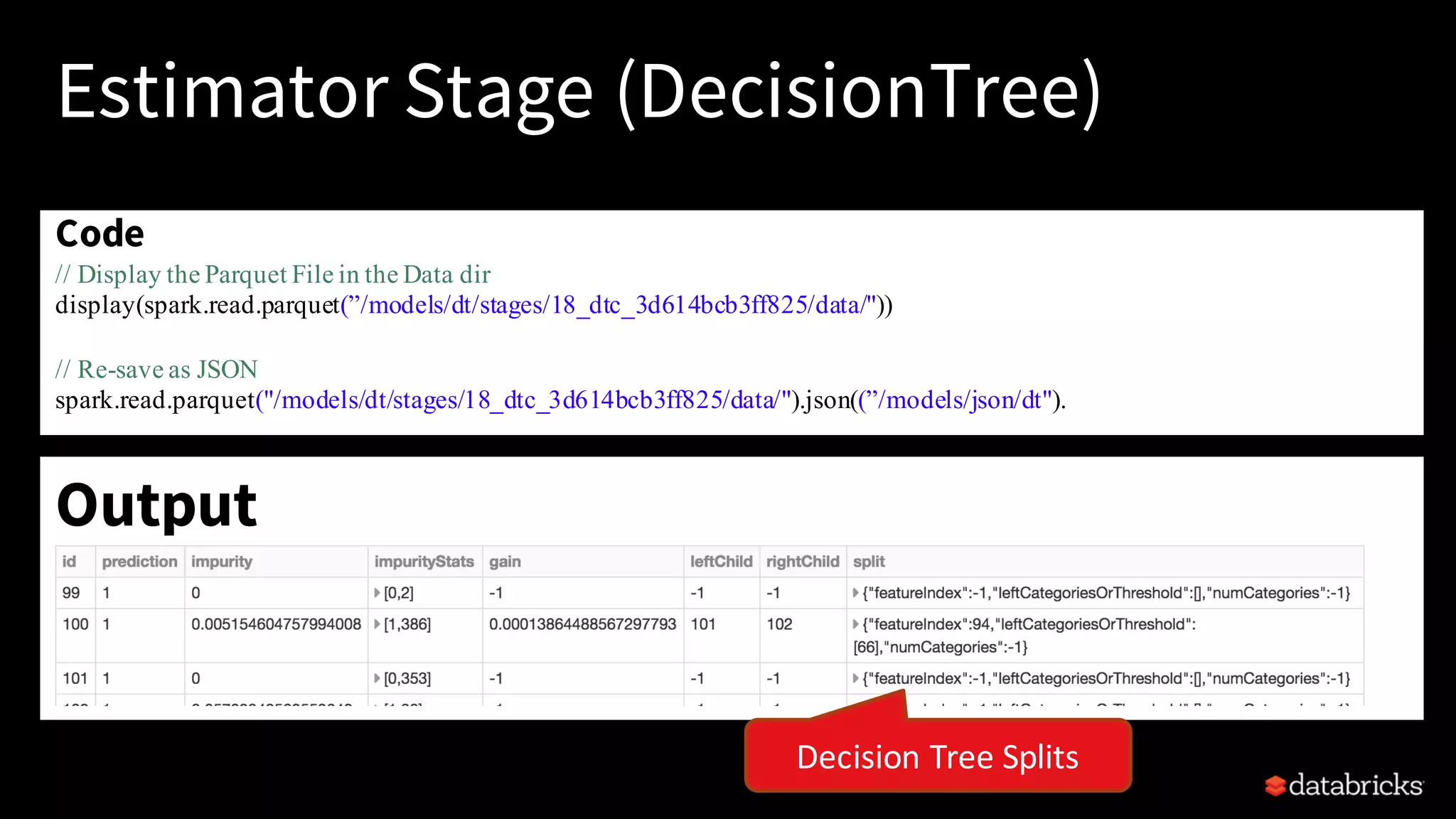
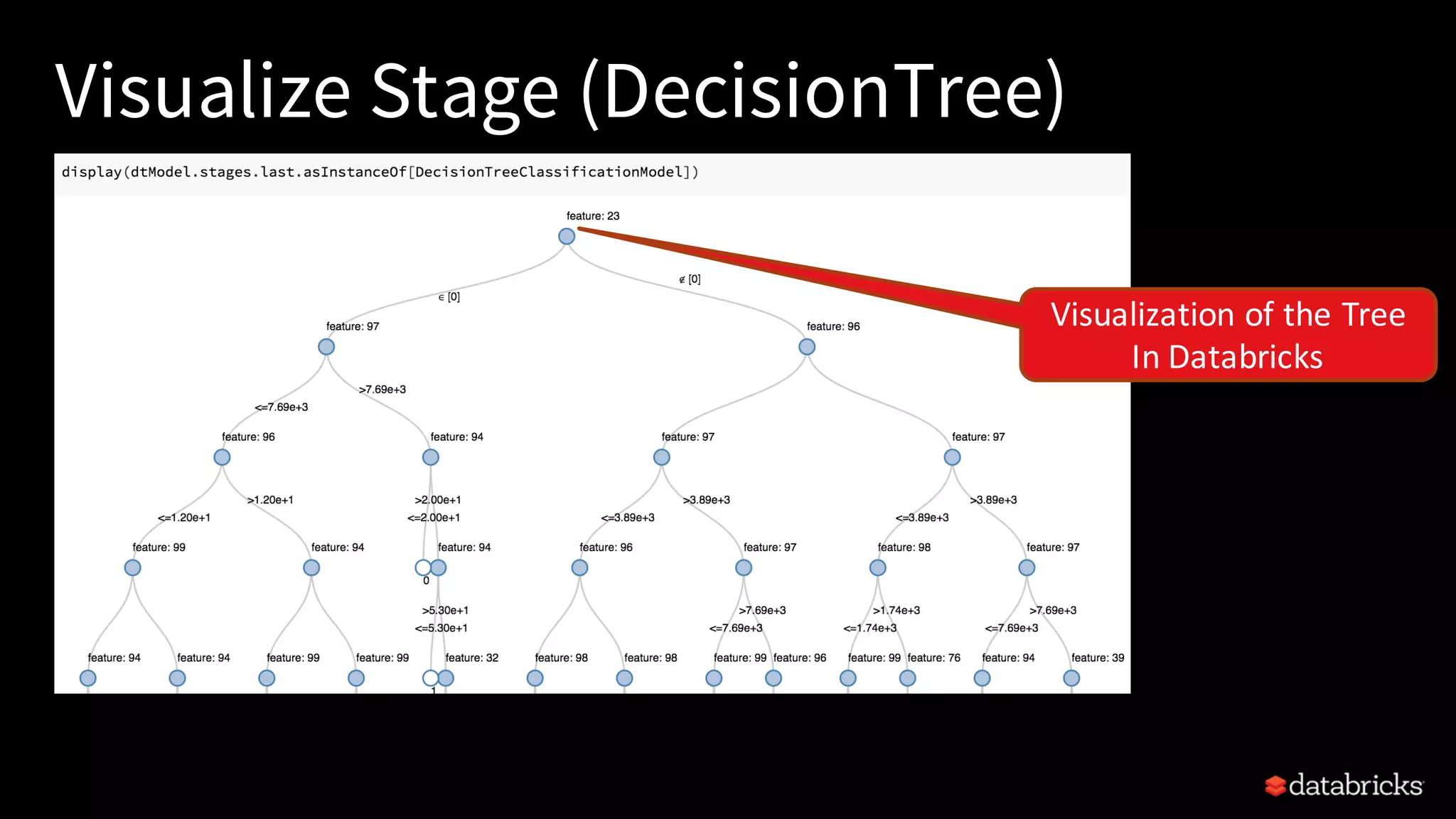


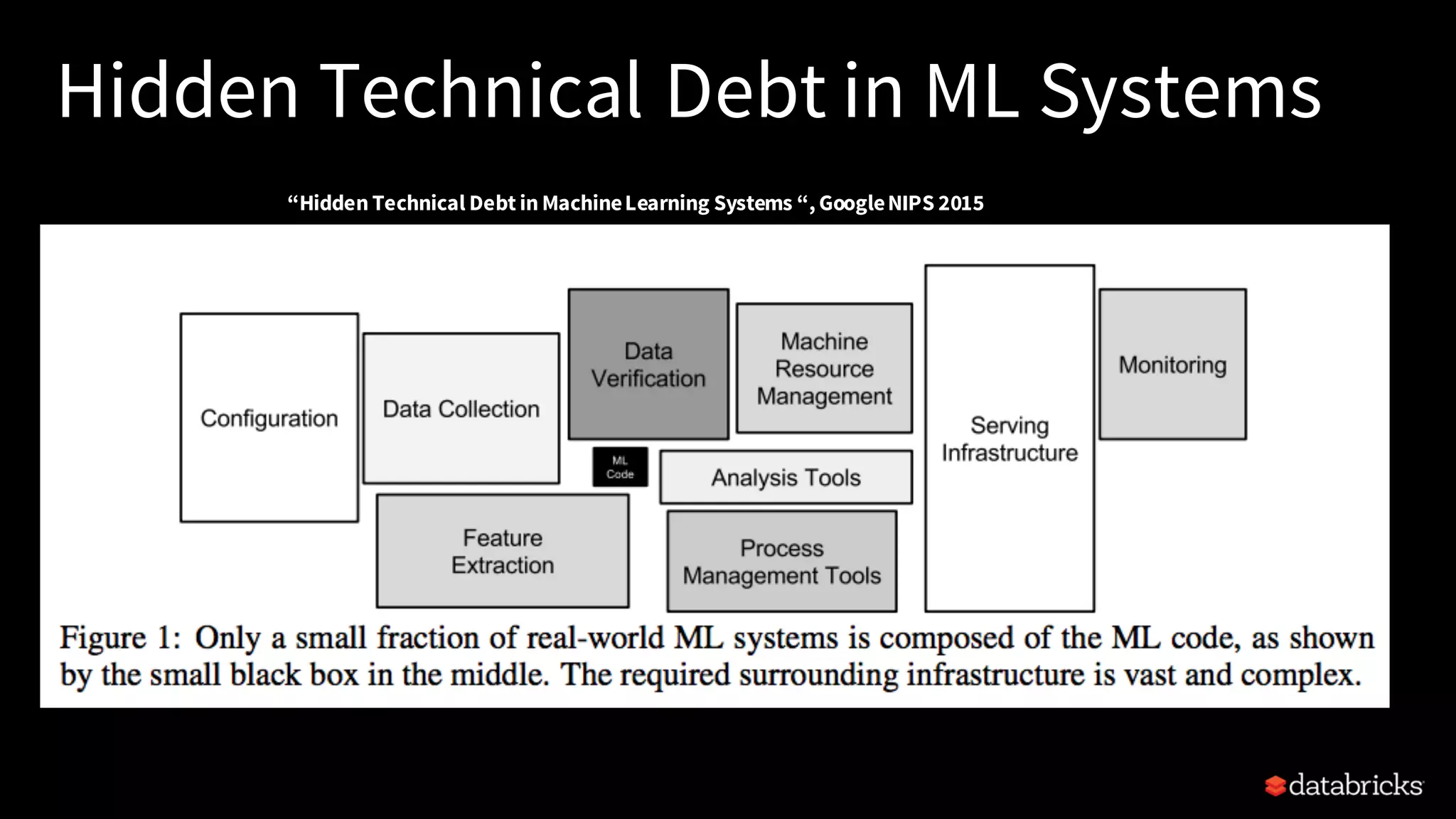
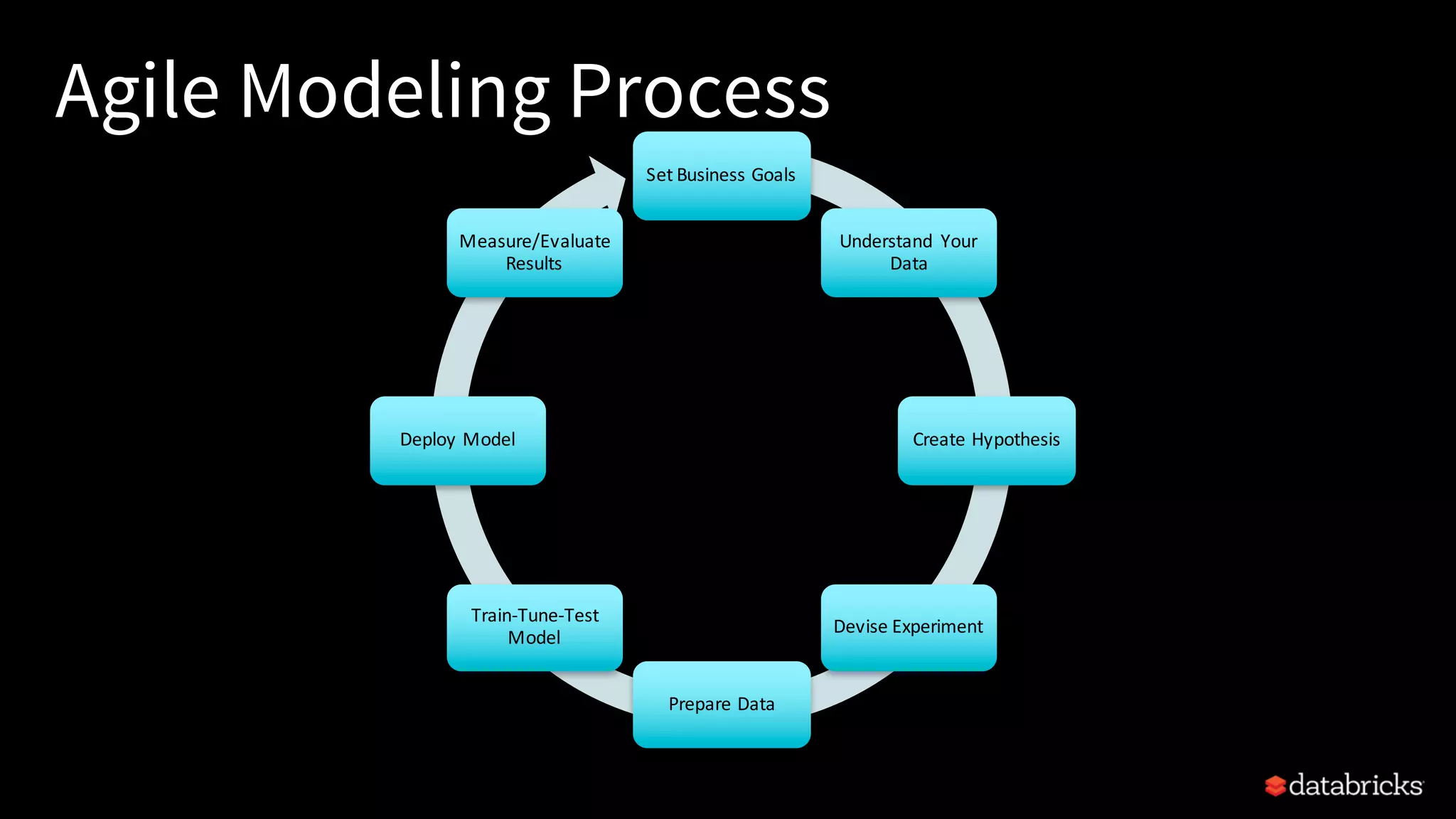
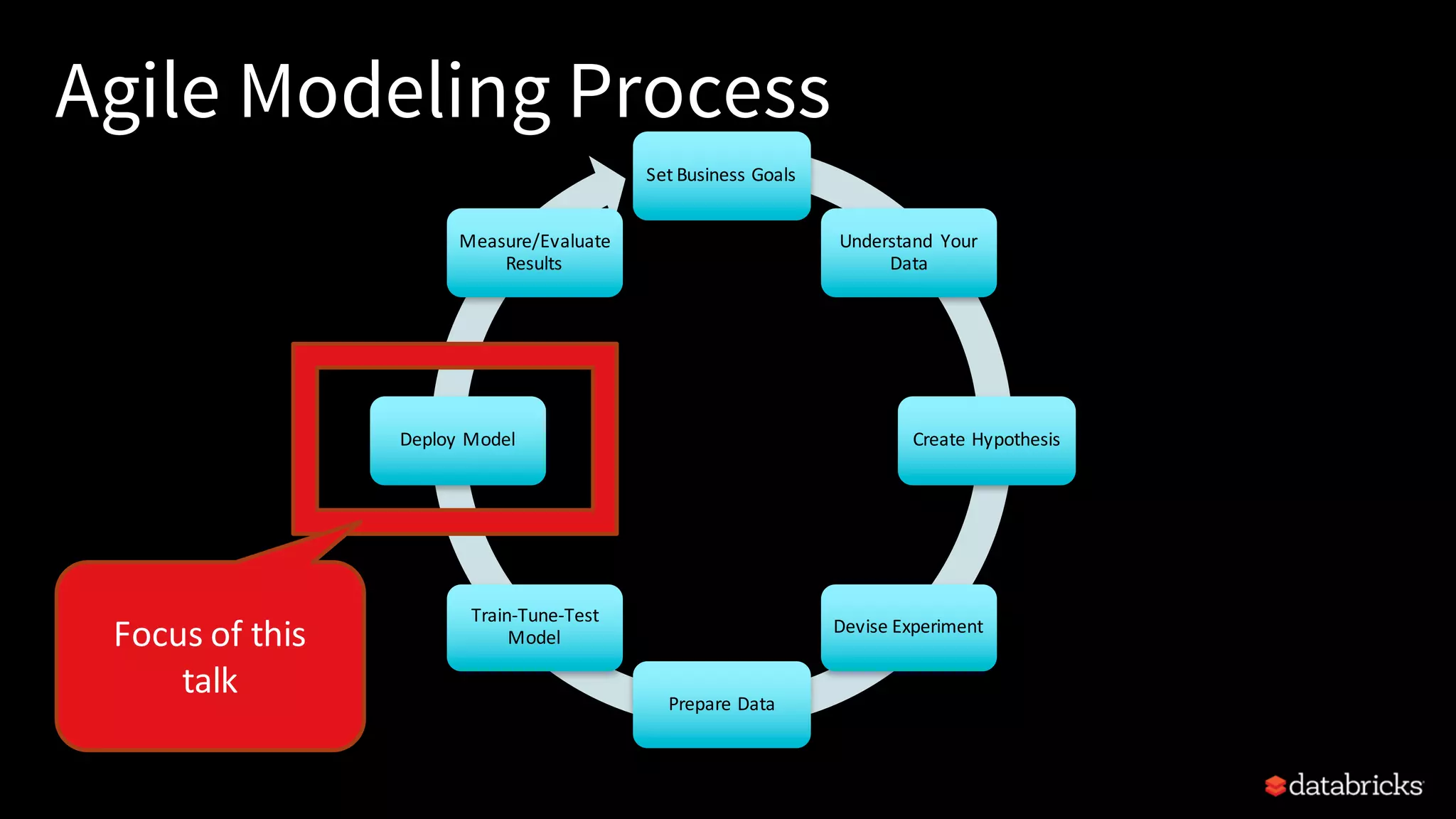
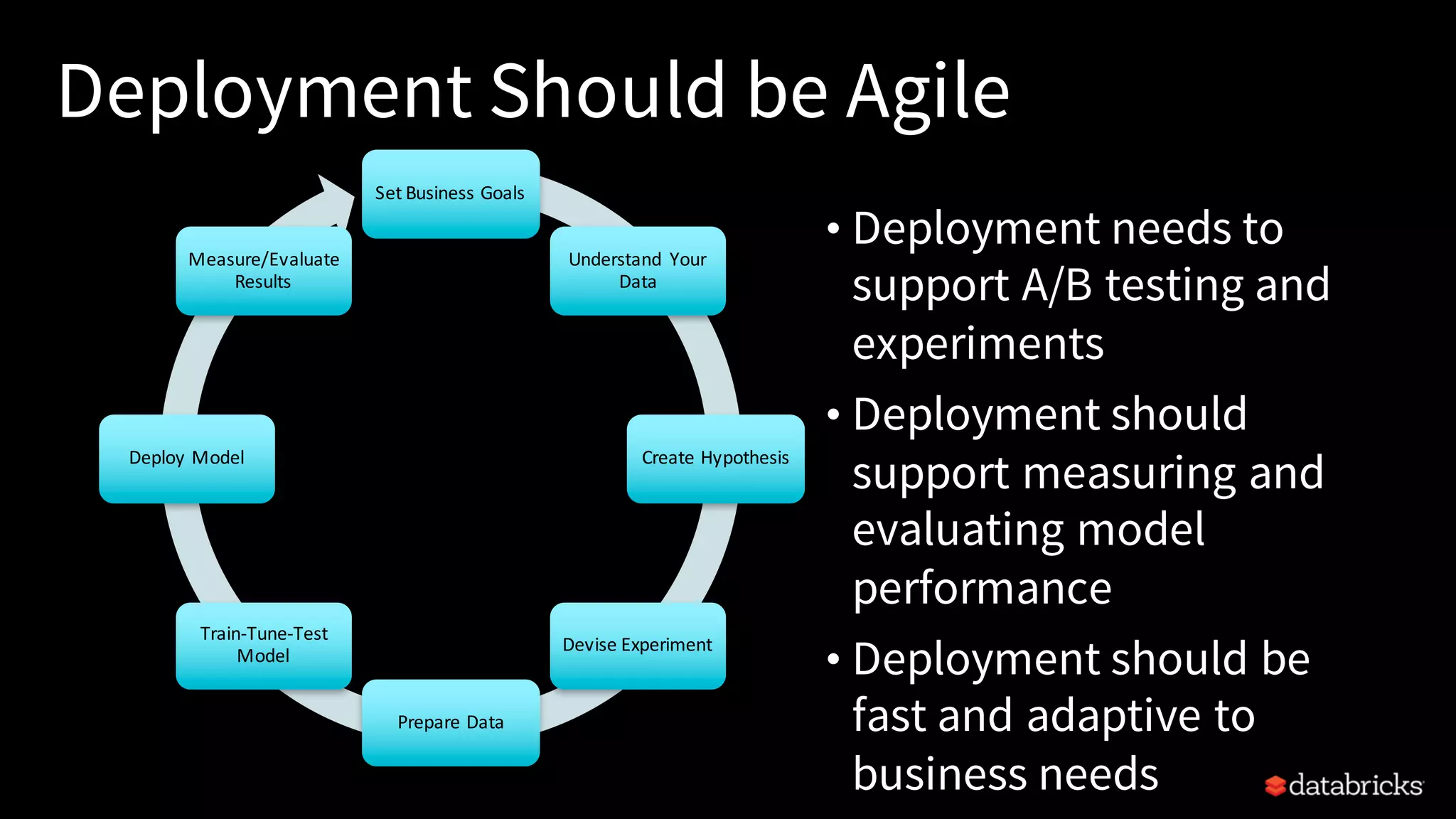







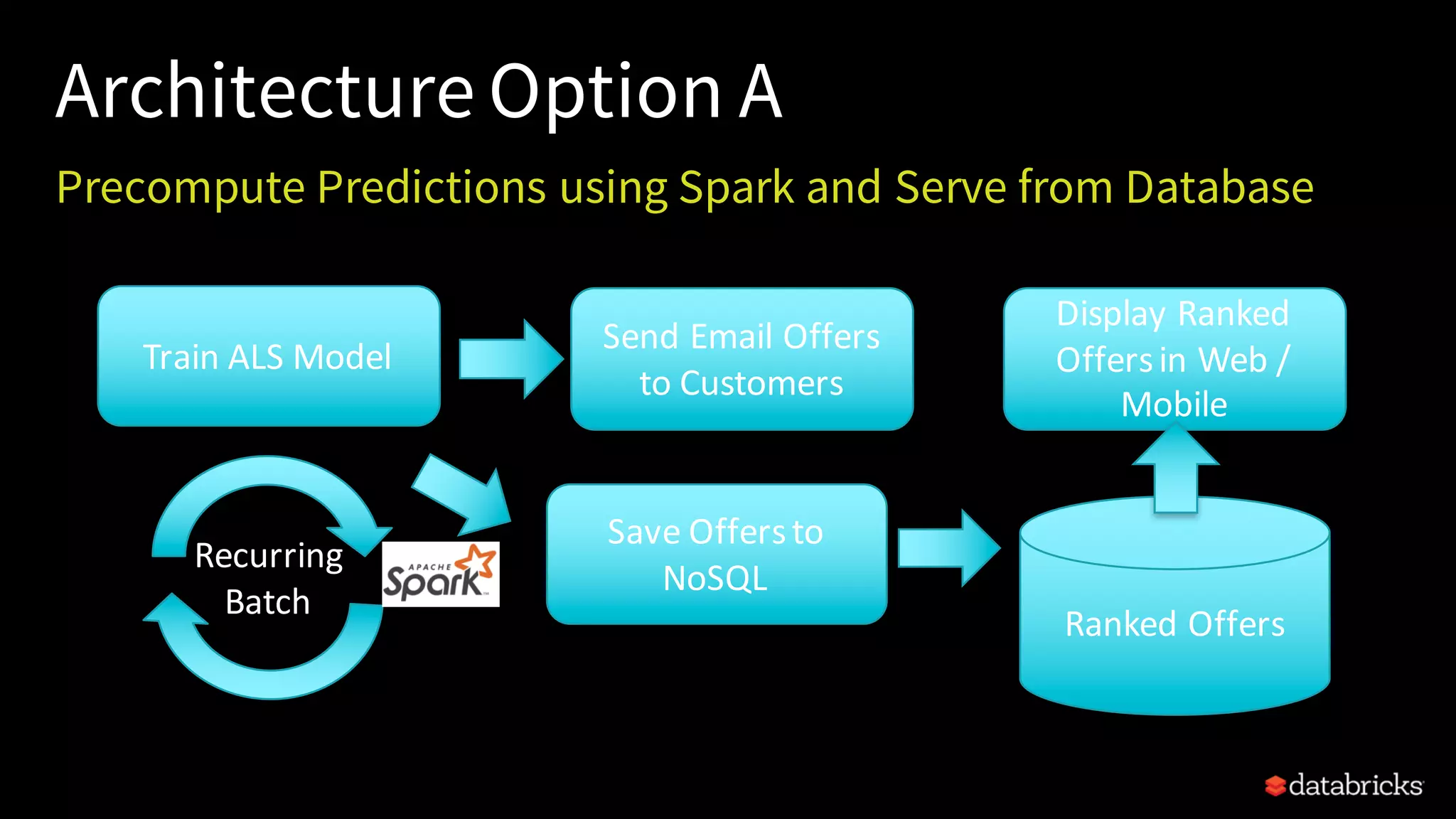
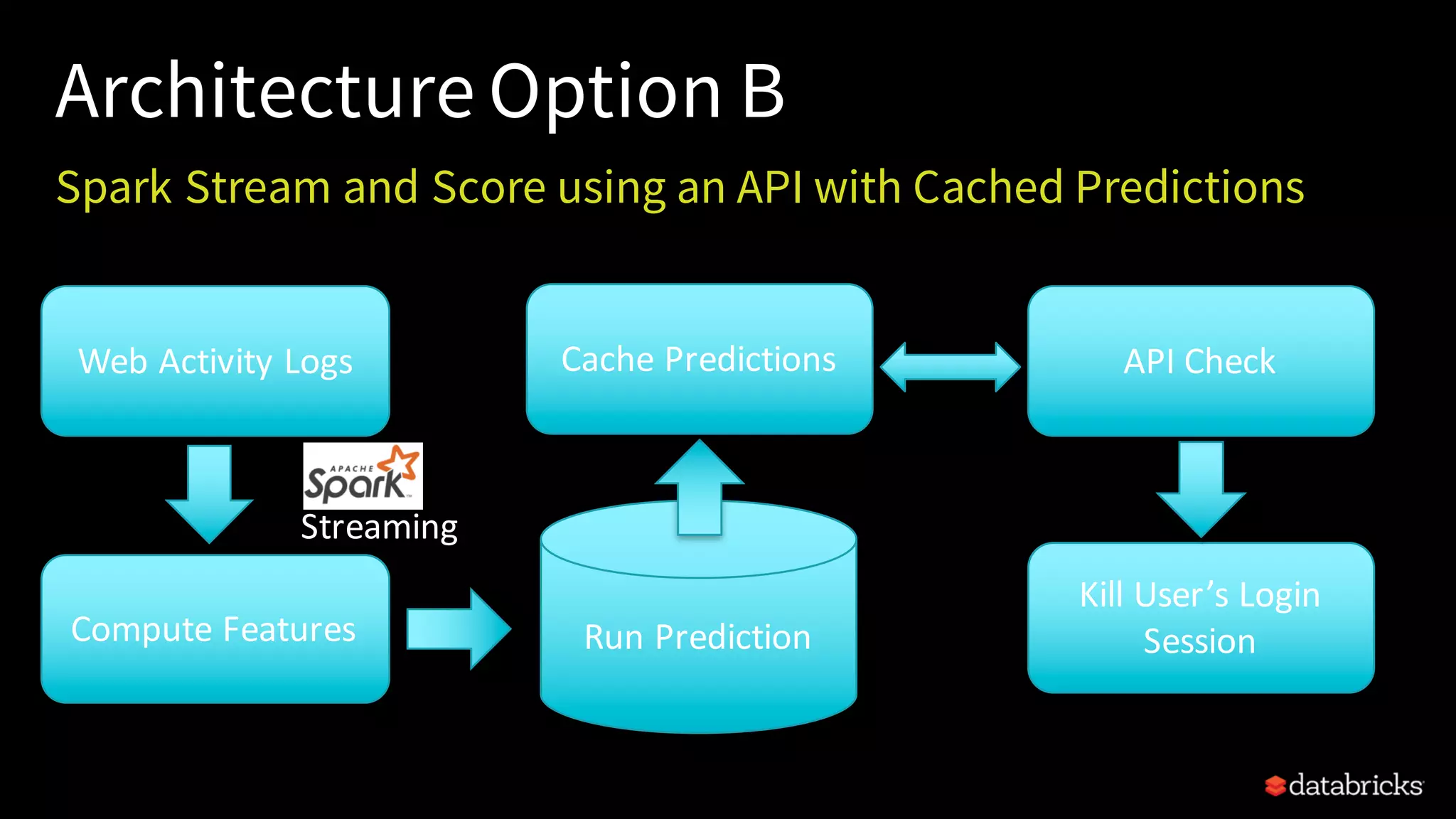
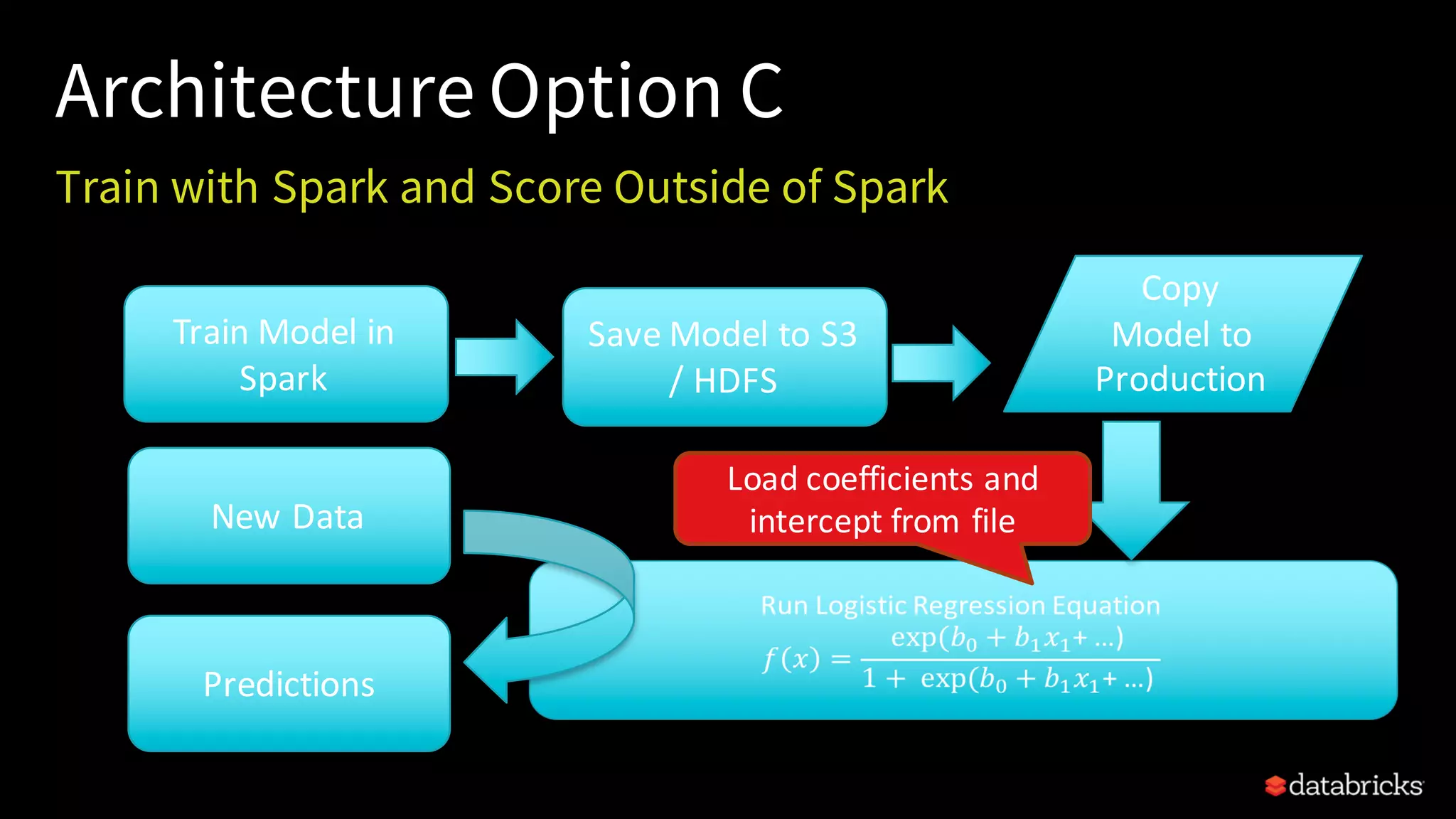







This document provides an overview of how to productionize machine learning models using Apache Spark MLlib 2.x, highlighting key concepts like model serialization, scoring architectures, and the importance of agile deployment. It discusses the evolution of Spark MLlib, its integration within data science workflows, and various deployment strategies tailored for different environments. The goal is to enable efficient model deployment that supports rapid updates and performance monitoring.















































































