Download as PDF, PPTX














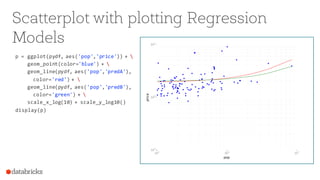
![Scatterplot
import numpy as np
import matplotlib.pyplot as plt
x = data.map(lambda p:
(p.features[0])).collect()
y = data.map(lambda p:
(p.label)).collect()
from pandas import *
from ggplot import *
pydf = DataFrame({'pop':x,'price':y})
p = ggplot(pydf, aes('pop','price')) +
geom_point(color='blue')
display(p)](https://image.slidesharecdn.com/spark-mllibfrom-quickstart-to-scikit-learn-160224225718/85/Apache-Spark-MLlib-From-Quick-Start-to-Scikit-Learn-16-320.jpg)









![Our ML workflow
29
Text
This scarf I
bought is
very strange.
When I ...
Label
Rating = 3.0
Tokenizer
Words
[This,
scarf,
I,
bought,
...]
Hashing
Term-Freq
Features
[2.0,
0.0,
3.0,
...]
Linear
Regression
Prediction
Rating = 2.7](https://image.slidesharecdn.com/spark-mllibfrom-quickstart-to-scikit-learn-160224225718/85/Apache-Spark-MLlib-From-Quick-Start-to-Scikit-Learn-29-320.jpg)
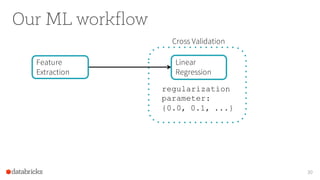
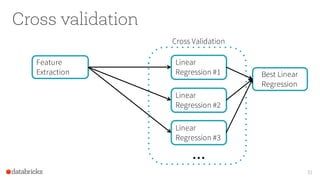
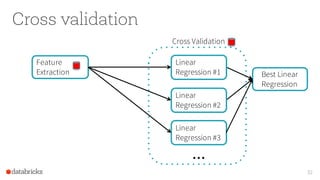
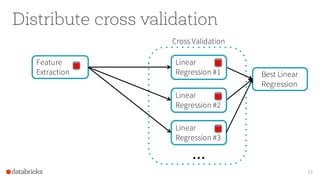







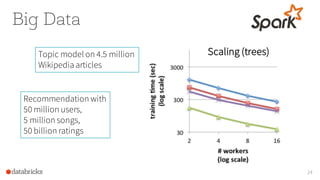
The document provides an overview of Apache Spark's MLlib, highlighting its capabilities for machine learning at scale, emphasizing its design advantages like simplicity and scalability. It features insights from Joseph K. Bradley and Denny Lee, discussing the integration of MLlib with tools like scikit-learn, and the advantages of automating decision-making for large datasets. The document also includes examples and workflows for using MLlib effectively in data analysis scenarios.






































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















