Download as PDF, PPTX


















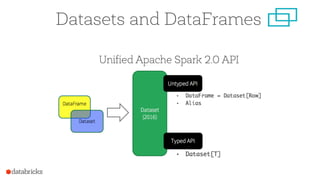













![Background: What is in an RDD?
•Dependencies
• Partitions (with optional localityinfo)
• Compute function: Partition =>Iterator[T]
Opaque Computation
& Opaque Data](https://image.slidesharecdn.com/jumpstartwithspark2-161216190918/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-59-320.jpg)

![Type-safe:operate
on domain objects
with compiled
lambda functions
8
Dataset API in Spark 2.0
val df = spark.read.j son("people.json")
/ / Convert data to domain obj ects.
case cl ass Person(name: Stri ng, age: I n t )
val ds: Dataset[Person] = df.as[Person]
val fi l terD S = d s . f i l t er ( _ . age > 30)
// will return DataFrame=Dataset[Row]
val groupDF = ds.filter(p=>
p.name.startsWith(“M”))
.groupBy(“name”)
.avg(“age”)](https://image.slidesharecdn.com/jumpstartwithspark2-161216190918/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-61-320.jpg)













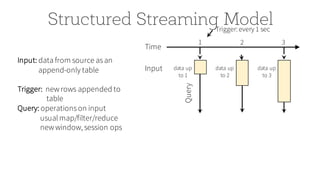
![Structured Streaming ModelTrigger: every 1 sec
1 2 3
result
for data
up to 1
Result
Query
Time
data up
to 1
Input data up
to 2
result
for data
up to 2
data up
to 3
result
for data
up to 3
Output
[complete mode] output only new rows
since last trigger
Result: final operated table
updated every triggerinterval
Output: what part of result to write
to data sink after every trigger
Complete output: Write full result table every time
Append output: Write only new rows that got
added to result table since previous batch
*Not all output modes are feasible withall queries](https://image.slidesharecdn.com/jumpstartwithspark2-161216190918/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-85-320.jpg)


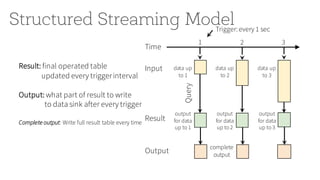
![Streaming ETL with DataFrames
1 2 3
Result
Input
Output
[append mode]
new rows
in result
of 2
new rows
in result
of 3
input = spark.readStream
.format("json")
.load("source-path")
result = input
.select("device", "signal")
.where("signal > 15")
result.writeStream
.format("parquet")
.start("dest-path")](https://image.slidesharecdn.com/jumpstartwithspark2-161216190918/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-89-320.jpg)




![Watermarking for handling late data
[Spark 2.1]
94
input.withWatermark("event-time", "15 min")
.groupBy(
$"device-type",
window($"event-time", "10 min"))
.avg("signal")
Continuously compute 10
minute average while data
can be 15 minutes late](https://image.slidesharecdn.com/jumpstartwithspark2-161216190918/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-94-320.jpg)

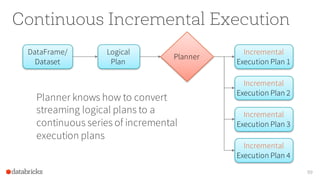
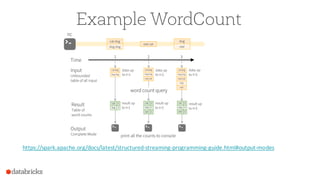
![Continuous Incremental Execution
100
Planner
Incremental
Execution 2
Offsets:[106-197] Count: 92
Plannerpollsfor
new data from
sources
Incremental
Execution 1
Offsets:[19-105] Count: 87
Incrementally executes
new data and writesto sink](https://image.slidesharecdn.com/jumpstartwithspark2-161216190918/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-100-320.jpg)
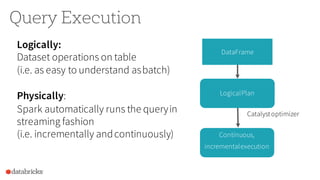
![Continuous Aggregations
Maintain runningaggregate as in-memory state
backed by WAL in file system for fault-tolerance
101
state data generated and used
across incremental executions
Incremental
Execution 1
state:
87
Offsets:[19-105] Running Count: 87
memory
Incremental
Execution 2
state:
179
Offsets:[106-179] Count: 87+92 = 179](https://image.slidesharecdn.com/jumpstartwithspark2-161216190918/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-101-320.jpg)












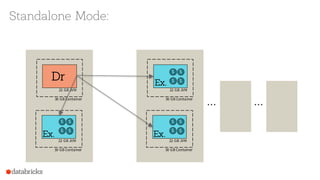
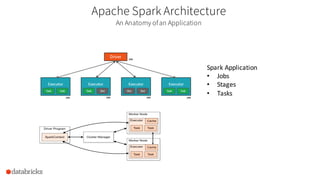
This document provides an agenda for a 3+ hour workshop on Apache Spark 2.x on Databricks. It includes introductions to Databricks, Spark fundamentals and architecture, new features in Spark 2.0 like unified APIs, and workshops on DataFrames/Datasets, Spark SQL, and structured streaming concepts. The agenda covers lunch and breaks and is divided into hour and half hour segments.

































































































