Download as PDF, PPTX



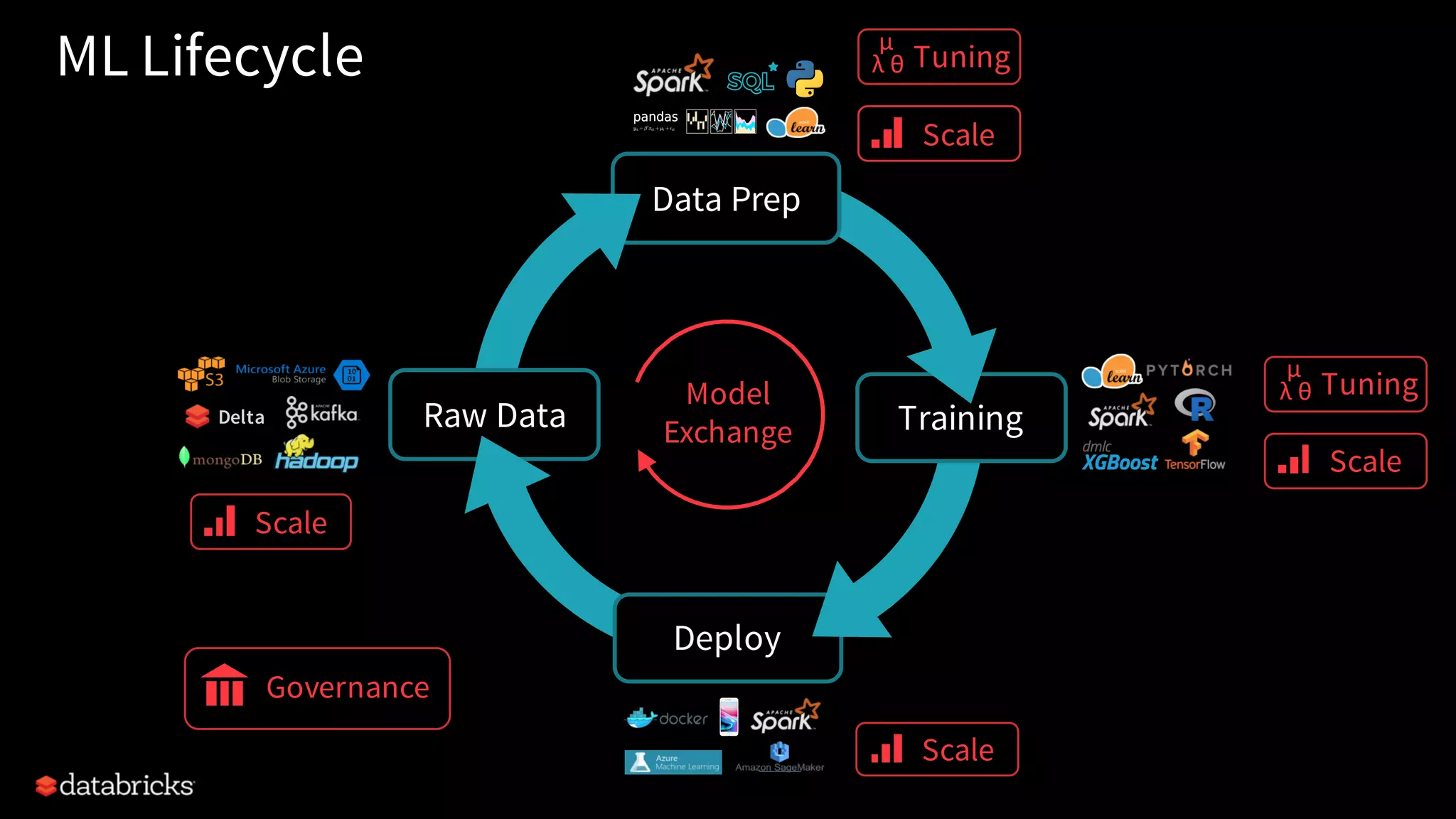





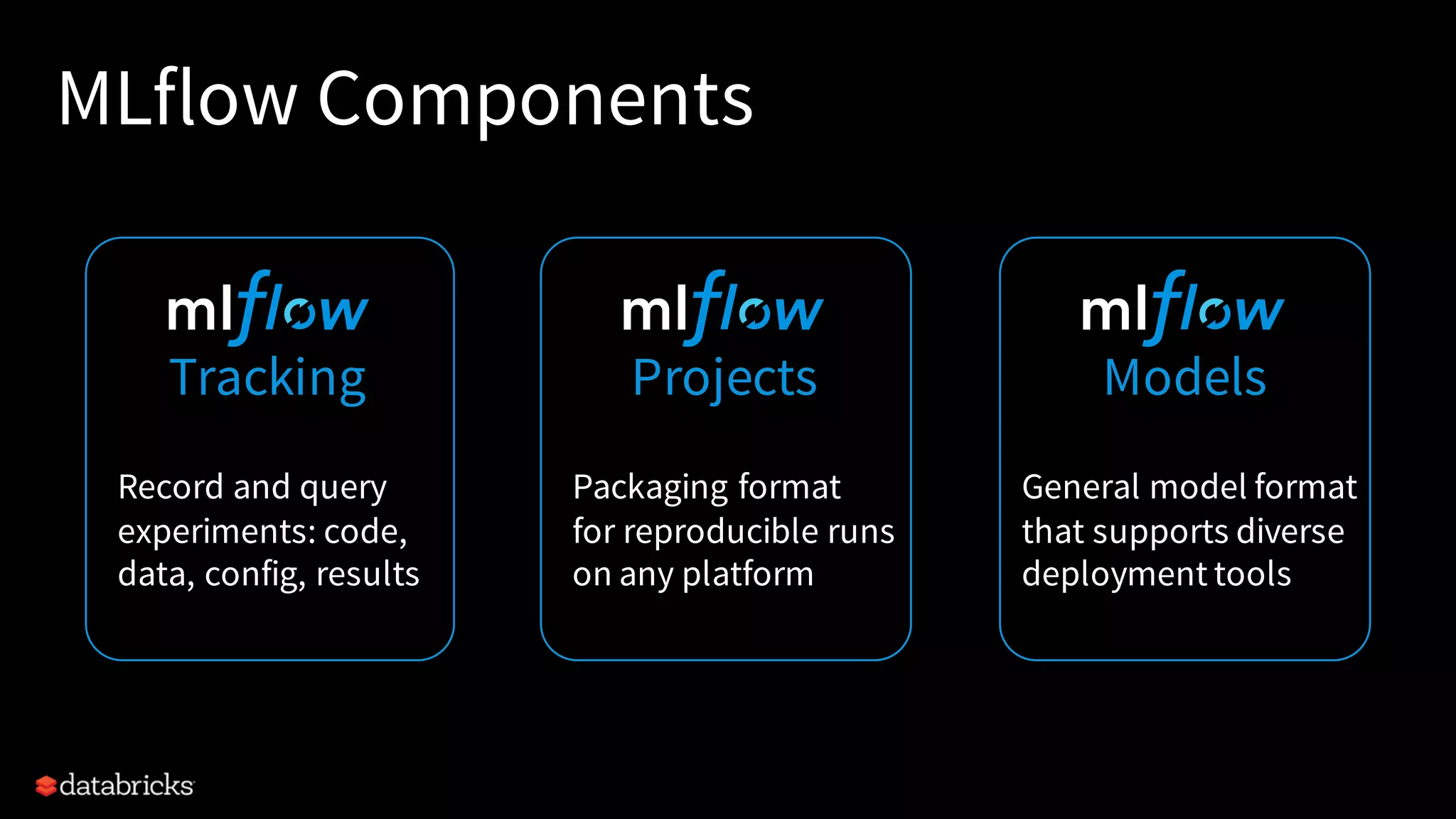
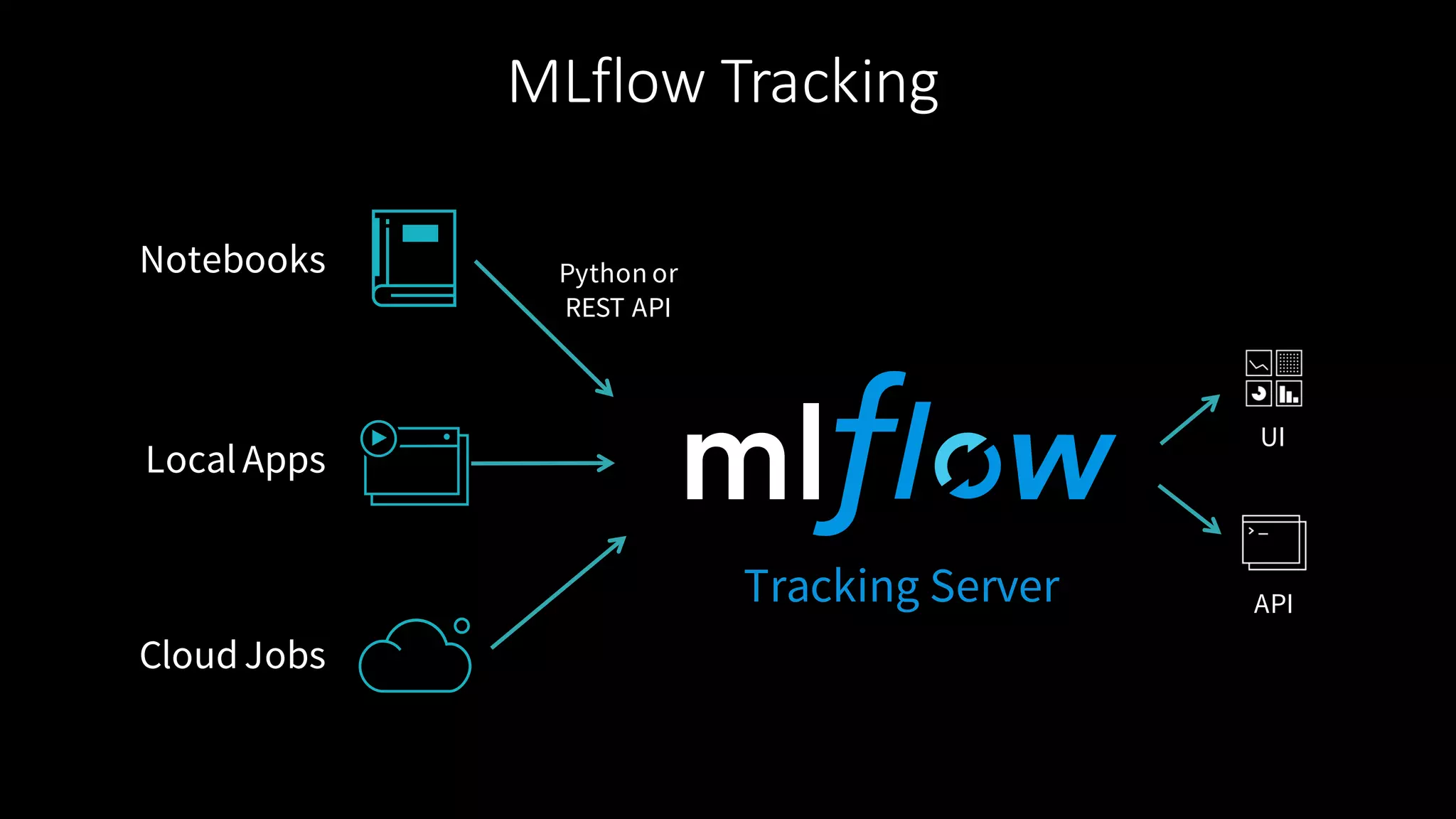
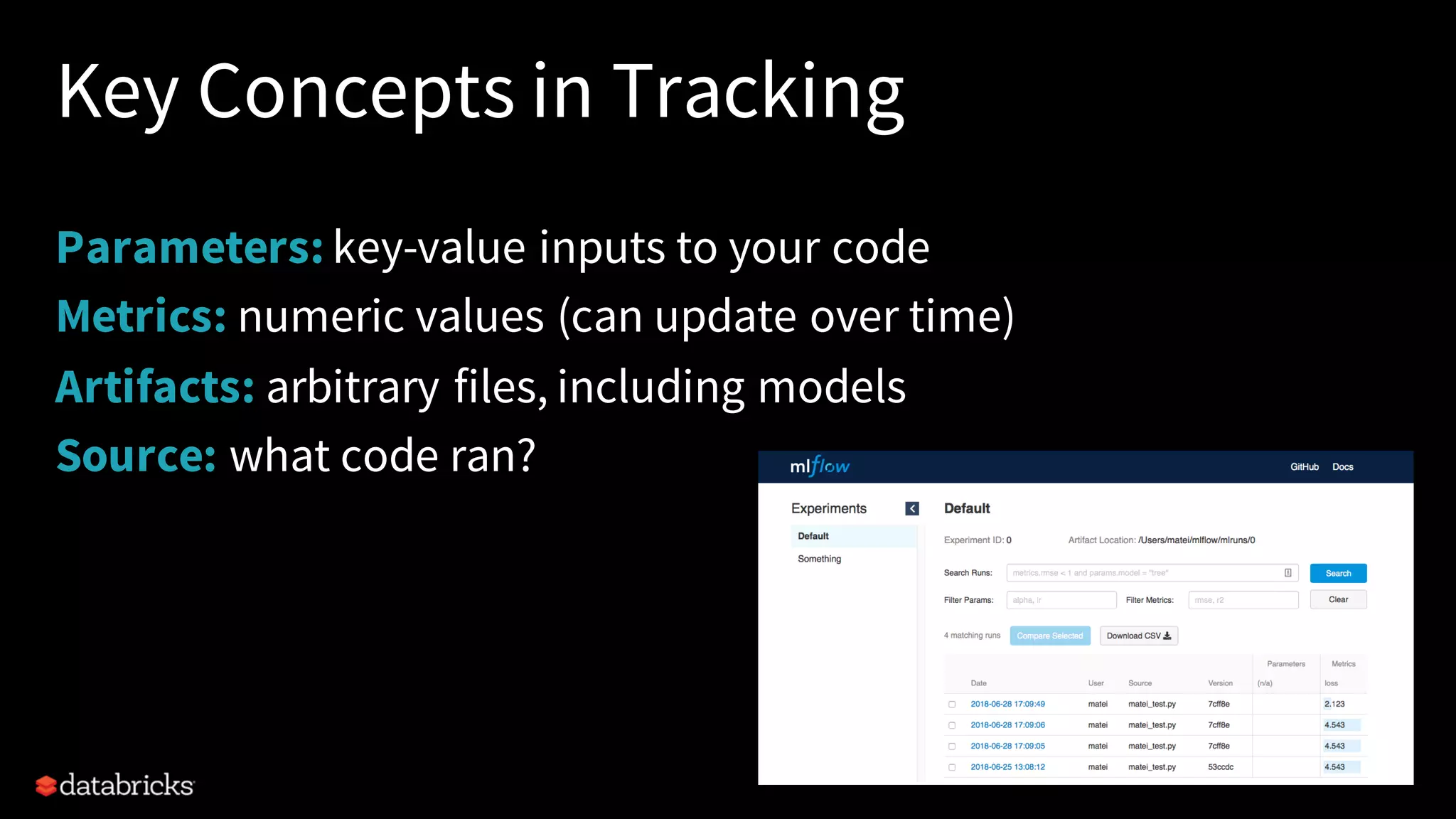
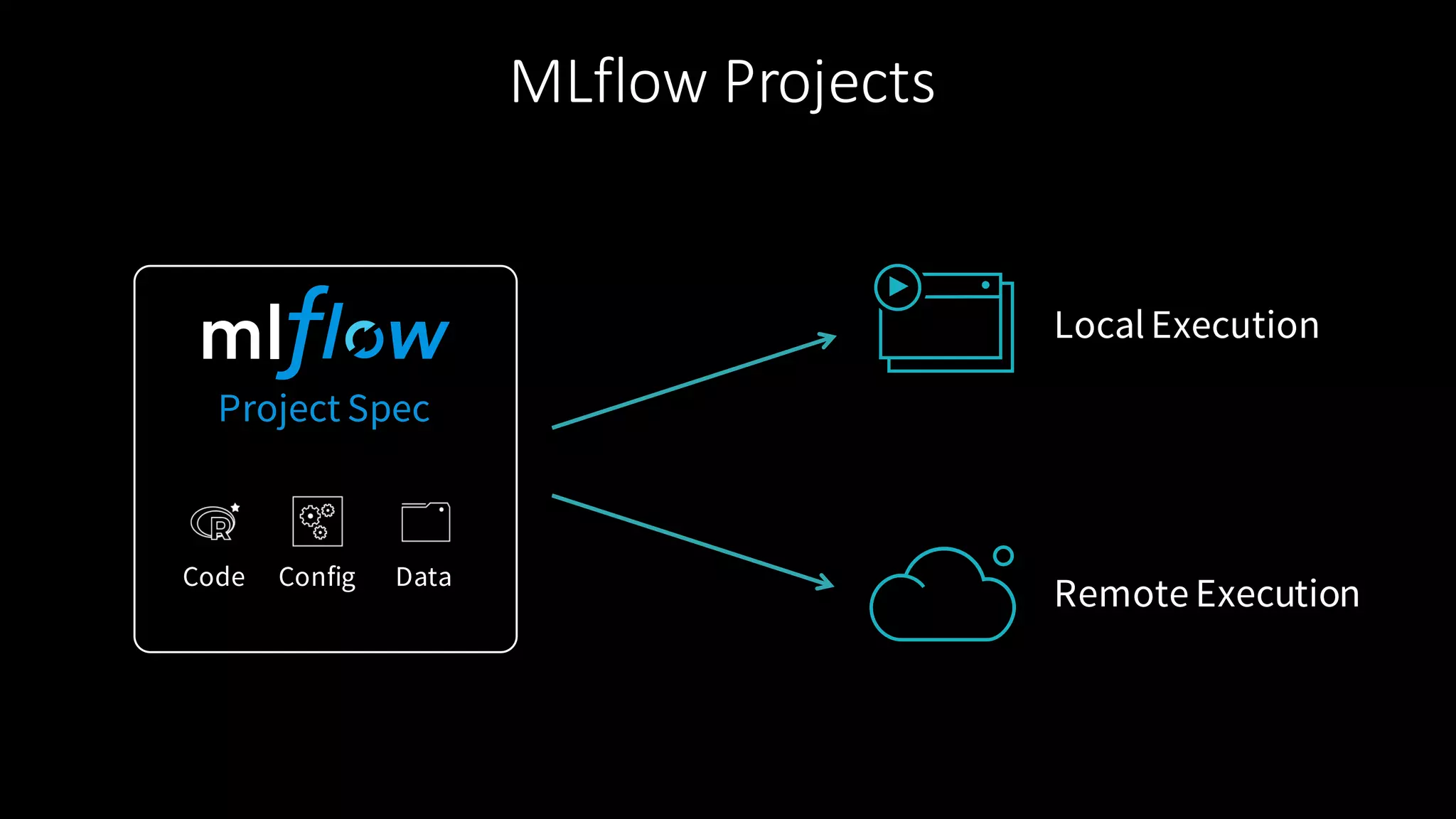

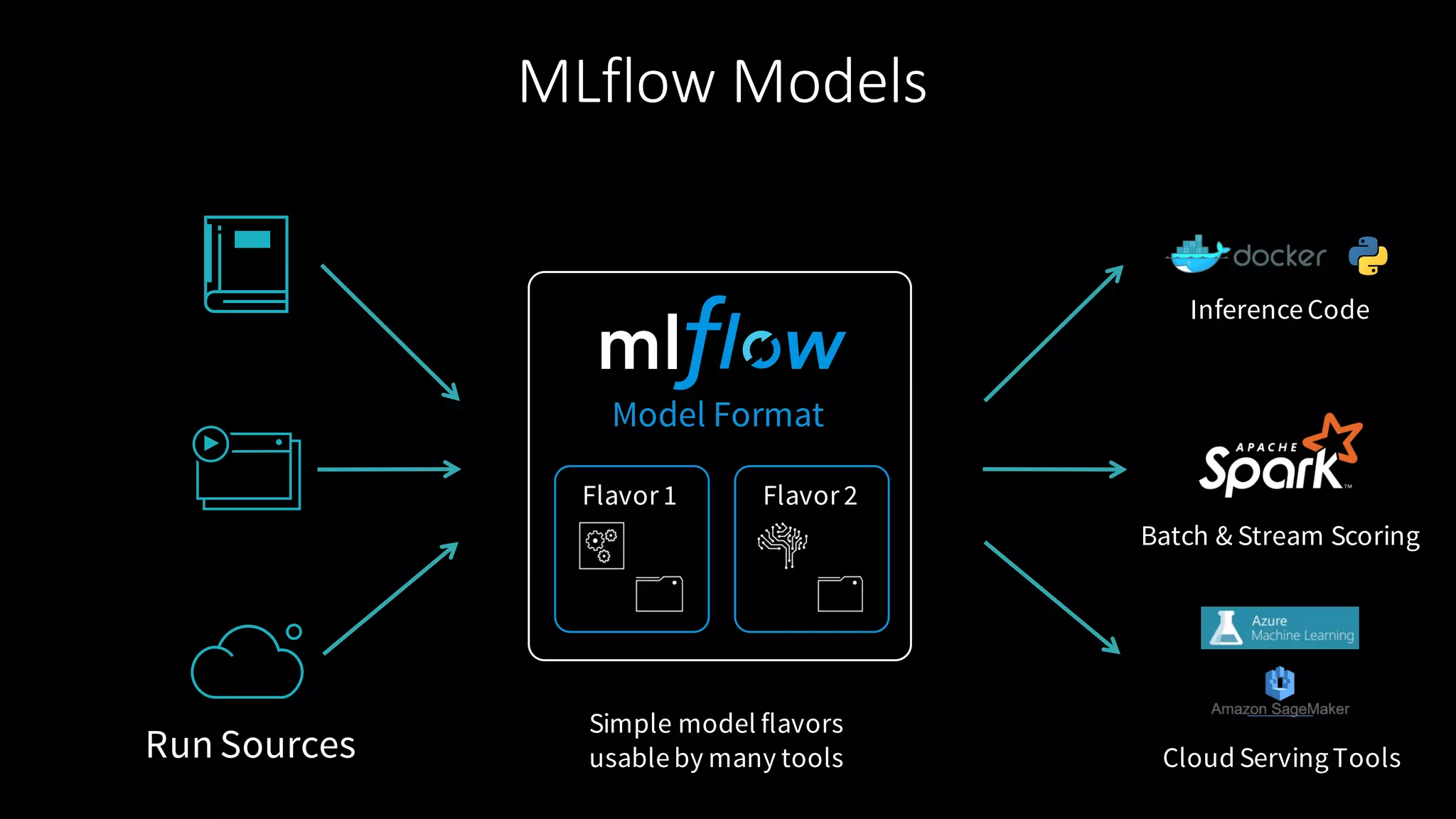











The document describes MLflow, an open-source platform designed to manage the machine learning lifecycle, addressing challenges such as tracking experiments, packaging code, and deploying models across various environments. It emphasizes a modular design, allowing integration with various tools and flexibility for users while providing APIs for seamless interaction. The roadmap includes ongoing improvements and future plans for enhanced functionality, including data component support and integrations with different programming languages.























































































