







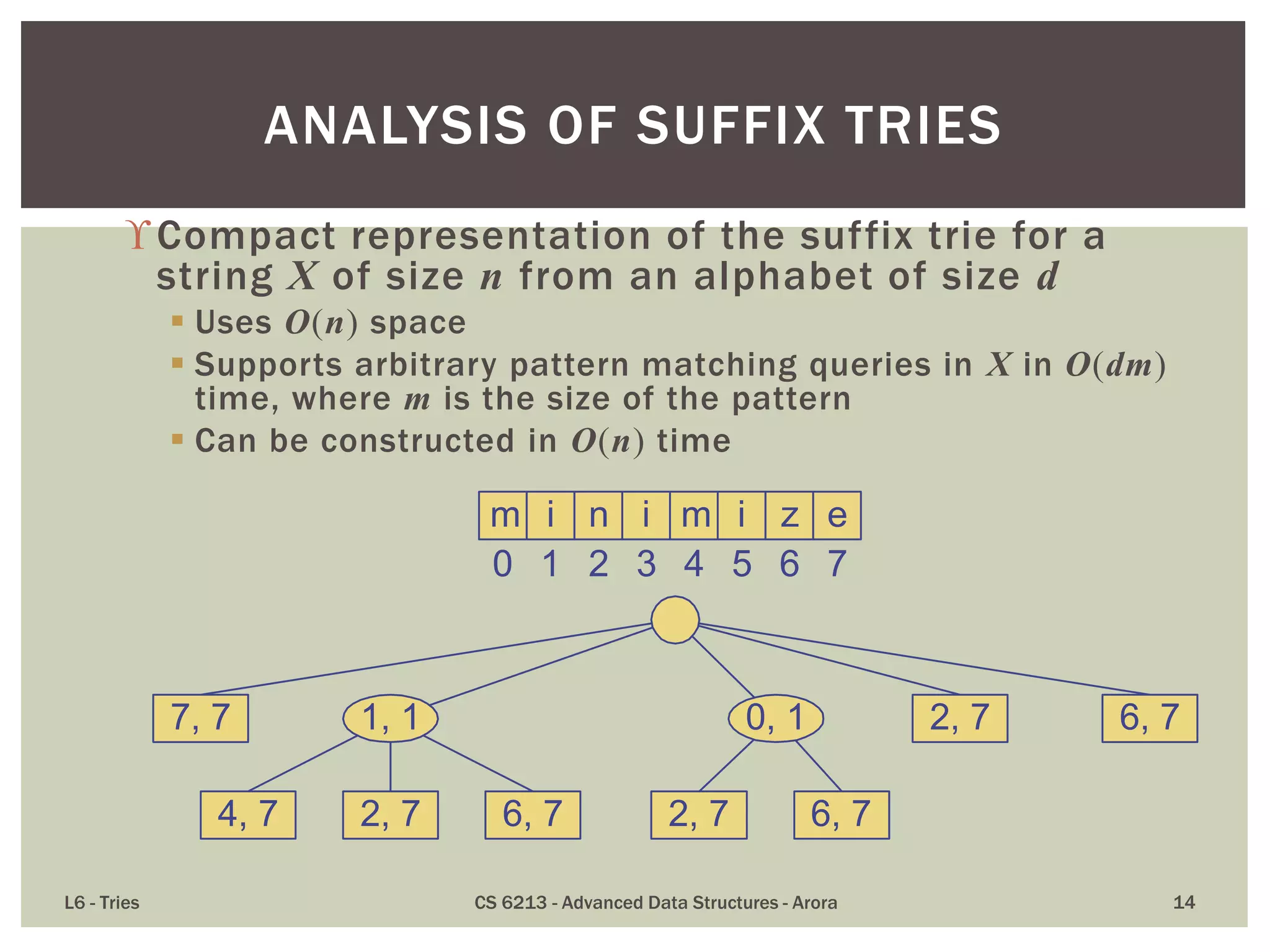
![ Compact representation of a compressed trie for an array of
strings:
Stores at the nodes ranges of indices instead of substrings
Uses O(s) space, where s is the number of strings in the array
Serves as an auxiliary index structure
L6 - Tries CS 6213 - Advanced Data Structures - Arora 11
COMPACT REPRESENTATION
s e e
b e a r
s e l l
s t o c k
b u l l
b u y
b i d
h e
b e l l
s t o p
0 1 2 3 4
a rS[0] =
S[1] =
S[2] =
S[3] =
S[4] =
S[5] =
S[6] =
S[7] =
S[8] =
S[9] =
0 1 2 3 0 1 2 3
1, 1, 1
1, 0, 0 0, 0, 0
4, 1, 1
0, 2, 2
3, 1, 2
1, 2, 3 8, 2, 3
6, 1, 2
4, 2, 3 5, 2, 2 2, 2, 3 3, 3, 4 9, 3, 3
7, 0, 3
0, 1, 1](https://image.slidesharecdn.com/l6tries-140228161049-phpapp01/75/Tries-Tree-Based-Structures-for-Strings-11-2048.jpg)



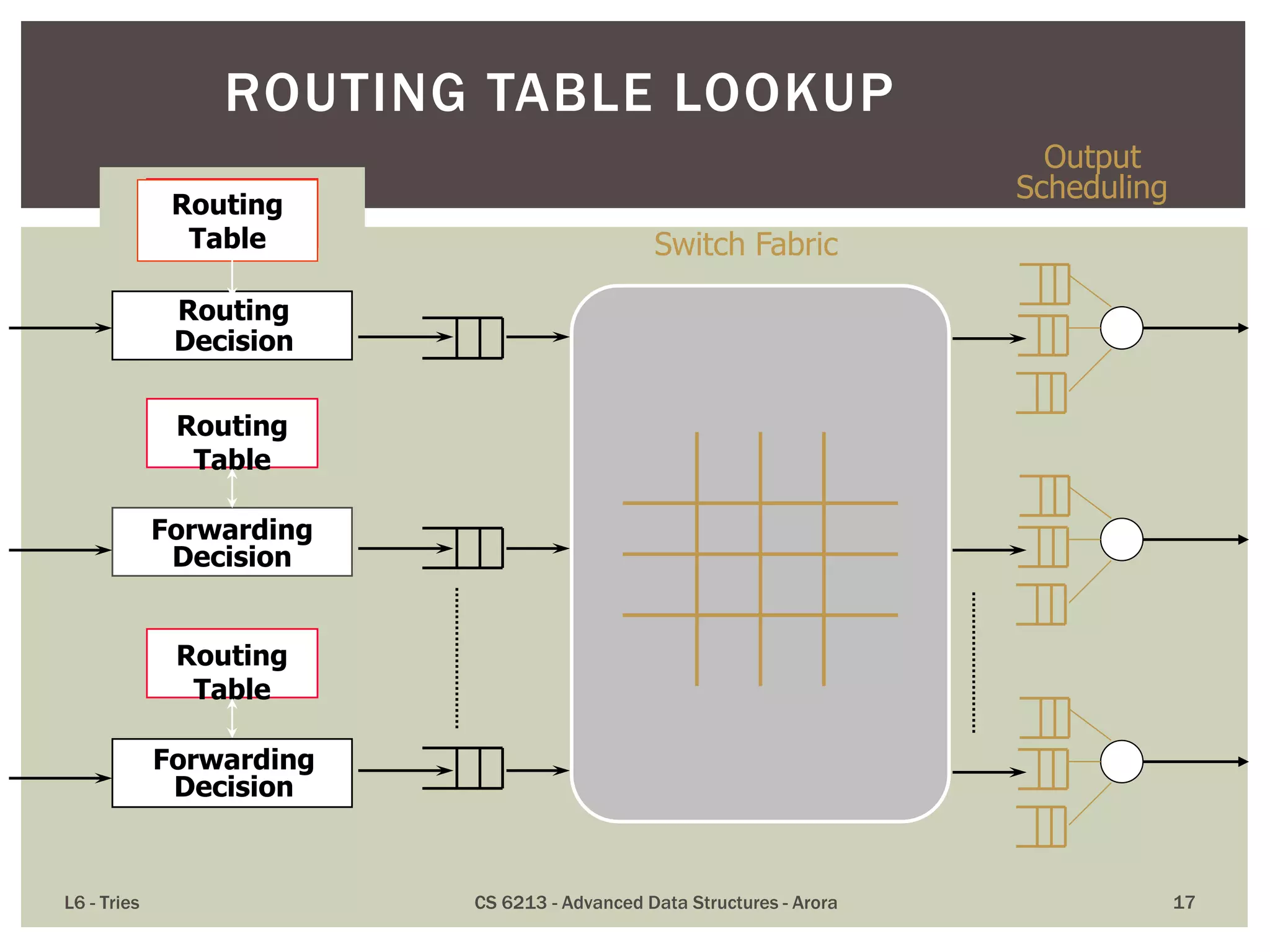
![A standardized exterior gateway protocol designed to
exchange routing and reachability information
between autonomous systems (AS) on the Internet.
Makes routing decisions based on paths, network
policies and/or rule-sets configured by a network
administrator.
Plays a key role in the overall operation of the
Internet and is involved in making core routing
decisions.
[Itself uses TCP to exchange its own data.]
L6 - Tries CS 6213 - Advanced Data Structures - Arora 18
BORDER GATEWAY PROTOCOL (BGP)](https://image.slidesharecdn.com/l6tries-140228161049-phpapp01/75/Tries-Tree-Based-Structures-for-Strings-18-2048.jpg)
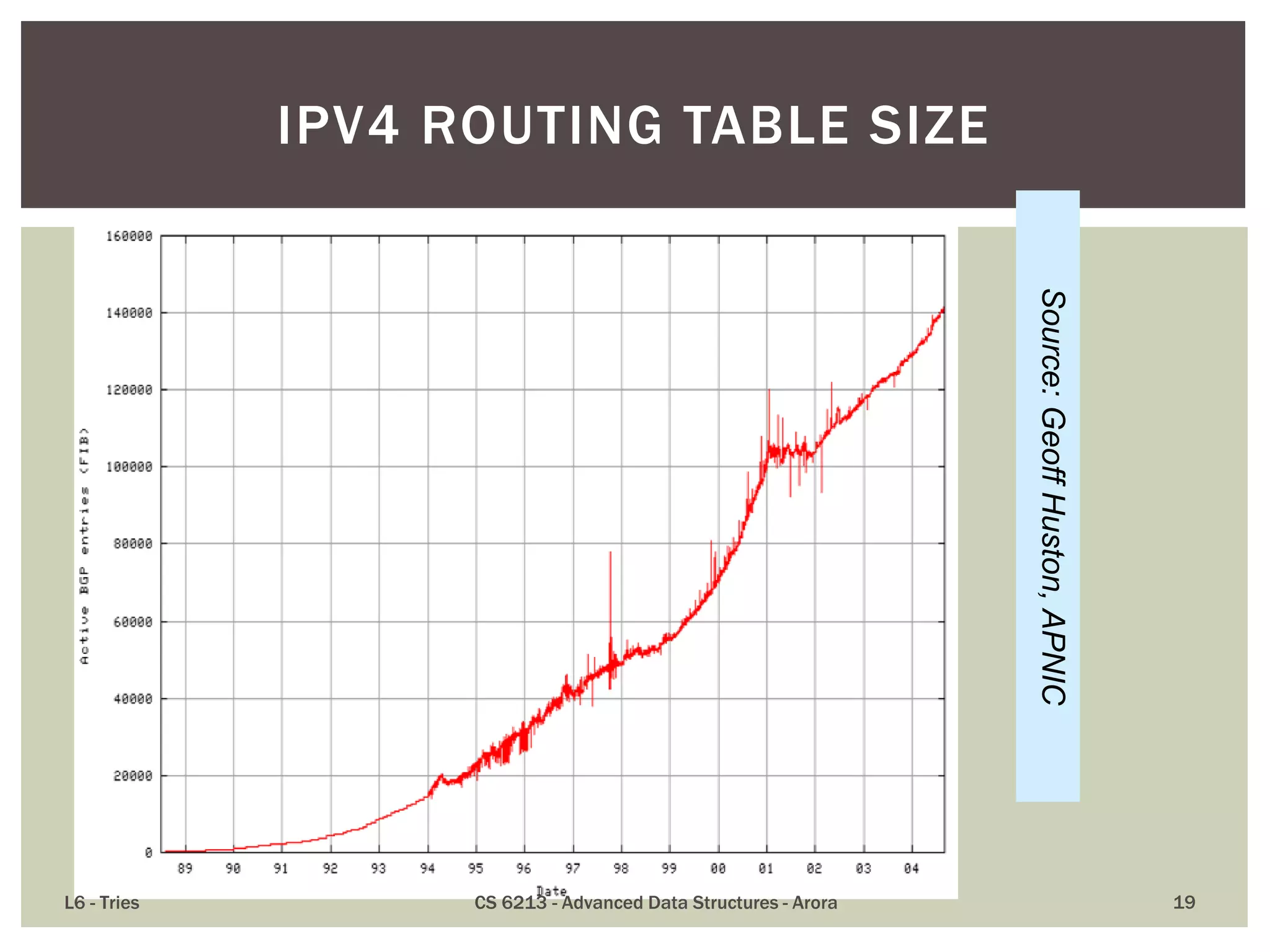


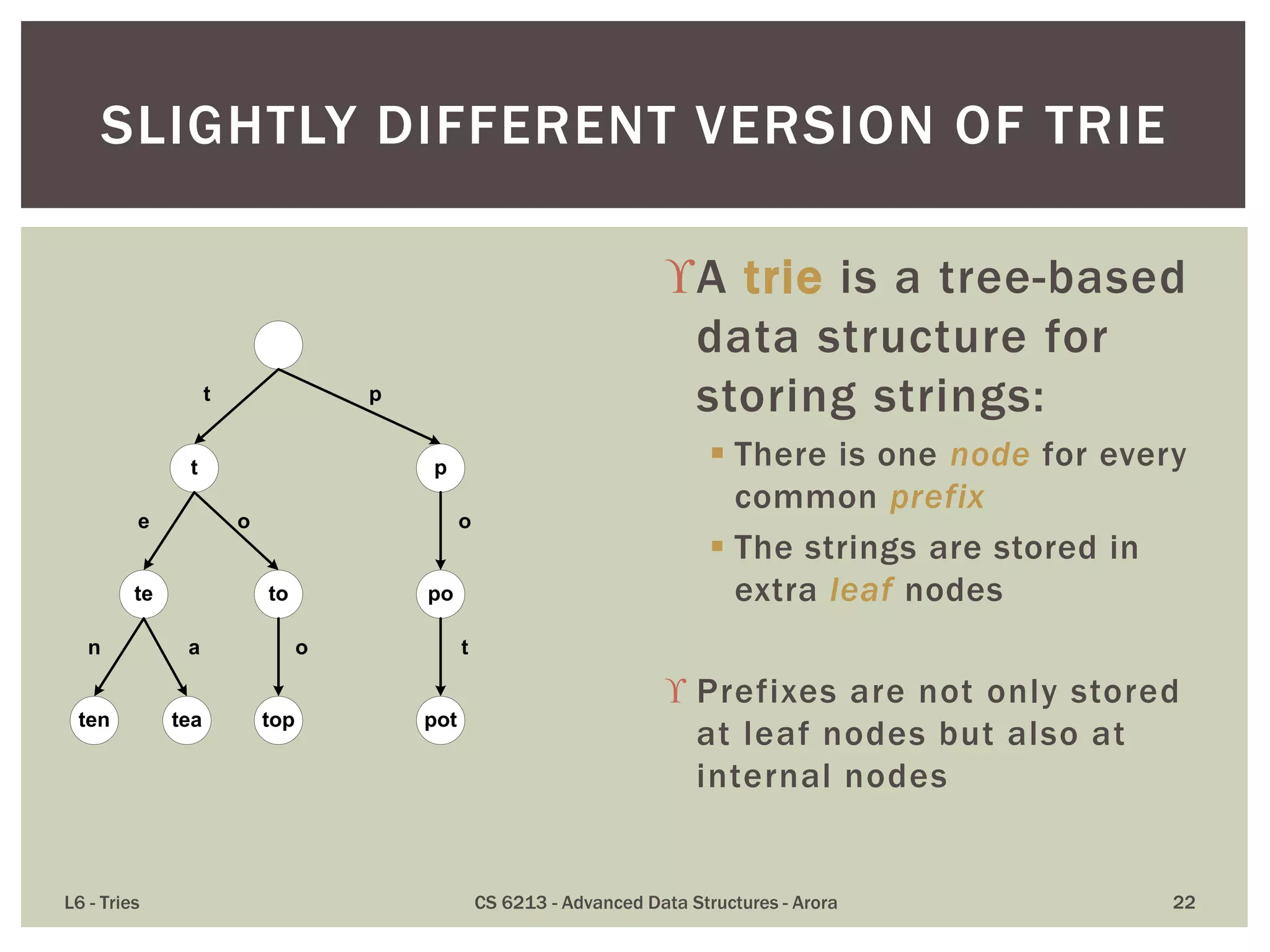
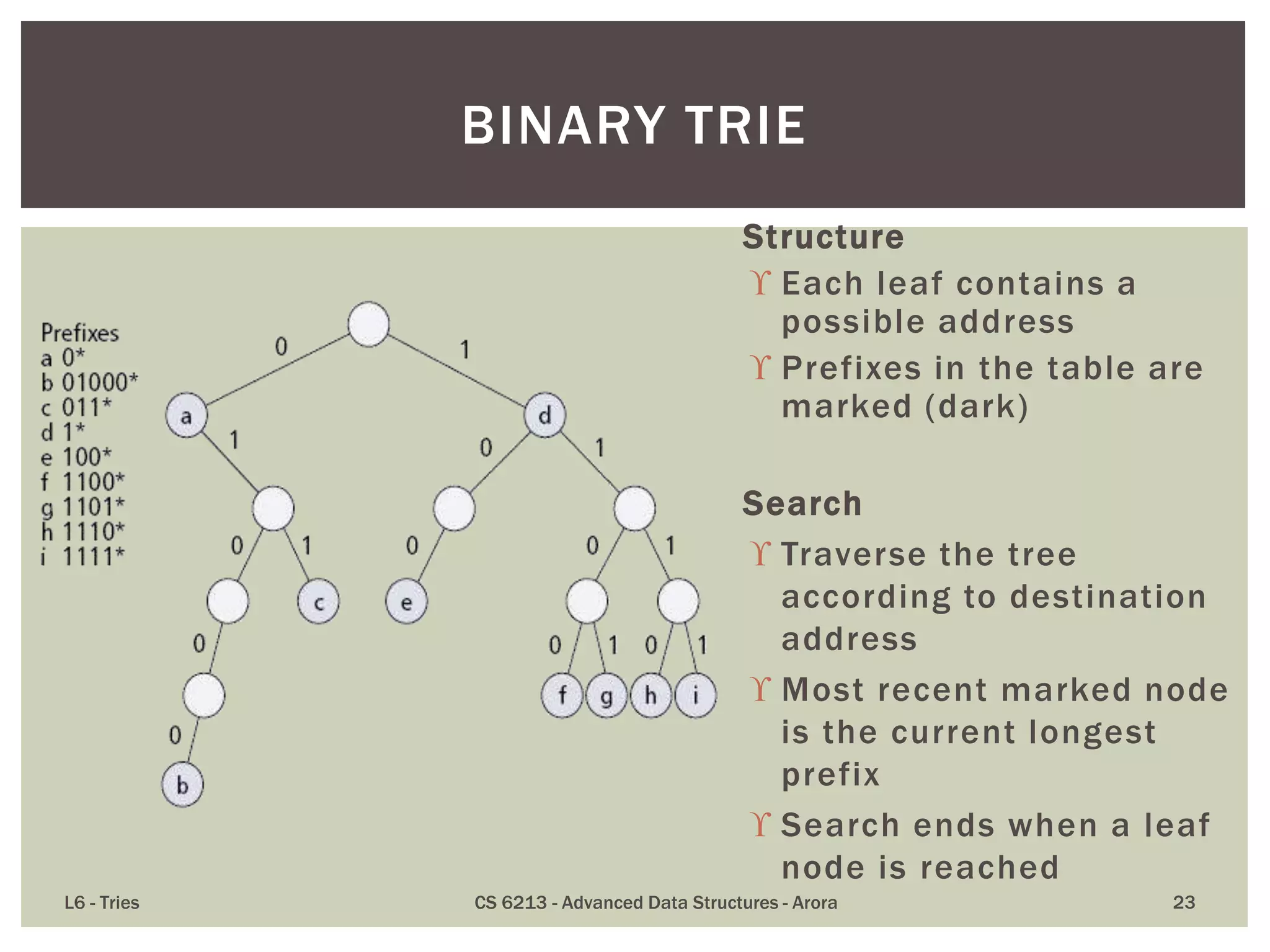
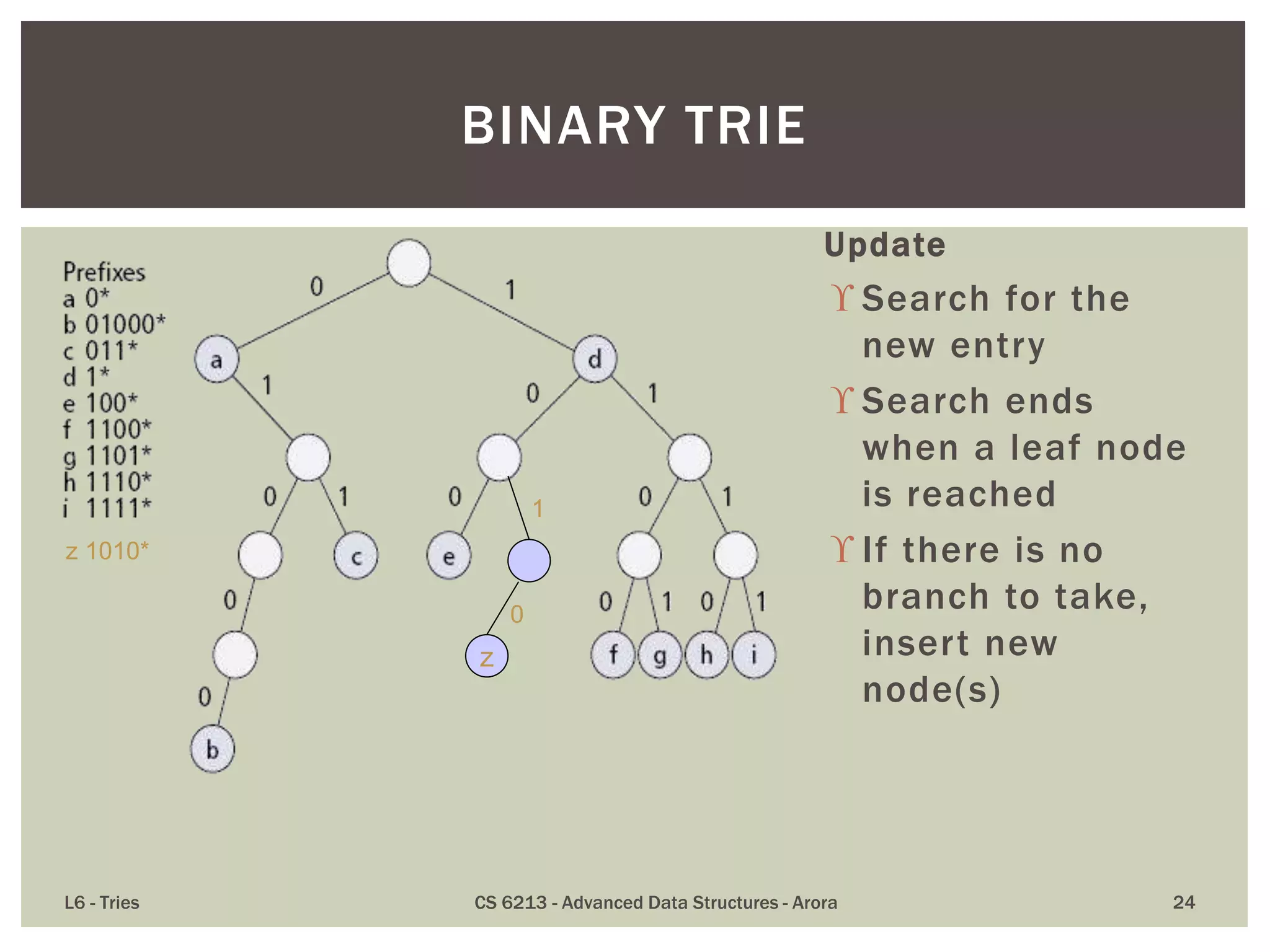

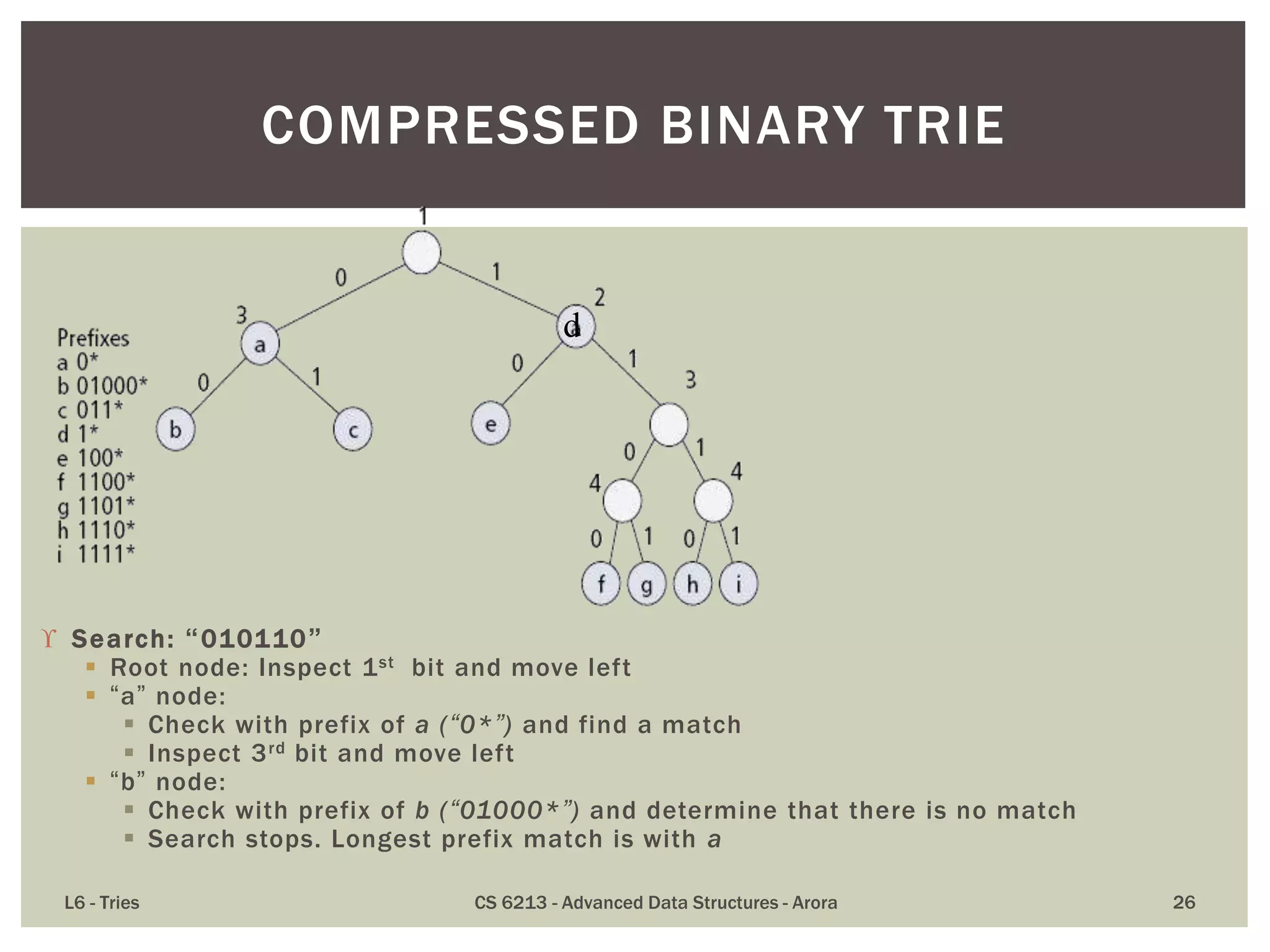

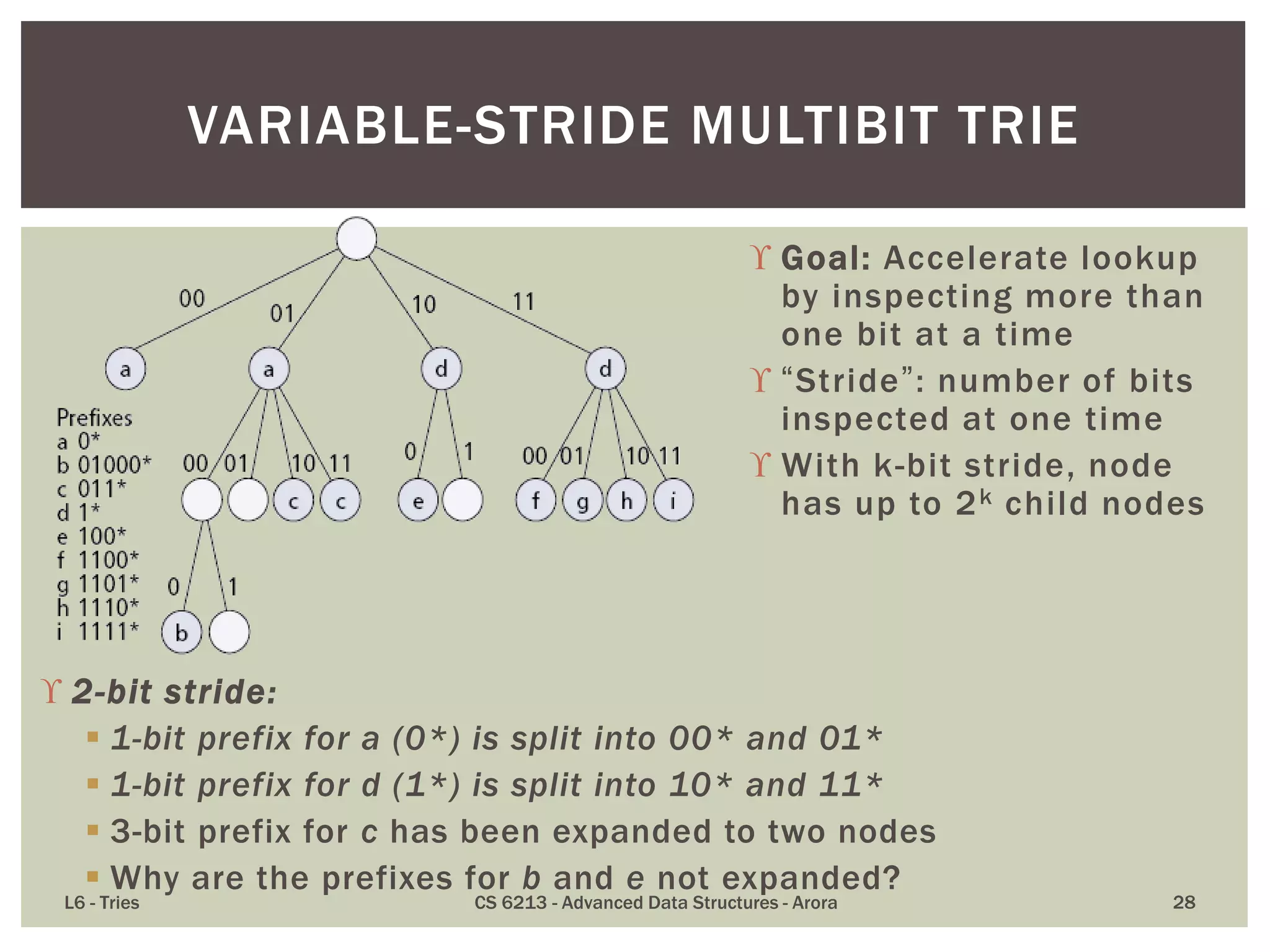
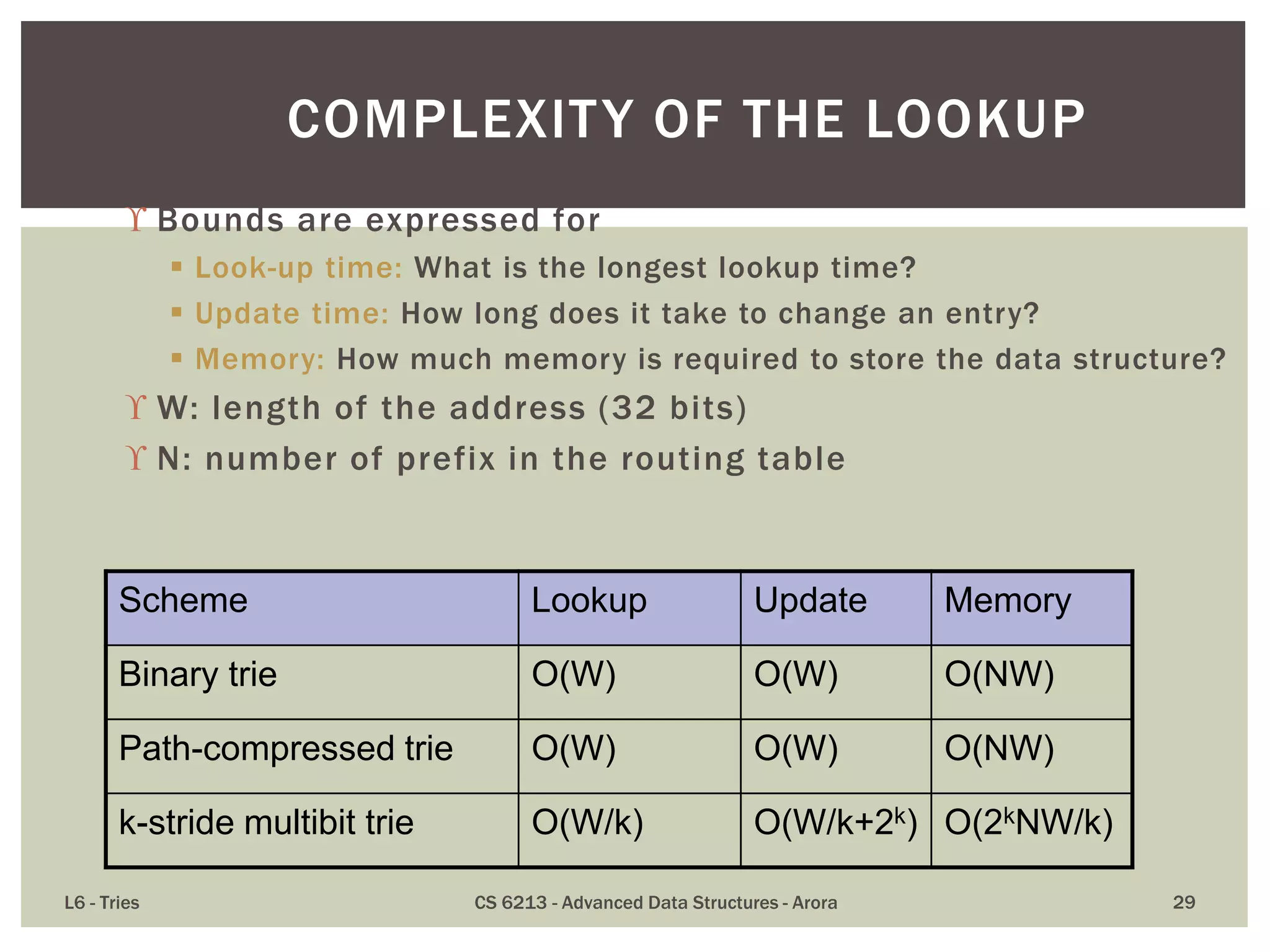


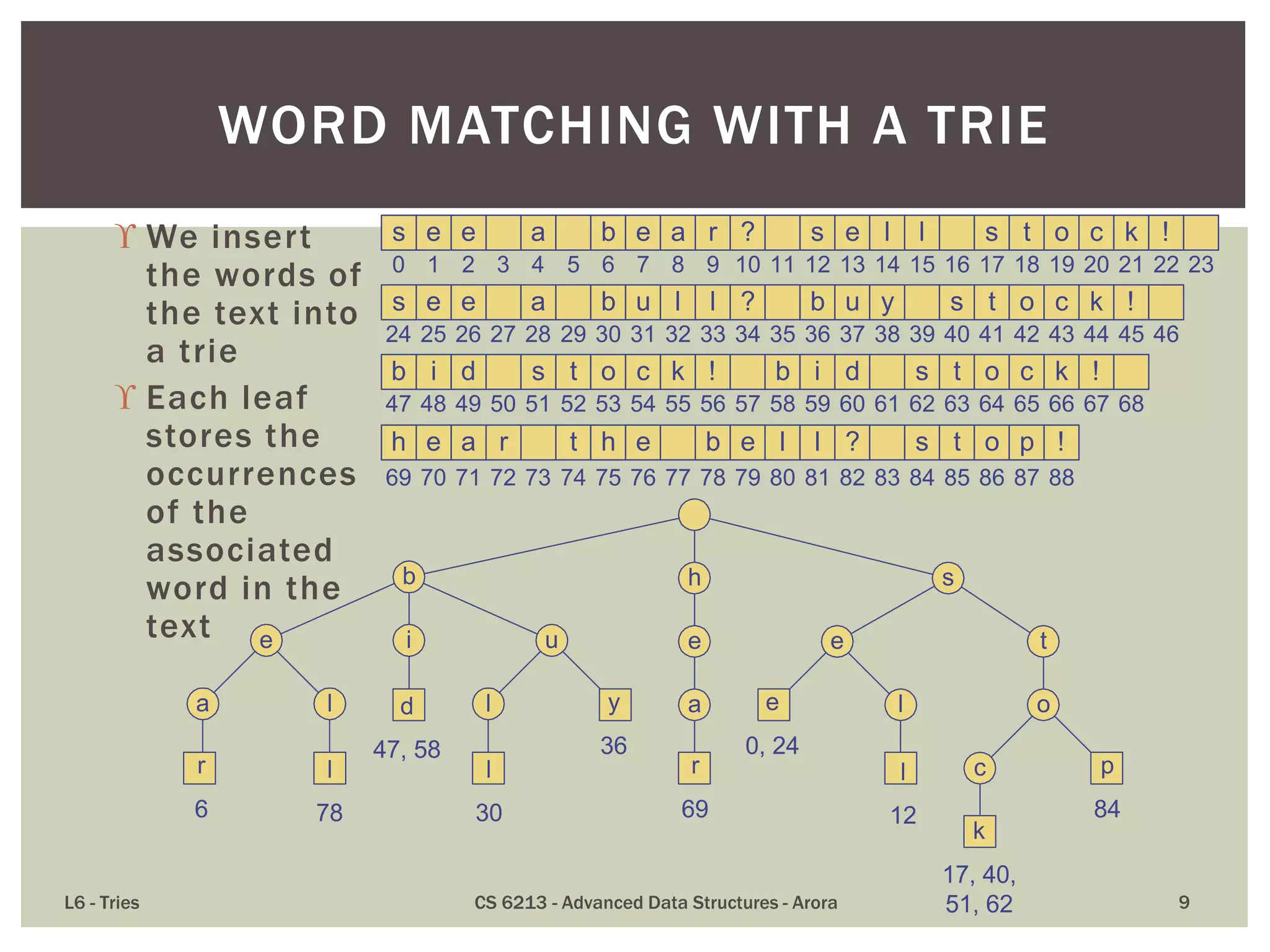
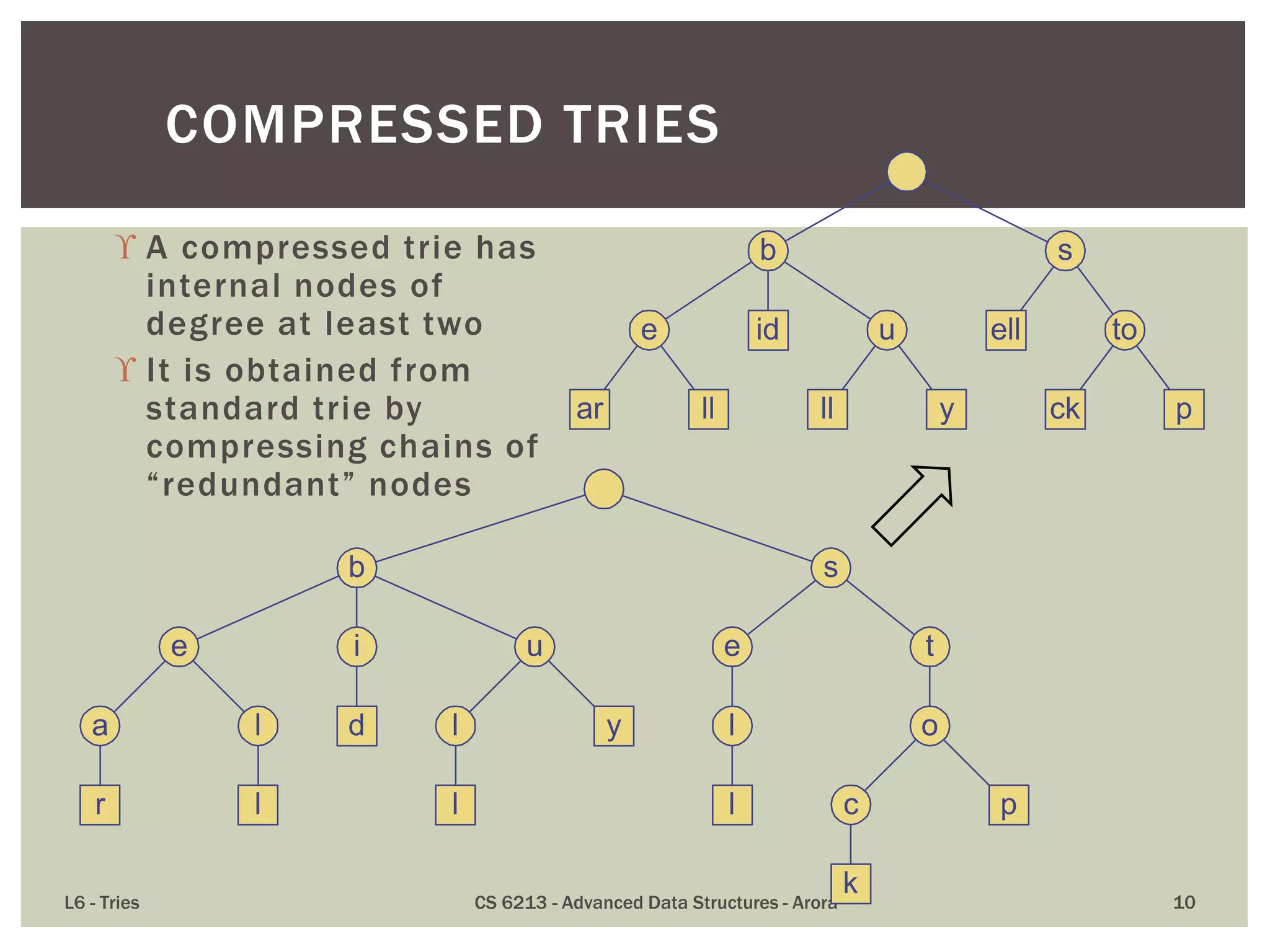
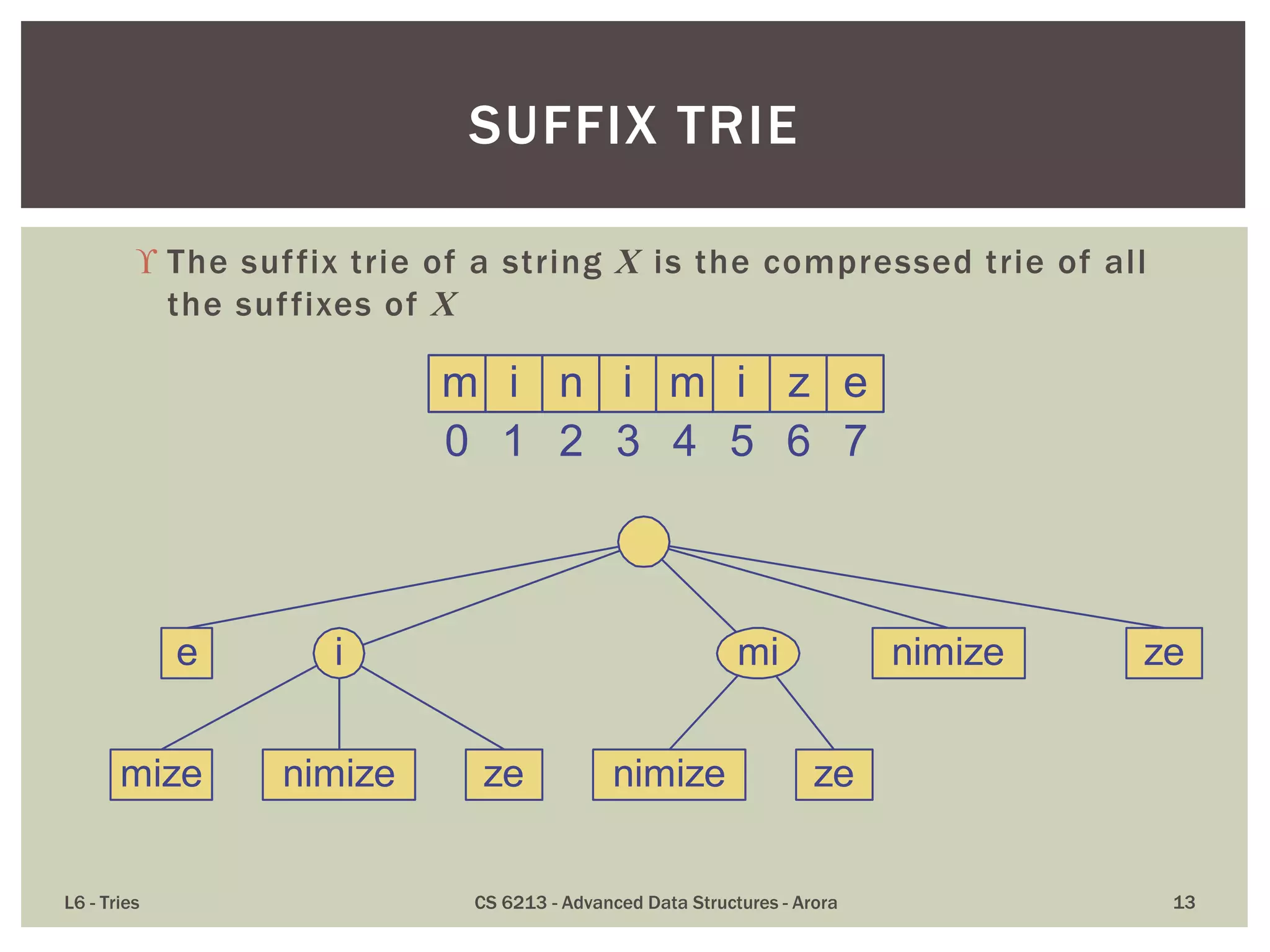
The document discusses the trie data structure, emphasizing its efficiency in string storage and pattern matching, which operates in O(m) time, where m is the pattern size. It outlines various trie types, including standard, compressed, and suffix tries, and their applications in fields such as text searching, networking, and bioinformatics. Additionally, it covers the complexity of lookup and update times, highlighting the trie’s ability to manage strings effectively for various use cases.






































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



