
Downloaded 50 times






![ Character classes:
You can specify character classes
enclosing a list of characters in brackets [],
which you will find any of the characters from
the list.
If the first symbol after the "[" is "^", the class
finds any character that is not in the list.
Metacharacters:
Metacharacters are special characters which
are the core of regular expressions .
As they are extremely important to understand
the syntax of regular expressions and there are
different types.](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-8-320.jpg)
![Metacharacters - delimiters
This class of metacharacters allows us to delimit where we want to
search the search patterns.
Metacharacter Description
^
“Caret”,Line start, it negates the choice. [^0-9] denotes
the choice "any character but a digit".
$ End of line
TO Start text.
Z Matches end of string. If a newline exists, it matches
just before newline.
z Matches end of string.
. Any character on the line.
b
Matches the empty string, but only at the start or end
of a word.
B
Matches the empty string, but not at the start or end
of a word.](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-9-320.jpg)
![Metacharacters - Predefined classes
These are predefined classes that provide us with the use
of regular expressions.
Metacharacter Description
w
Matches any alphanumeric character; equivalent to [a-zA-Z0-9_]. With
LOCALE, it will match the set [a-zA-Z0-9_] plus characters defined as
letters for the current locale.
W A non-alphanumeric character.
d Matches any decimal digit; equivalent to the set [0-9].
D
The complement of d. It matches any non-digit character;
equivalent to the set [^0-9].
s Matches any whitespace character; equivalent to [ tnrfv].
S
The complement of s. It matches any non-whitespace
character; equiv. to [^ tnrfv]](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-10-320.jpg)


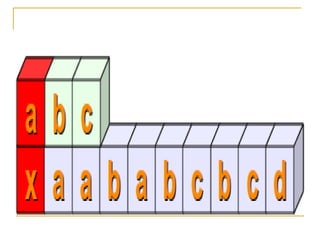
![ Square brackets, "[" and "]", are used to
include a character class.
[xyz] means e.g. either an "x", an "y"
or a "z".
Let's look at a more practical example:
r"M[ae][iy]er"](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-13-320.jpg)
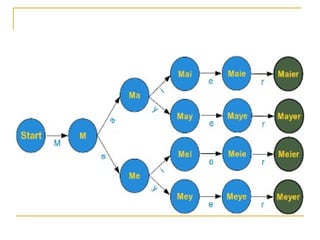




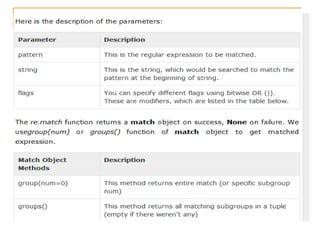
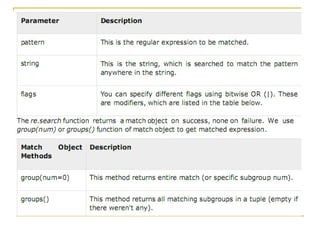
![Match Function
The match function checks whether a regular
expression matches is the beginning of a string. It is
based on the following format:
Match (regular expression, string, [flag])
Flag values:
Flag re.IGNORECASE: There will be no difference between
uppercase and lowercase letters
Flag re.VERBOSE: Comments and spaces are ignored (in the
expression).
Note that this method stops after the first match, so
this is best suited for testing a regular expression
more than extracting data.](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-19-320.jpg)


![24
Modifier Description
re.I
re.IGONRECASE
Performs case-insensitive matching
re.L
re.LOCALE
Interprets words according to the current locale. This
interpretation affects the alphabetic group (w and W), as
well as word boundary behavior (b and B).
re.M
re.MULTILINE
Makes $ match the end of a line (not just the end of the
string) and makes ^ match the start of any line (not just
the start of the string).
re.S
re.DOTALL
Makes a period (dot) match any character, including a
newline.
re.u
re.UNICODE
Interprets letters according to the Unicode character set.
This flag affects the behavior of w, W, b, B.
re.x
re.VERBOSE
It ignores whitespace (except inside a set [] or when
escaped by a backslash) and treats unescaped # as a
comment marker.
OPTION FLAGS](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-24-320.jpg)


![""" This program illustrates is
one of the regular expression method i.e., search()"""
import re
# importing Regular Expression built-in module
text = 'This is my First Regulr Expression Program'
patterns = [ 'first', 'that‘, 'program' ]
# In the text input which patterns you have to search
for pattern in patterns:
print 'Looking for "%s" in "%s" ->' % (pattern, text),
if re.search(pattern, text,re.I):
print 'found a match!'
# if given pattern found in the text then execute the 'if' condition
else:
print 'no match'
# if pattern not found in the text then execute the 'else' condition
04/22/17VYBHAVA TECHNOLOGIES 27](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-27-320.jpg)

![Regular expressions are compiled into pattern objects,
which have methods for various operations such as
searching for pattern matches or performing
string substitutions
Split Method:
Syntax:
re.split(string,[maxsplit=0])
Eg:
>>>p = re.compile(r'W+')
>>> p.split(‘This is my first split example string')
[‘This', 'is', 'my', 'first', 'split', 'example']
>>> p.split(‘This is my first split example string', 3)
[‘This', 'is', 'my', 'first split example']
29](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-29-320.jpg)



![import re
line='Python Orientation course helps professionals fish best opportunities‘
Print “Find all words starts with p”
print re.findall(r"bp[w]*",line)
print "Find all five characthers long words"
print re.findall(r"bw{5}b", line)
# Find all four, six characthers long words
print “find all 4, 6 char long words"
print re.findall(r"bw{4,6}b", line)
# Find all words which are at least 13 characters long
print “Find all words with 13 char"
print re.findall(r"bw{13,}b", line)
04/22/17VYBHAVA TECHNOLOGIES 33](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-33-320.jpg)

![import re
string="Python java c++ perl shell ruby tcl c c#"
print re.findall(r"bc[W+]*",string,re.M|re.I)
print re.findall(r"bp[w]*",string,re.M|re.I)
print re.findall(r"bs[w]*",string,re.M|re.I)
print re.sub(r'W+',"",string)
it = re.finditer(r"bc[(Ws)]*", string)
for match in it:
print "'{g}' was found between the indices
{s}".format(g=match.group(),s=match.span())
35](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-35-320.jpg)
![re.compile()
If you want to use the same regexp more than once
in a script, it might be a good idea to use a regular
expression object, i.e. the regex is compiled.
The general syntax:
re.compile(pattern[, flags])
compile returns a regex object, which can be used later
for searching and replacing.
The expressions behaviour can be modified by
specifying a flag value.
compile() compiles the regular expression into a regular
expression object that can be used later with
.search(), .findall() or .match().](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-37-320.jpg)






![ (?P<name>...)
Similar to regular parentheses, but the substring matched by
the group is accessible via the symbolic group name name.
Group names must be valid Python identifiers, and each
group name must be defined only once within a regular
expression.
A symbolic group is also a numbered group, just as if the
group were not named. So the group named 'id' in the
example above can also be referenced as the numbered
group 1.
For example, if the pattern is (?P<id>[a-zA-Z_]w*), the
group can be referenced by its name in arguments to
methods of match objects, such as m.group('id') or
m.end('id'), and also by name in pattern text (for example, (?
P=id)) and replacement text (such as g<id>).](https://image.slidesharecdn.com/advpythonregularexpressionbyrj-170422084504/85/Adv-python-regular-expression-by-Rj-44-320.jpg)





The document discusses regular expressions and text processing in Python. It covers various components of regular expressions like literals, escape sequences, character classes, and metacharacters. It also discusses different regular expression methods in Python like match, search, split, sub, findall, finditer, compile and groupdict. The document provides examples of using these regular expression methods to search, find, replace and extract patterns from text.























































































