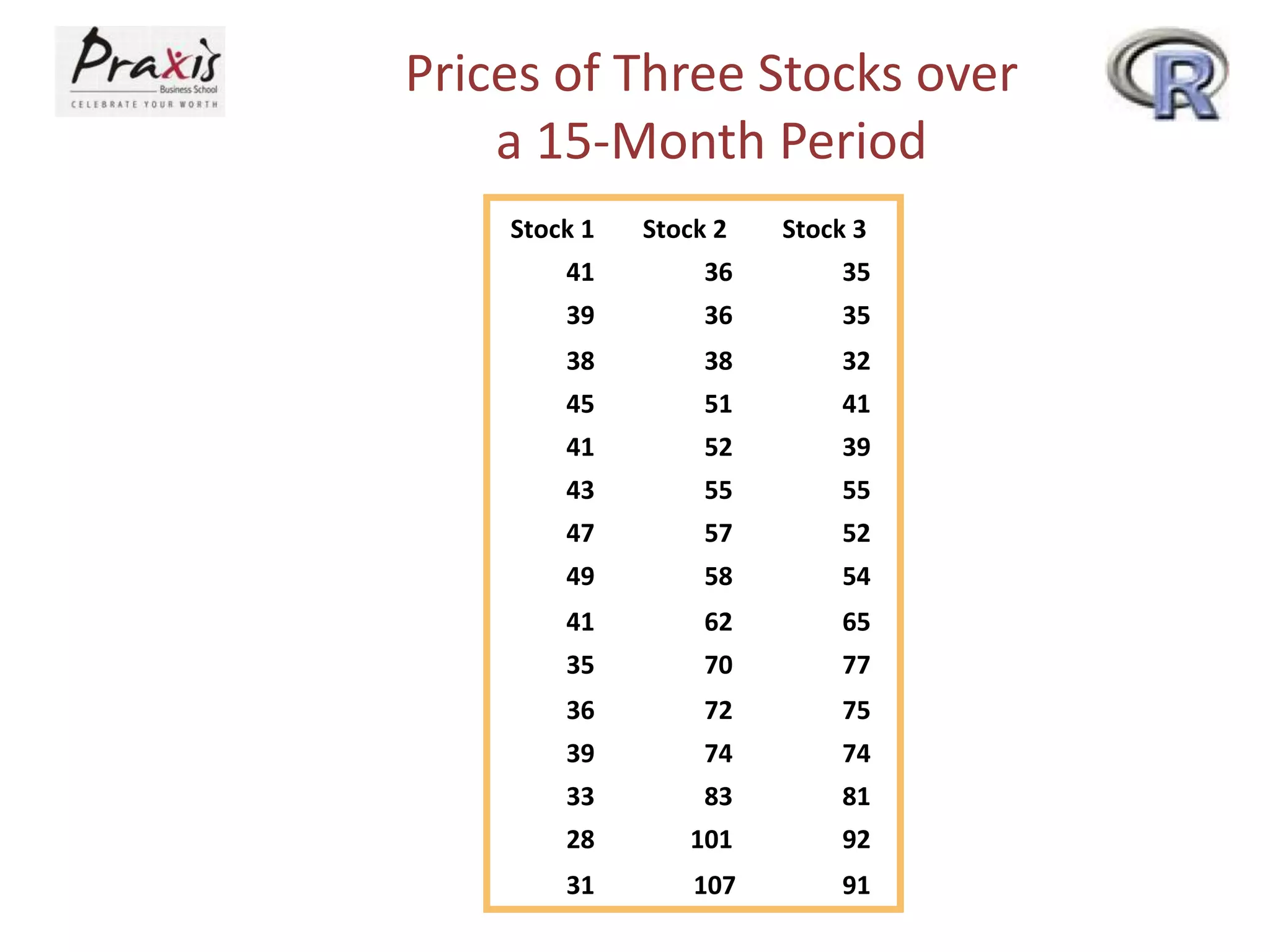
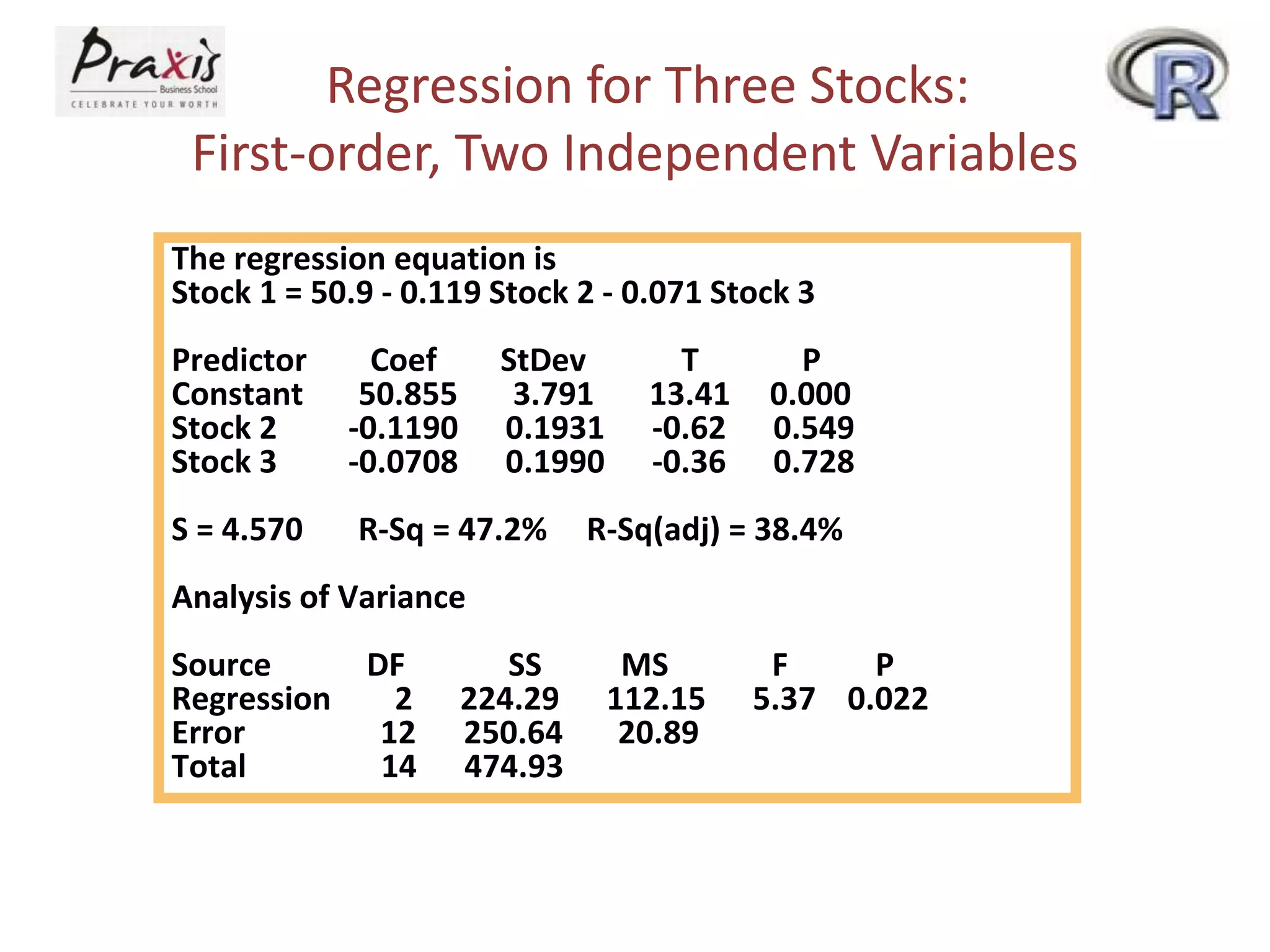
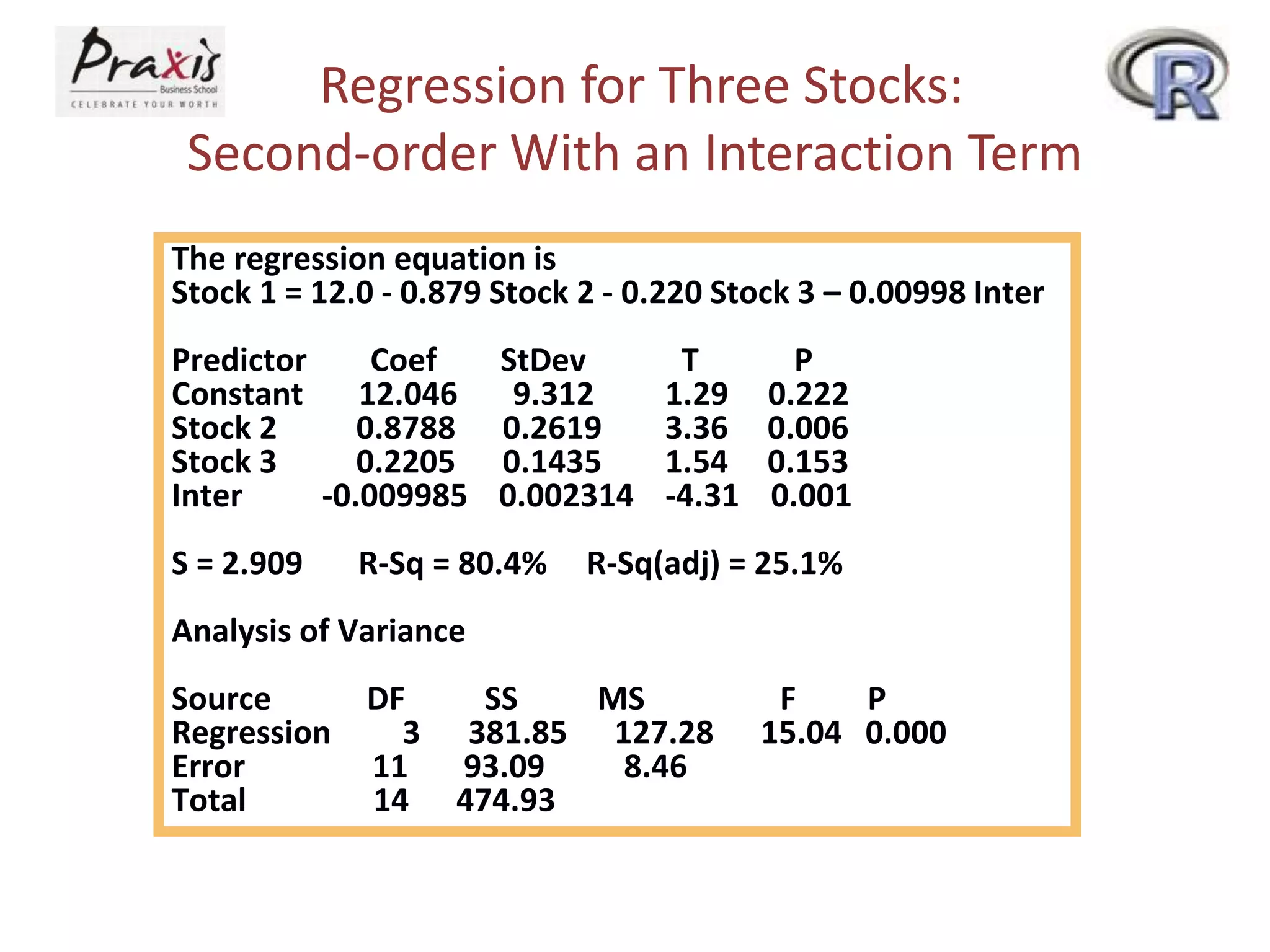
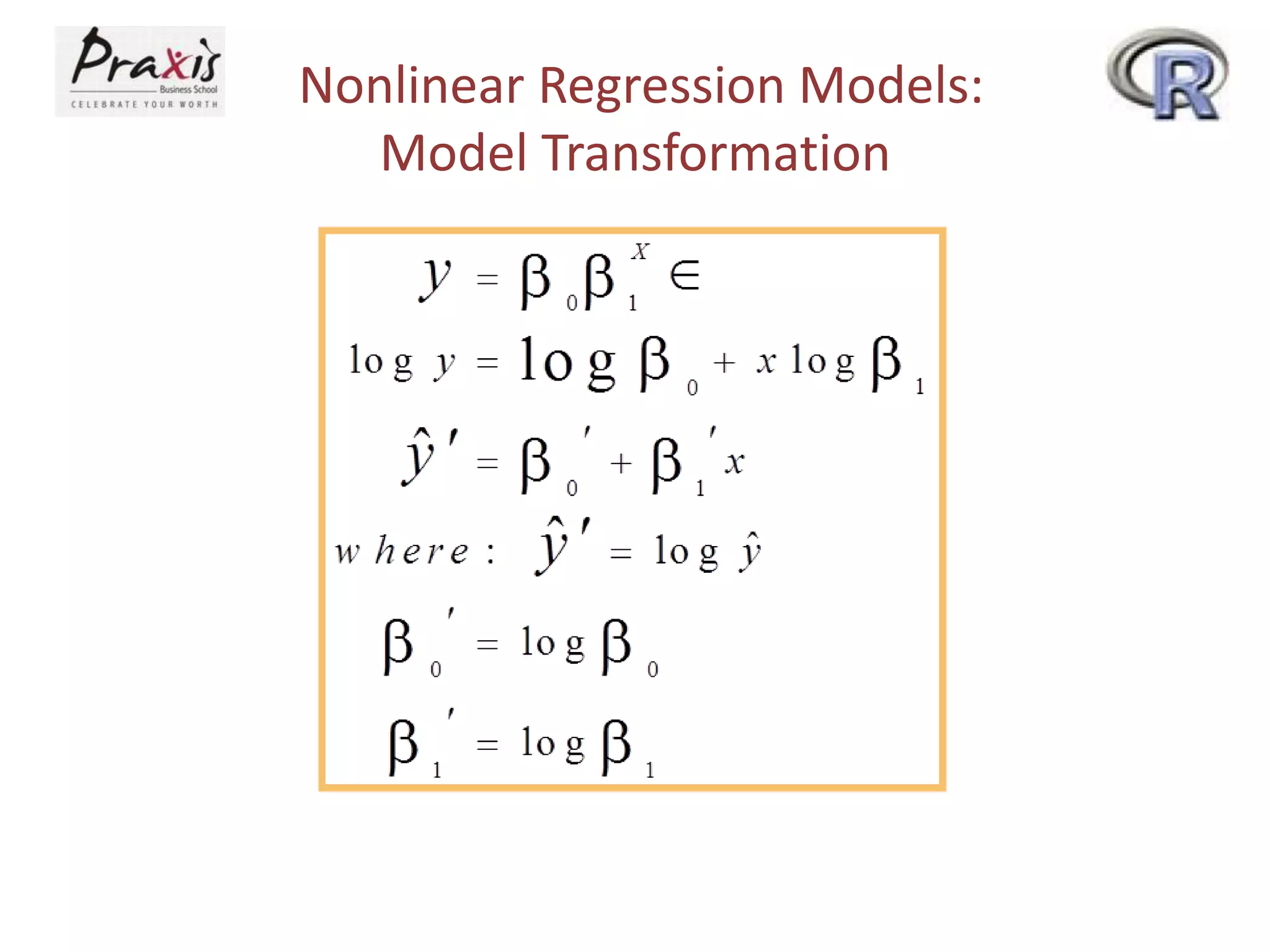
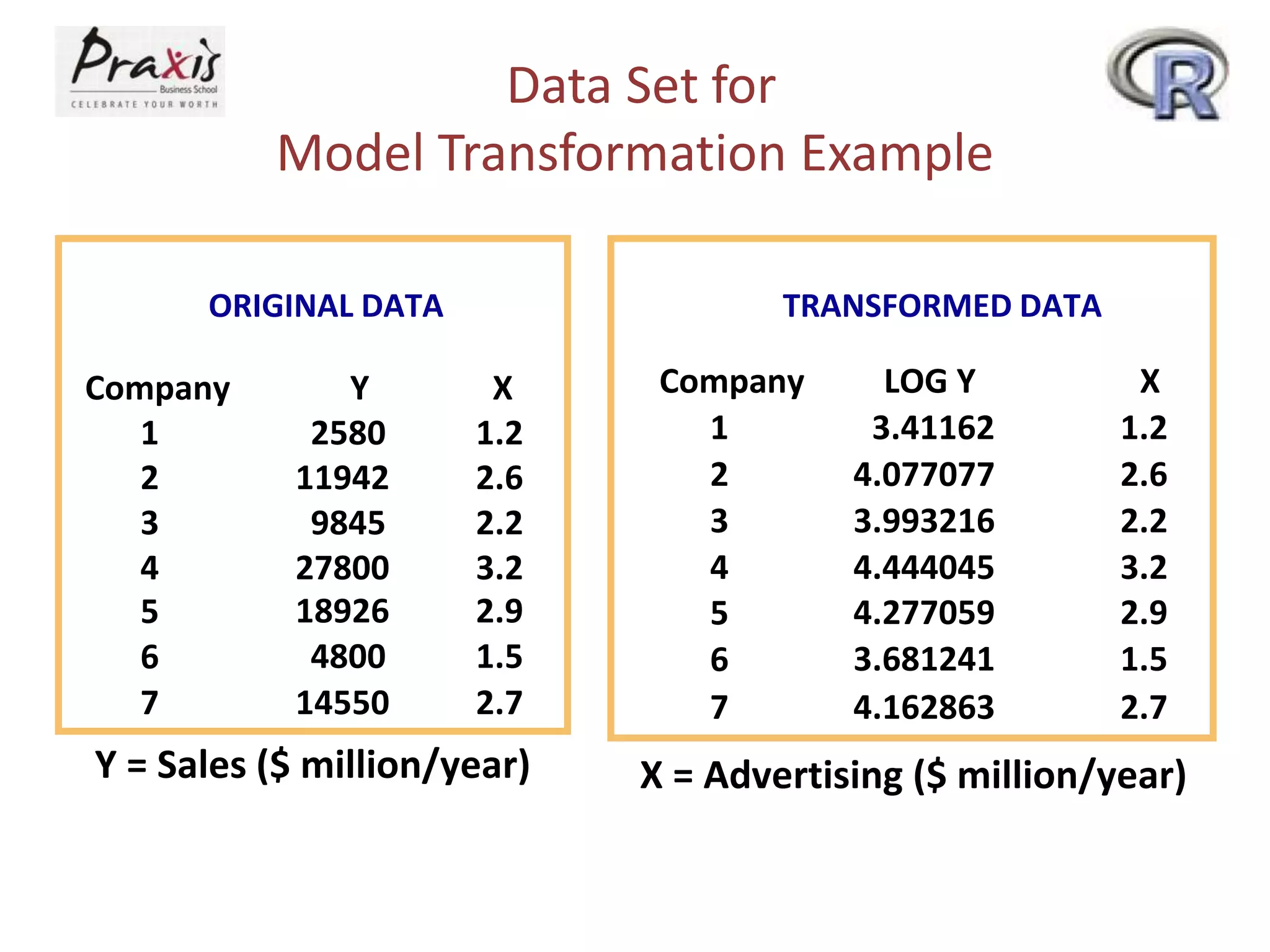
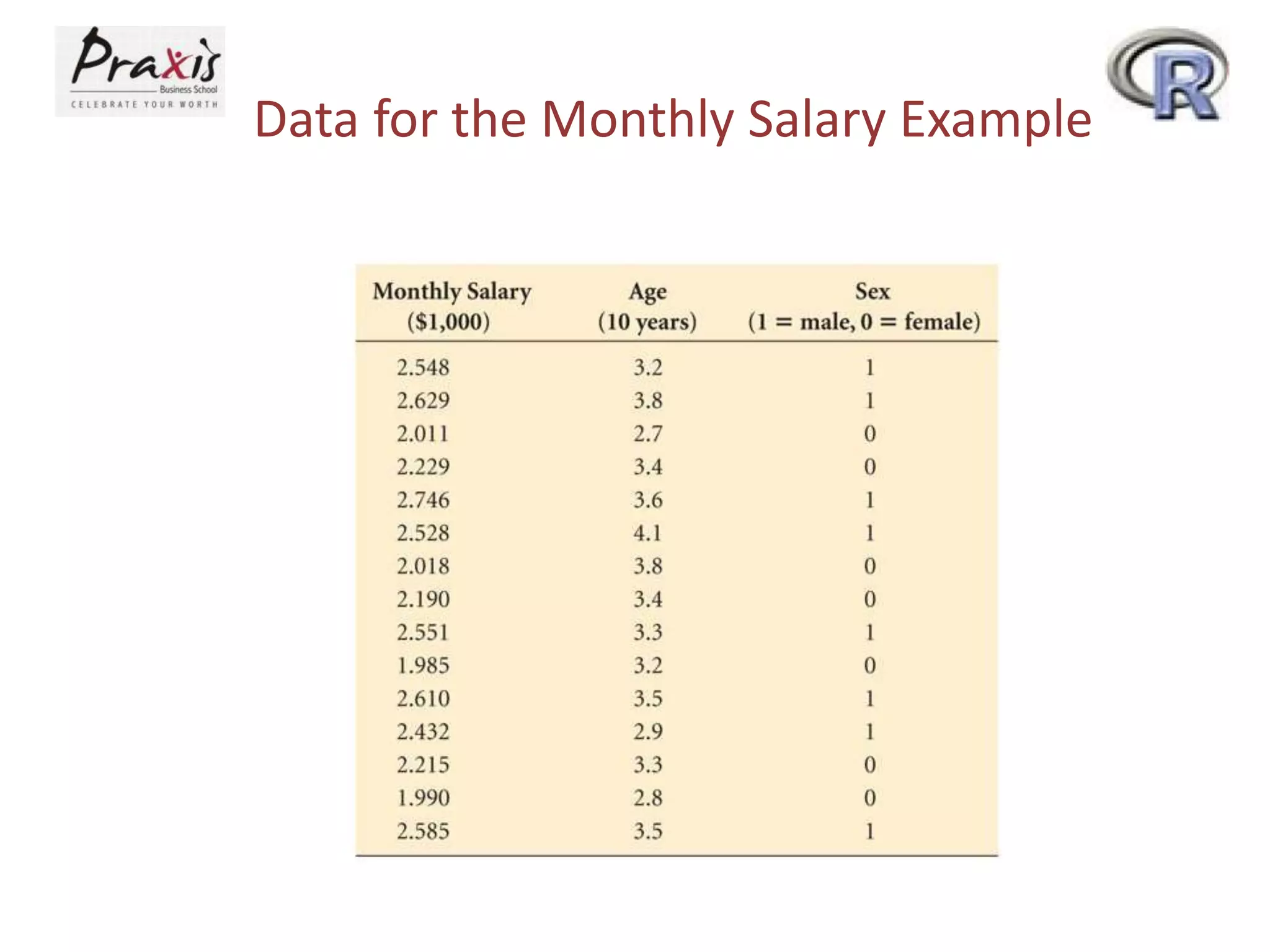
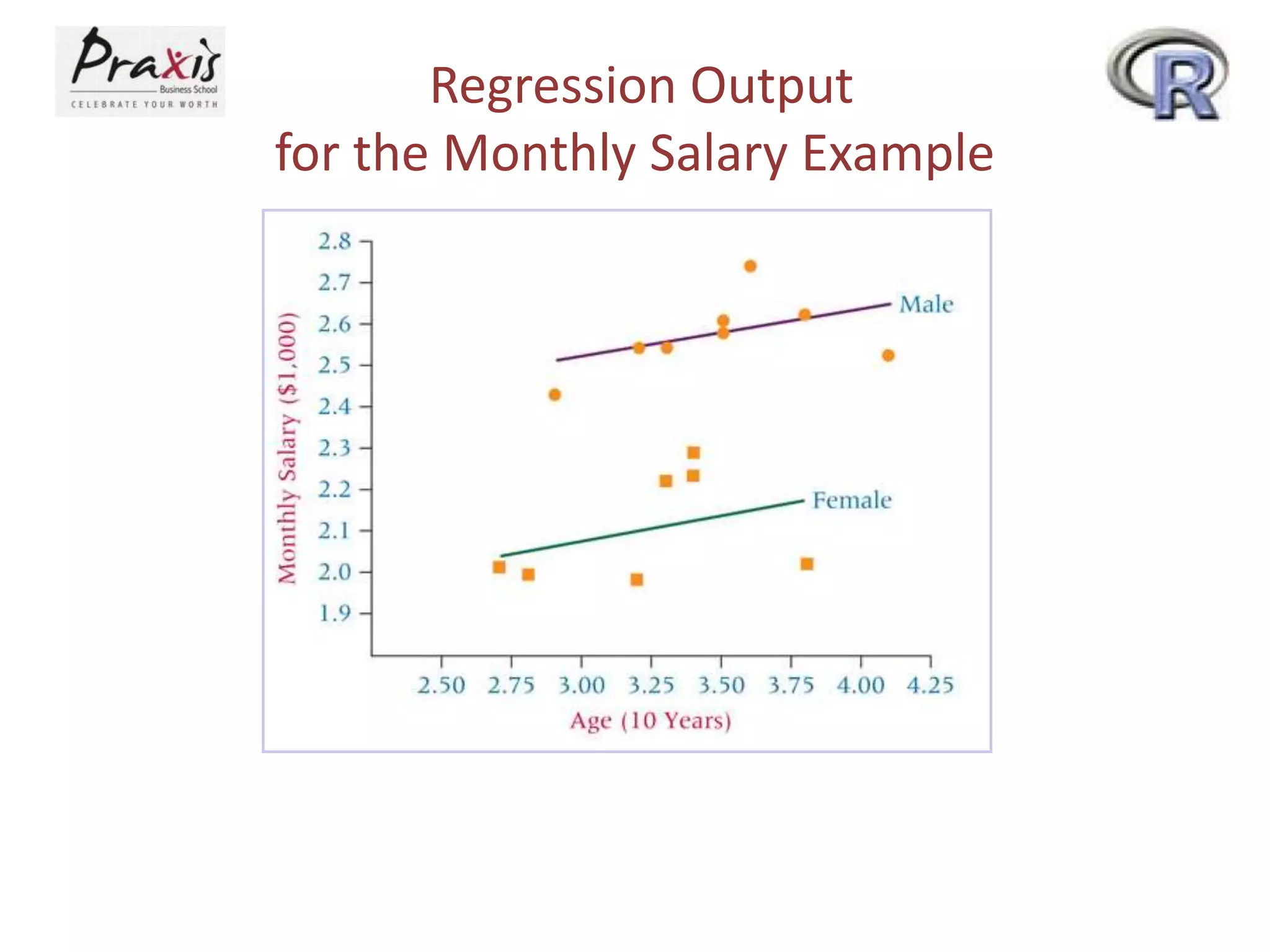
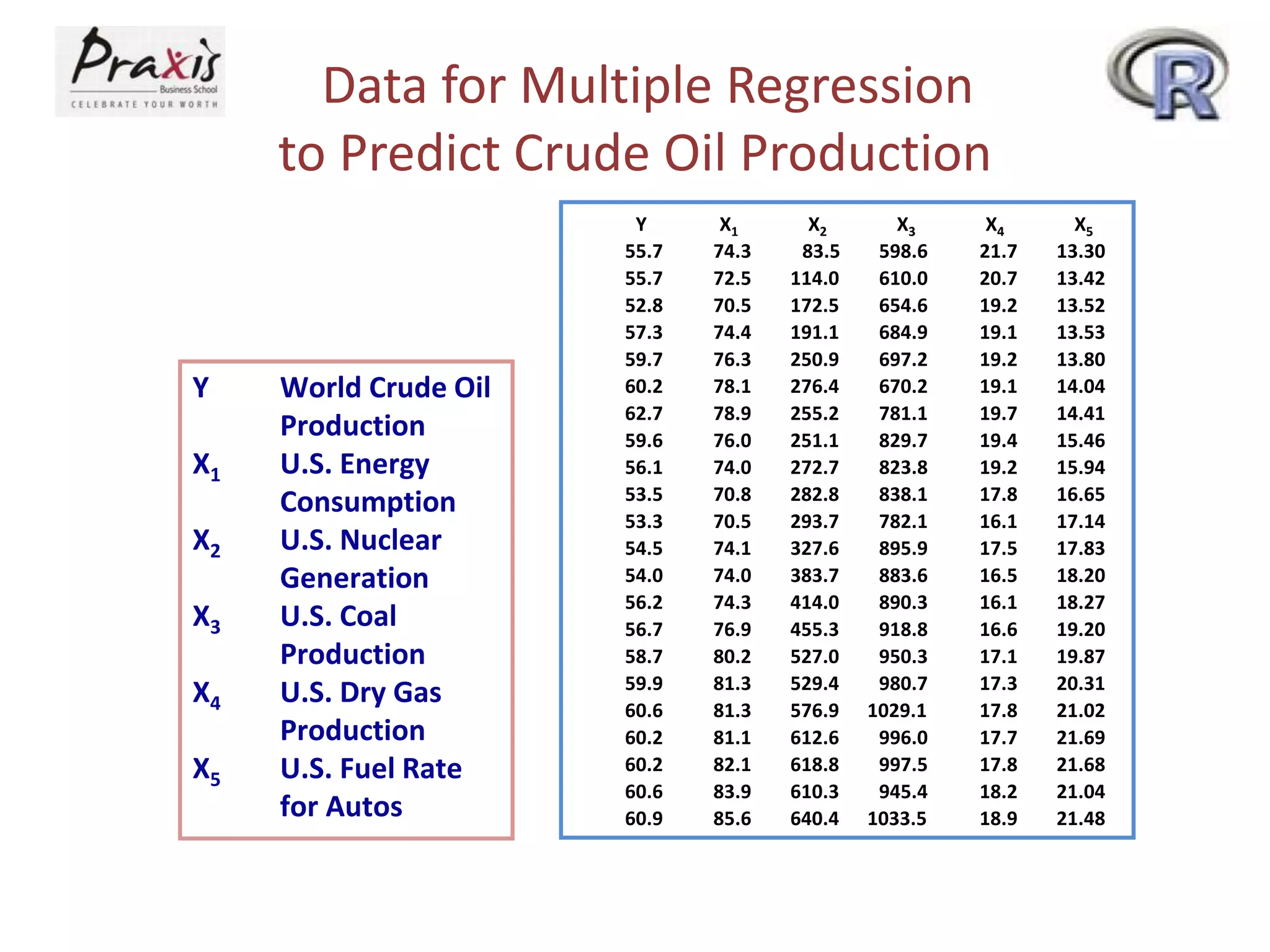
This document provides an overview of simple and multiple linear regression analysis. It discusses key concepts such as:
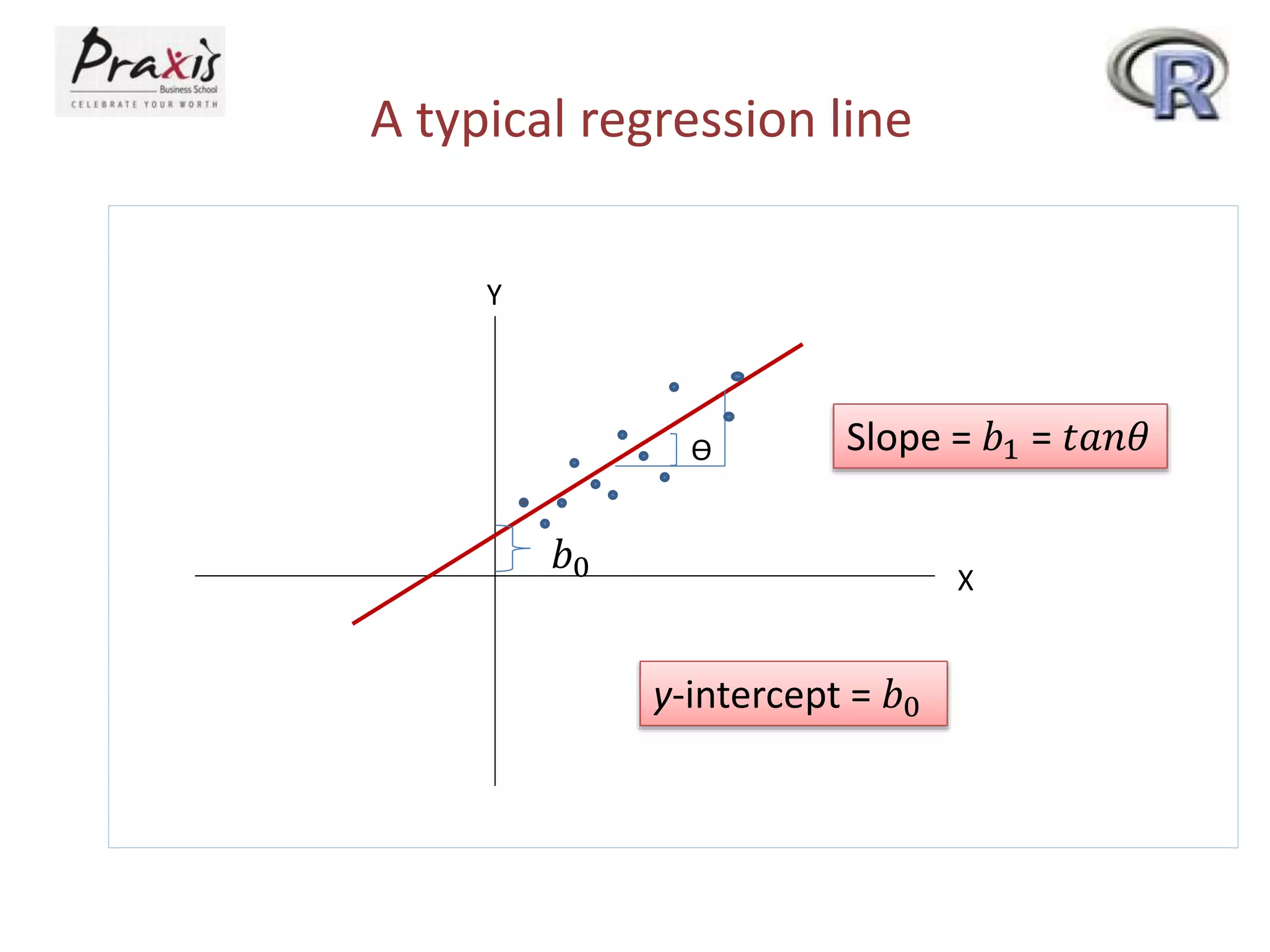
- Dependent and independent variables in bivariate linear regression
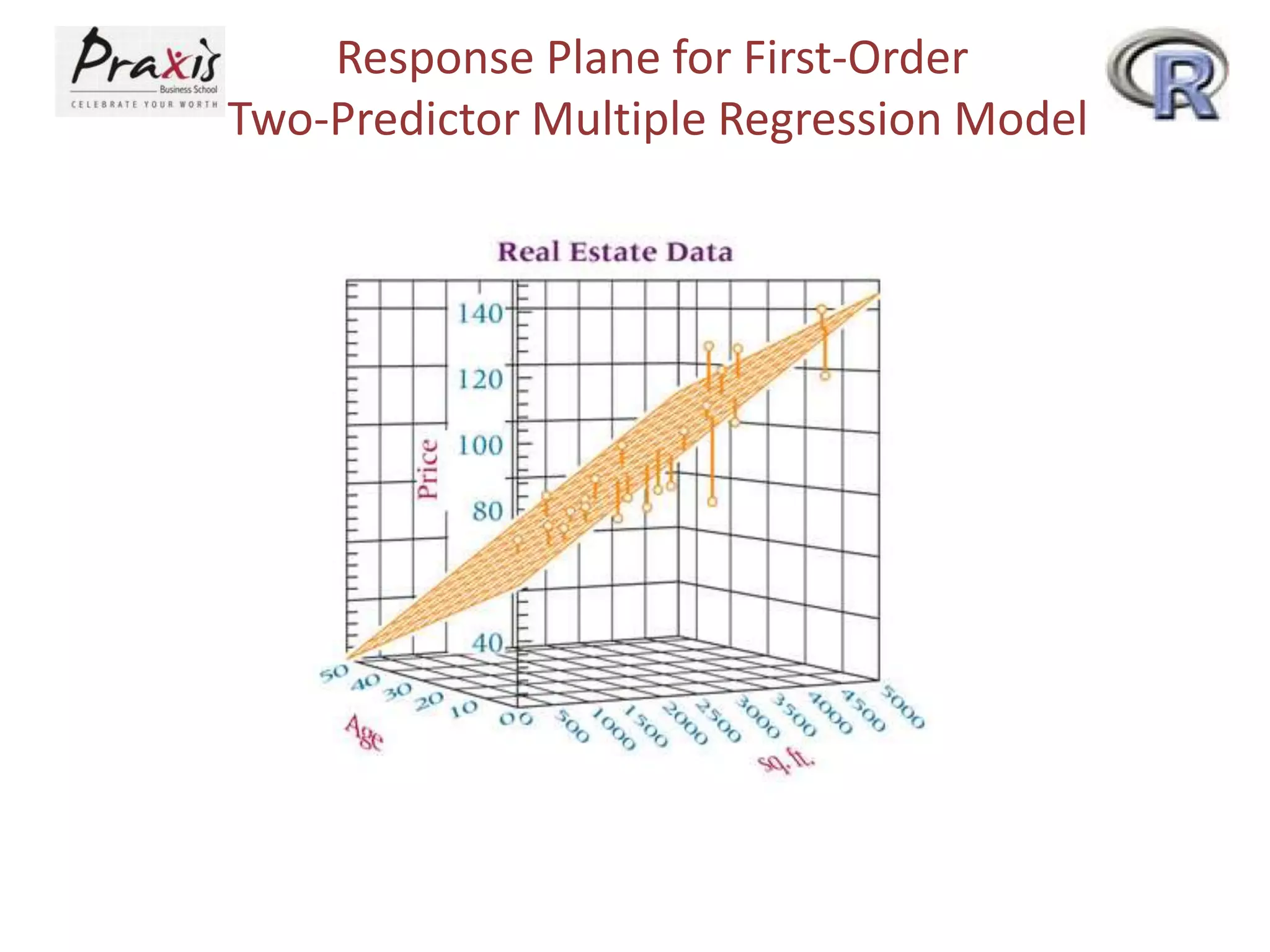
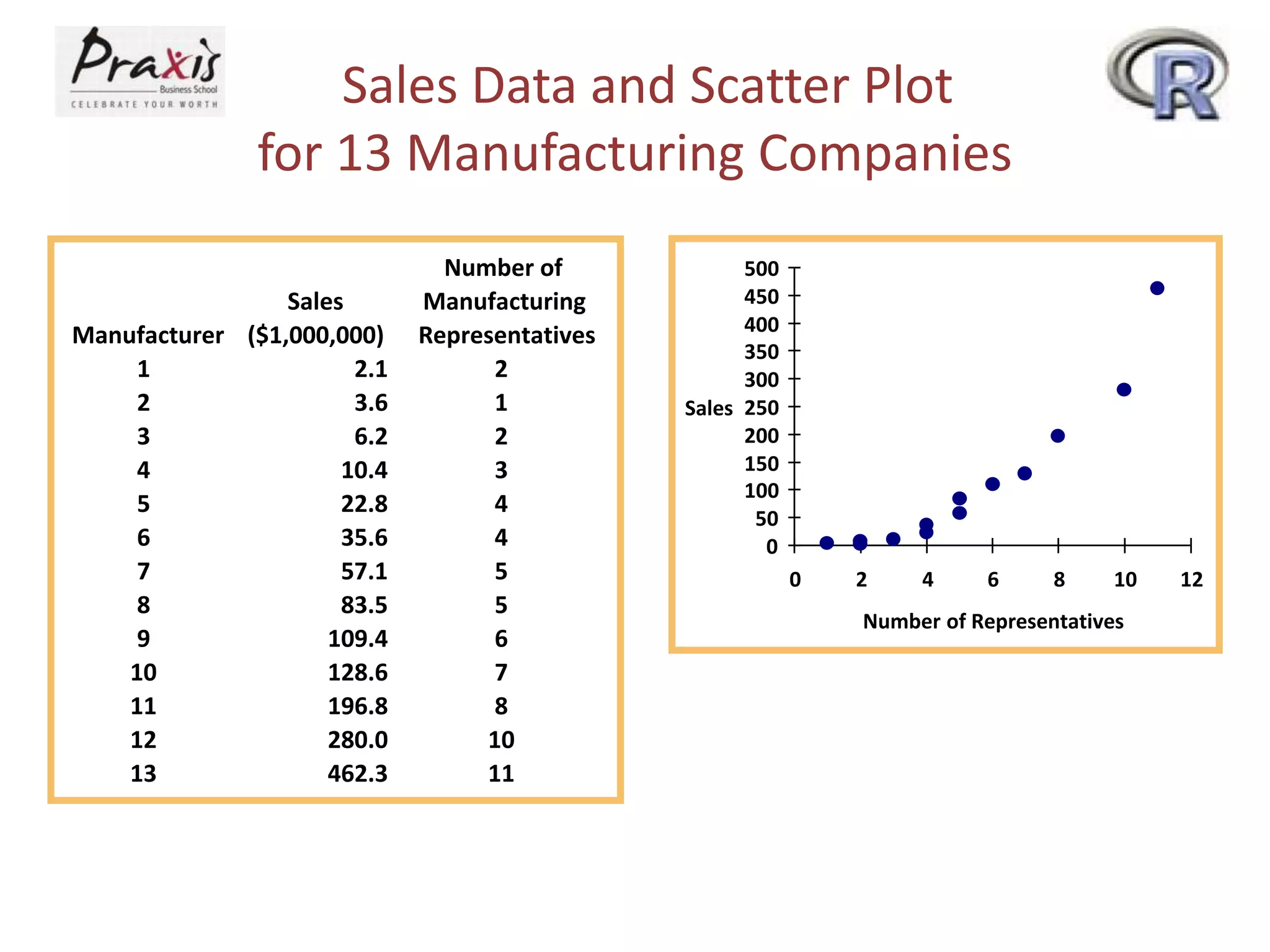
- Using scatter plots to explore relationships
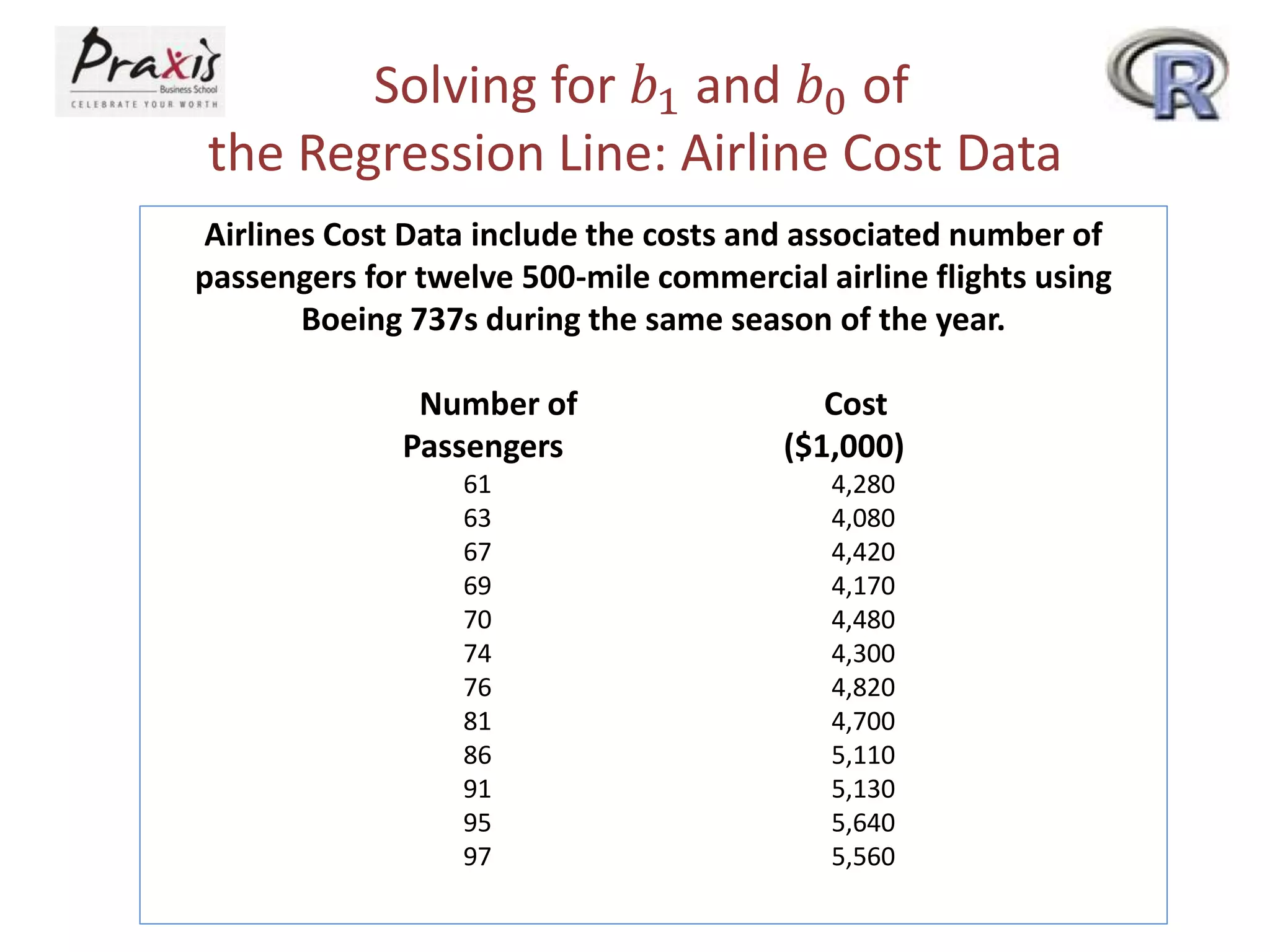
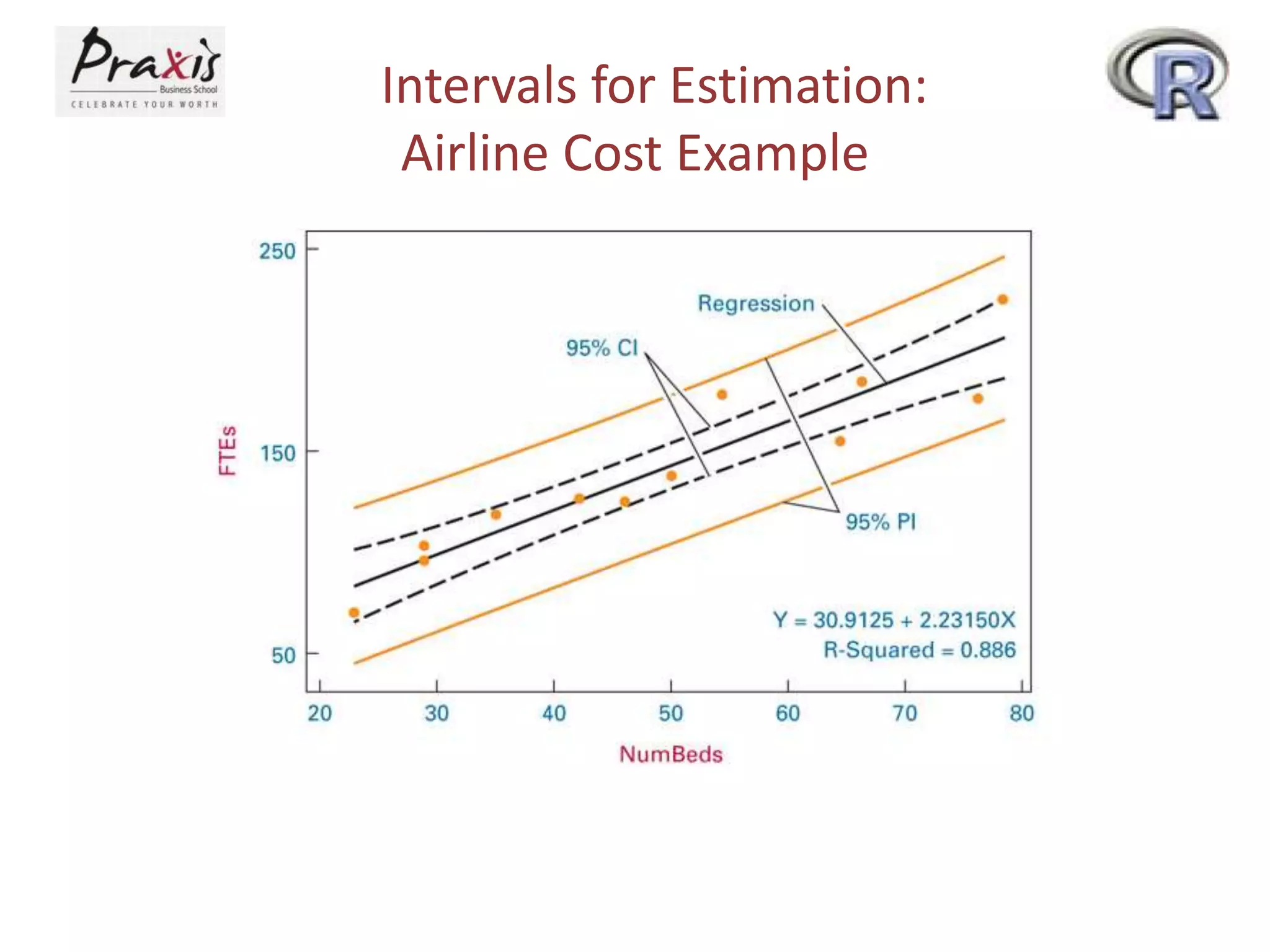
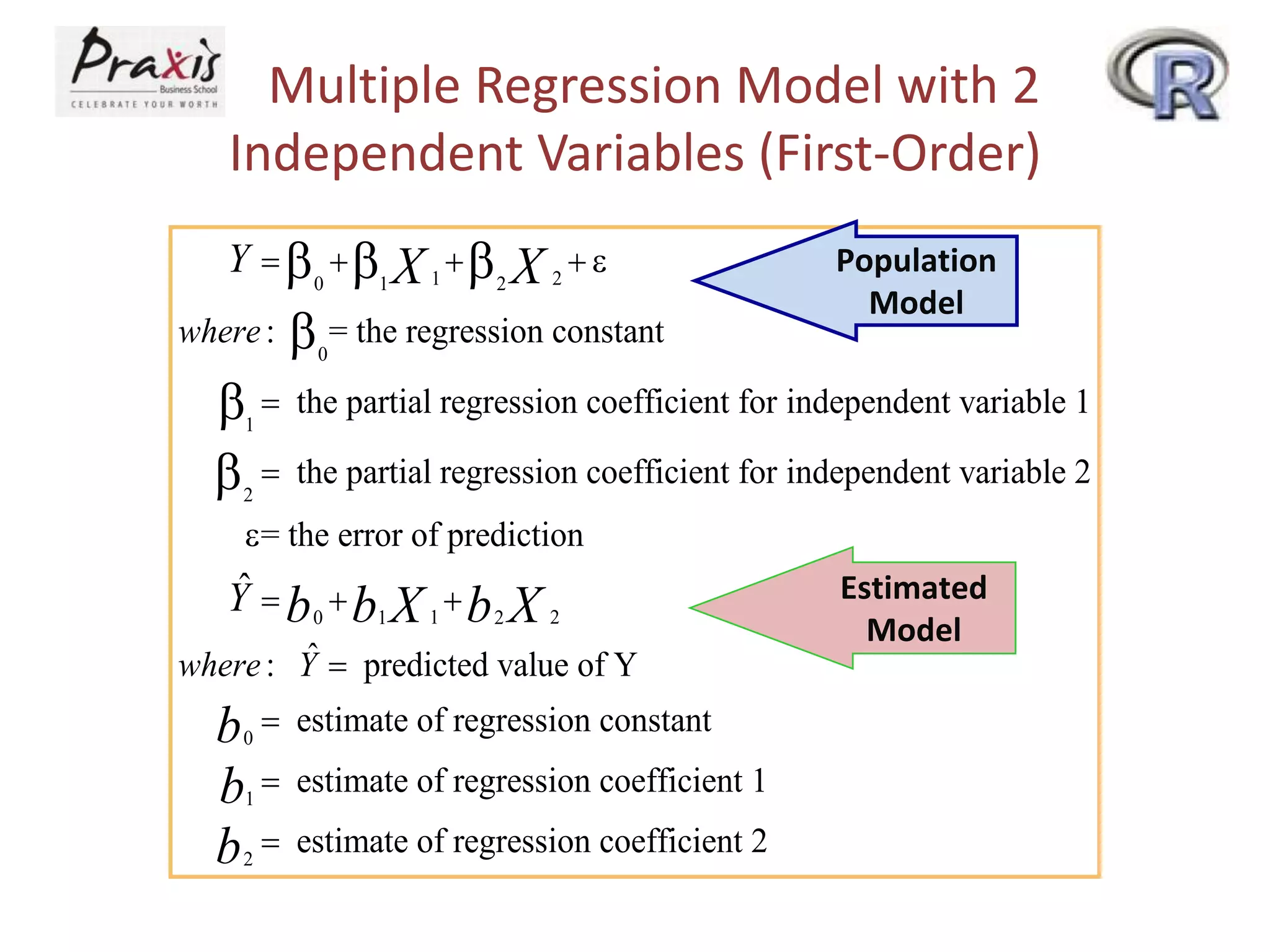
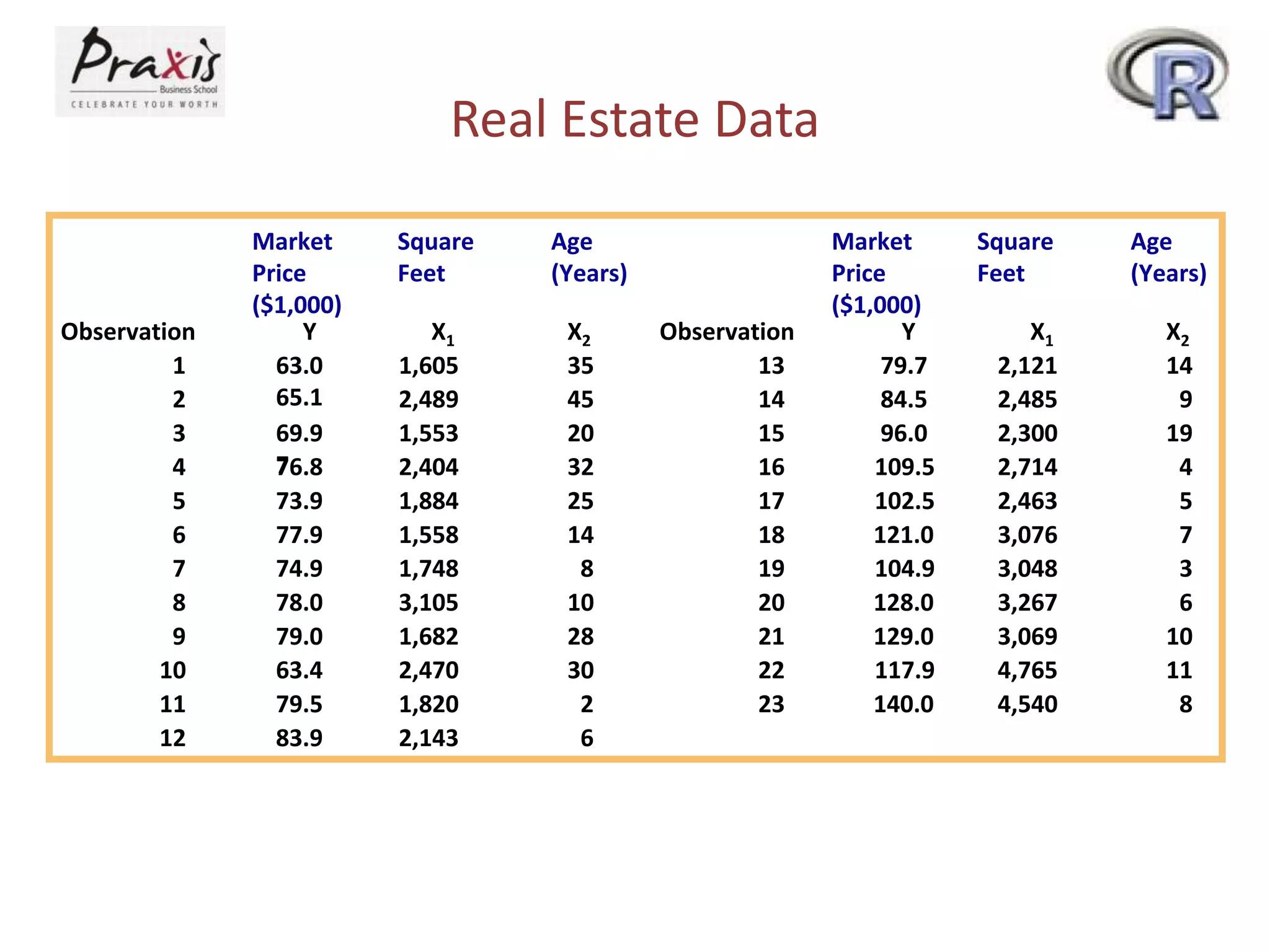
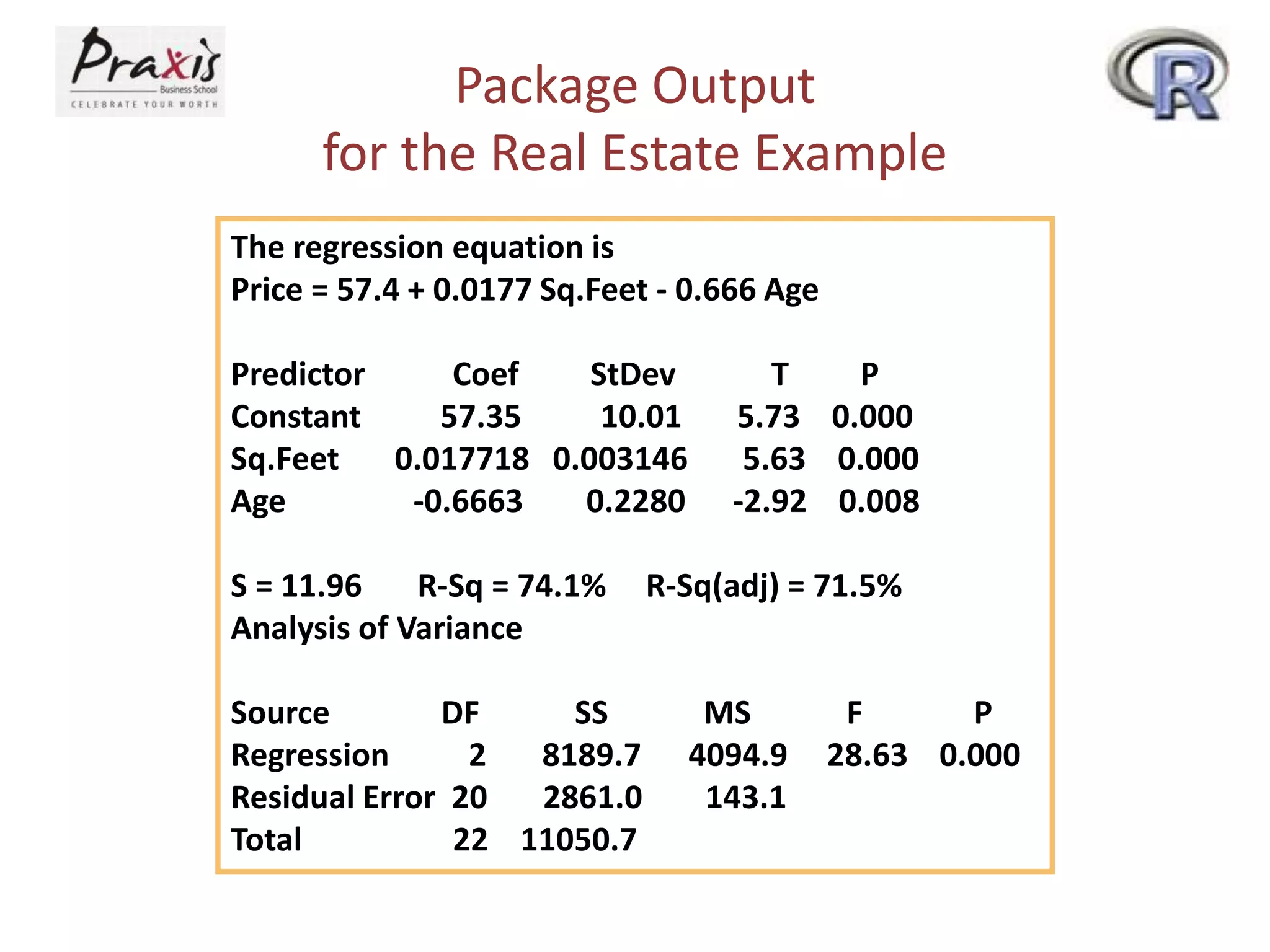
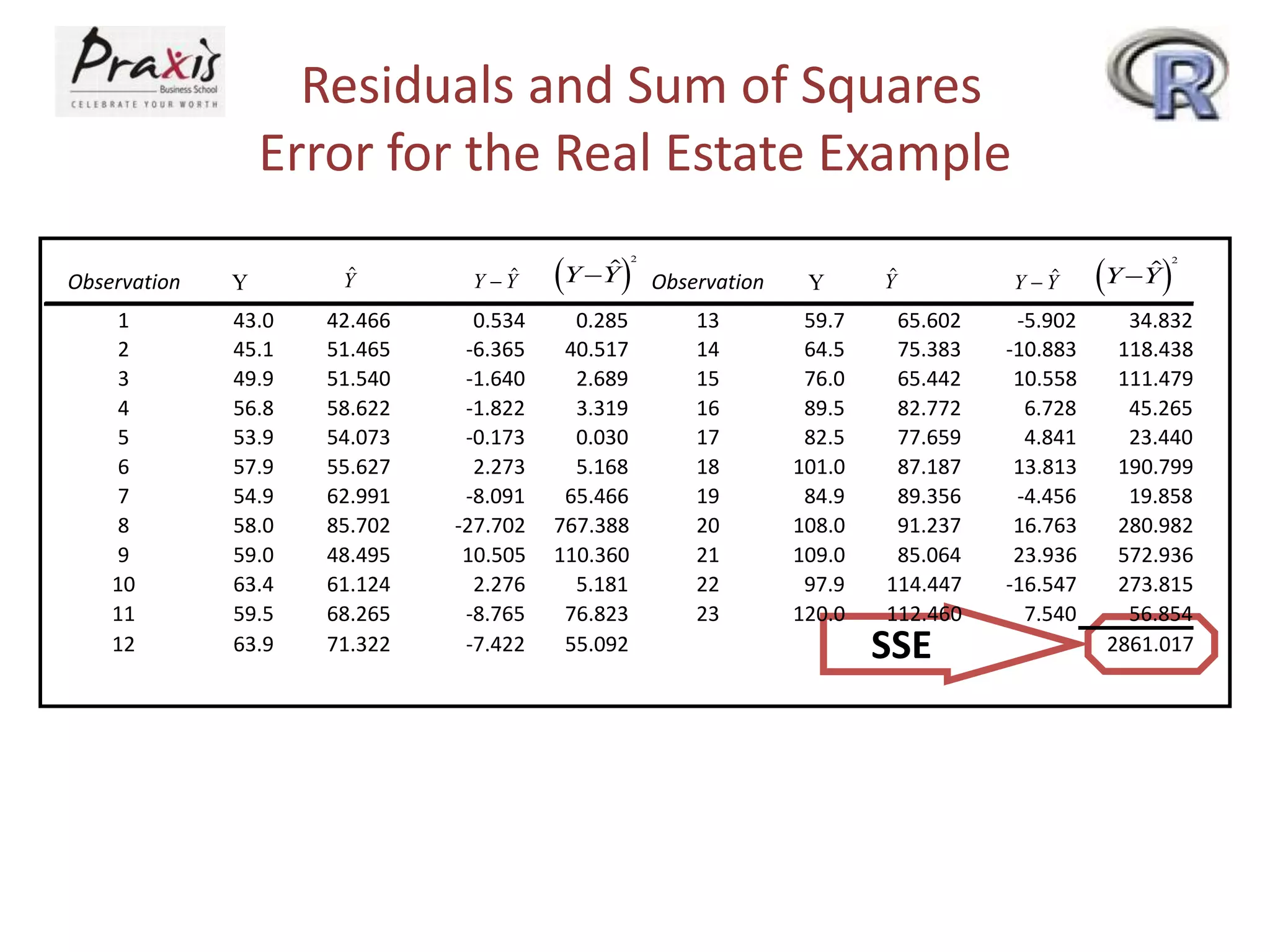
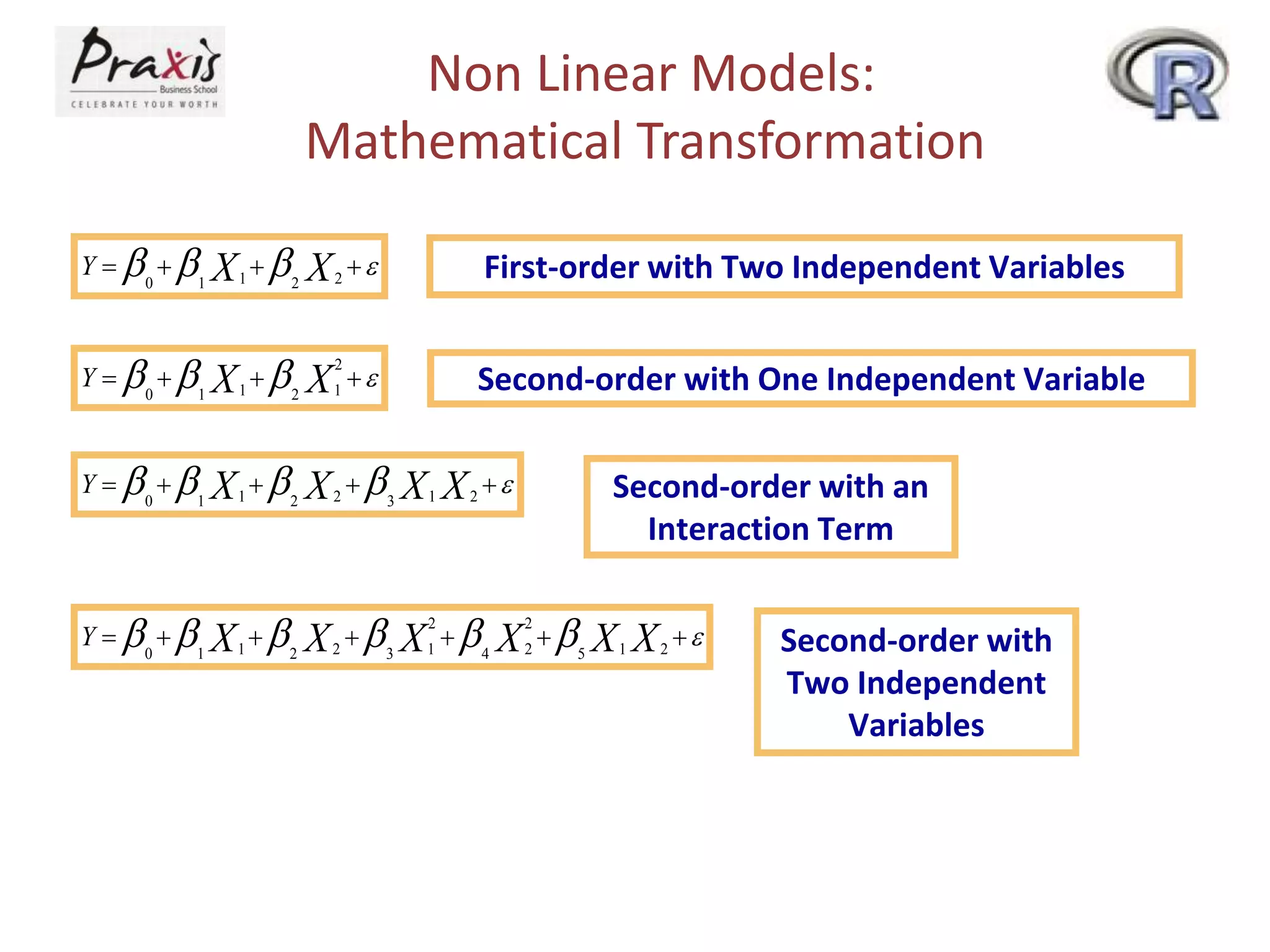
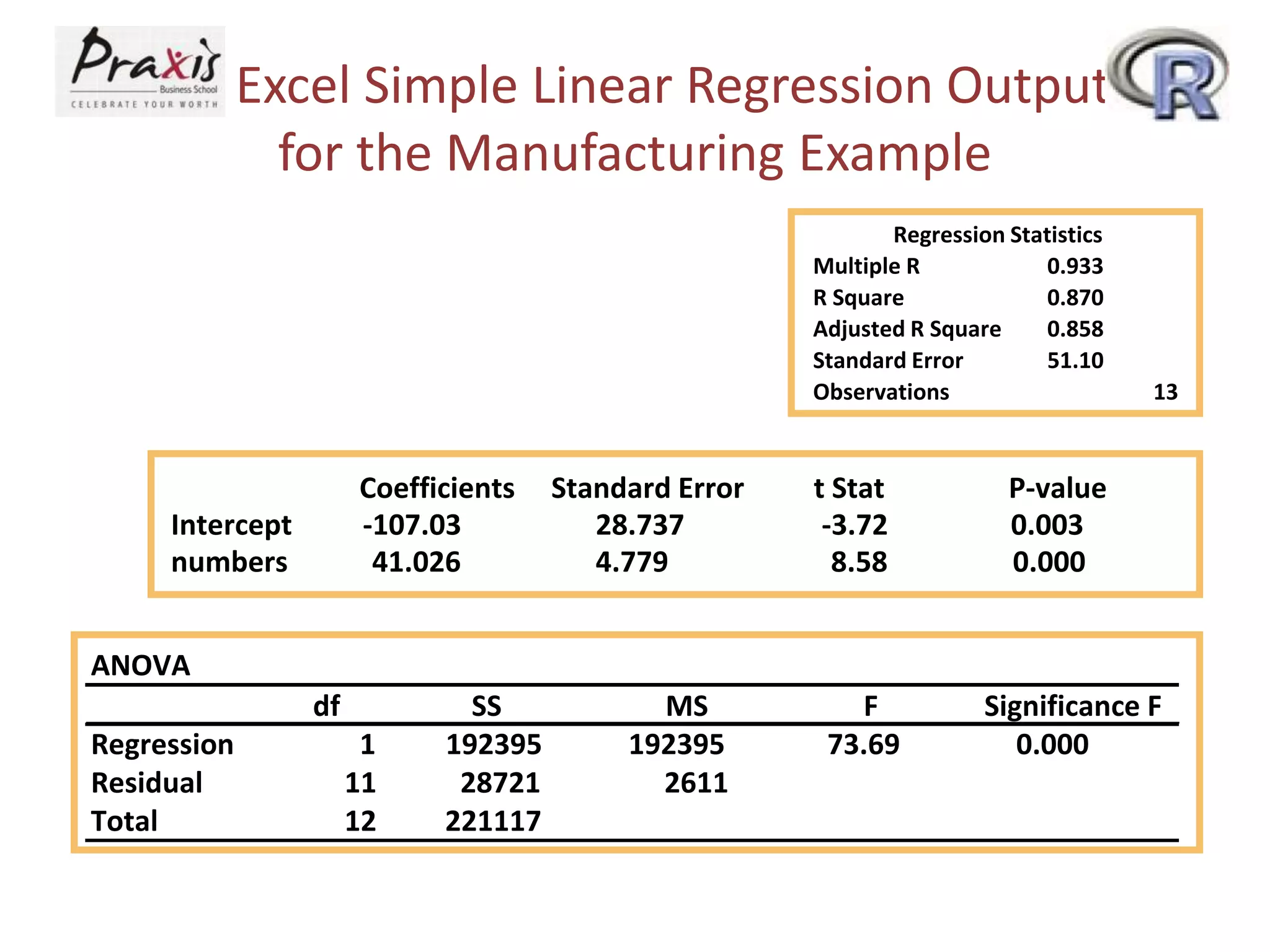
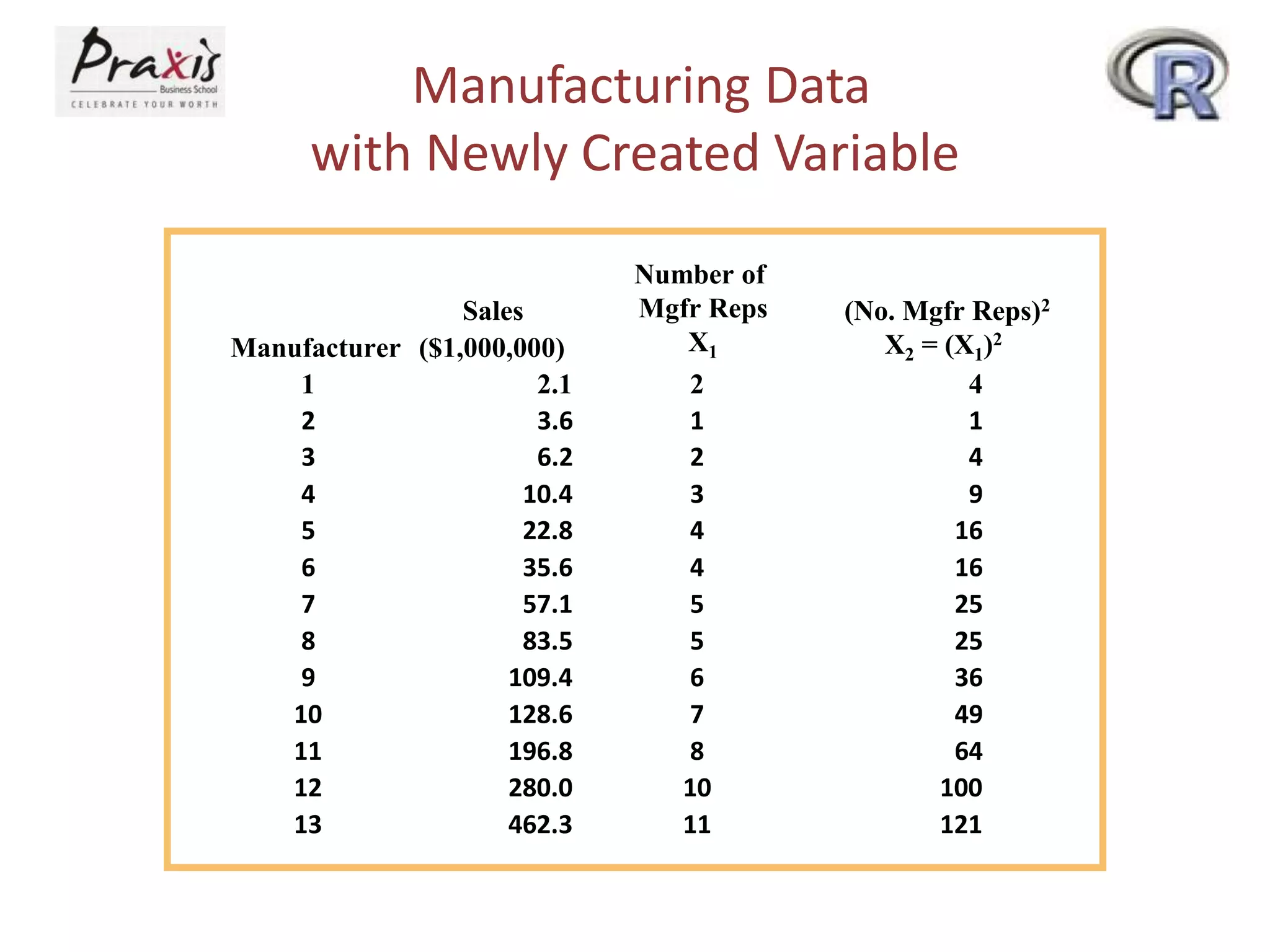
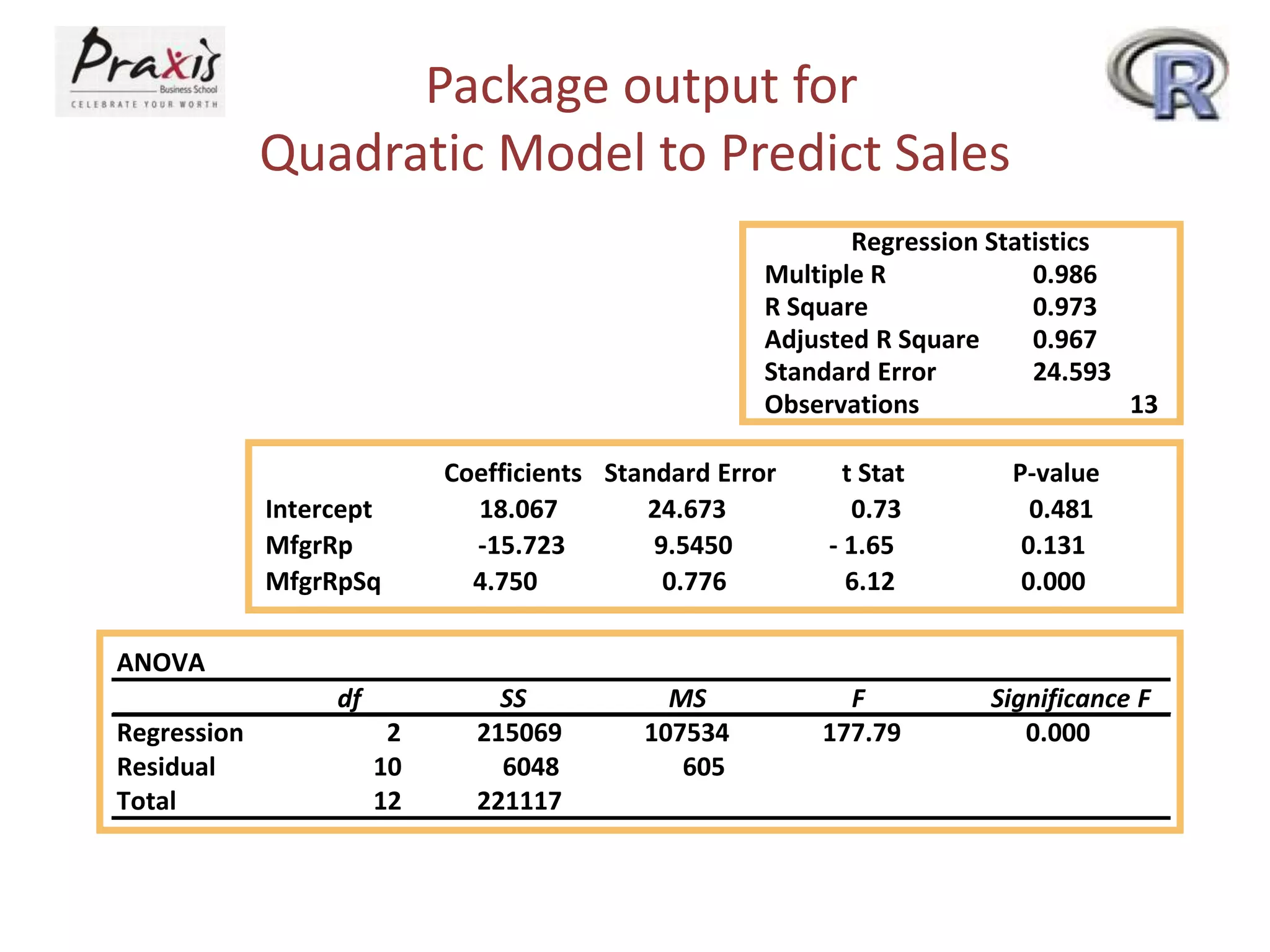
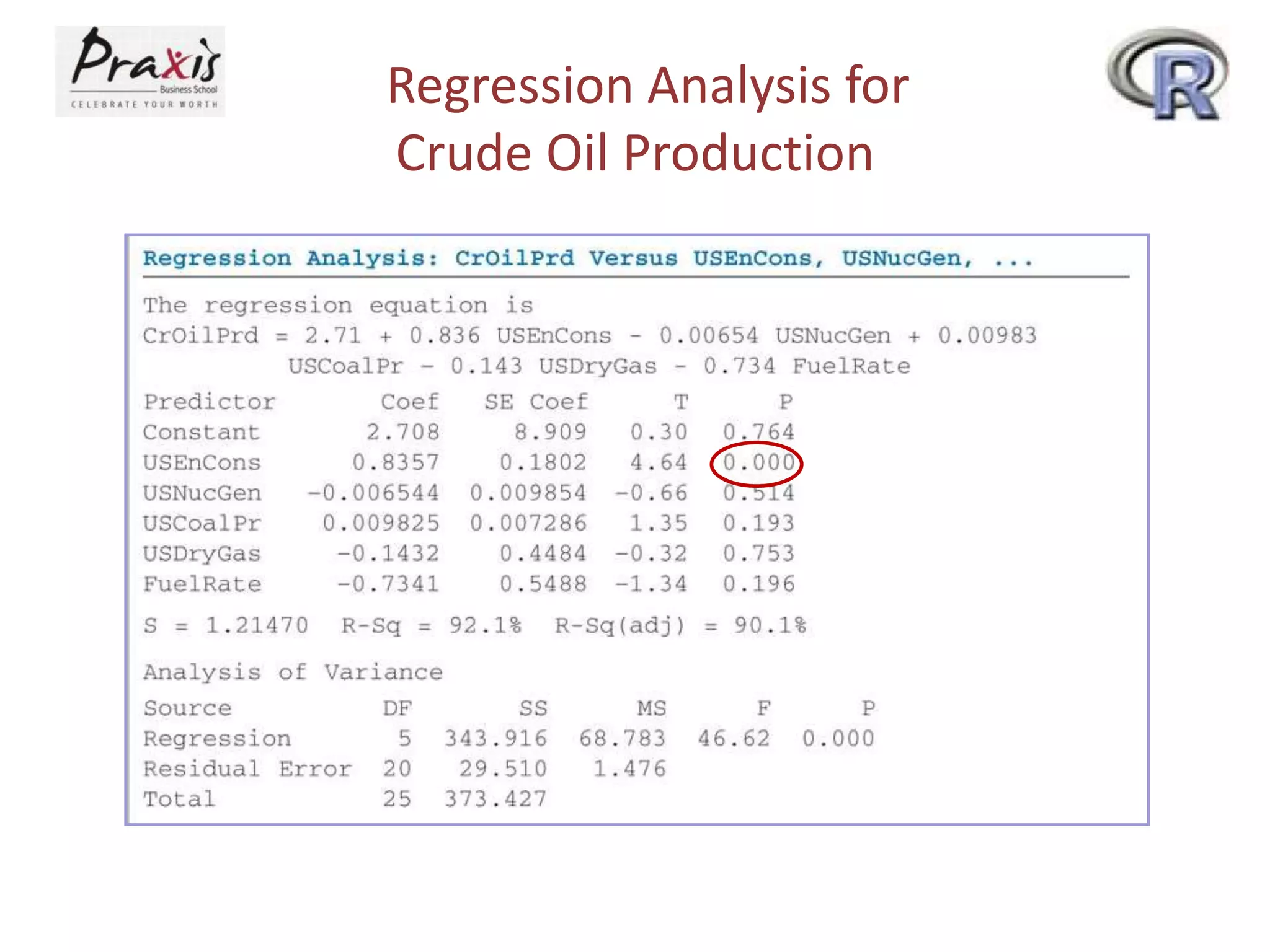
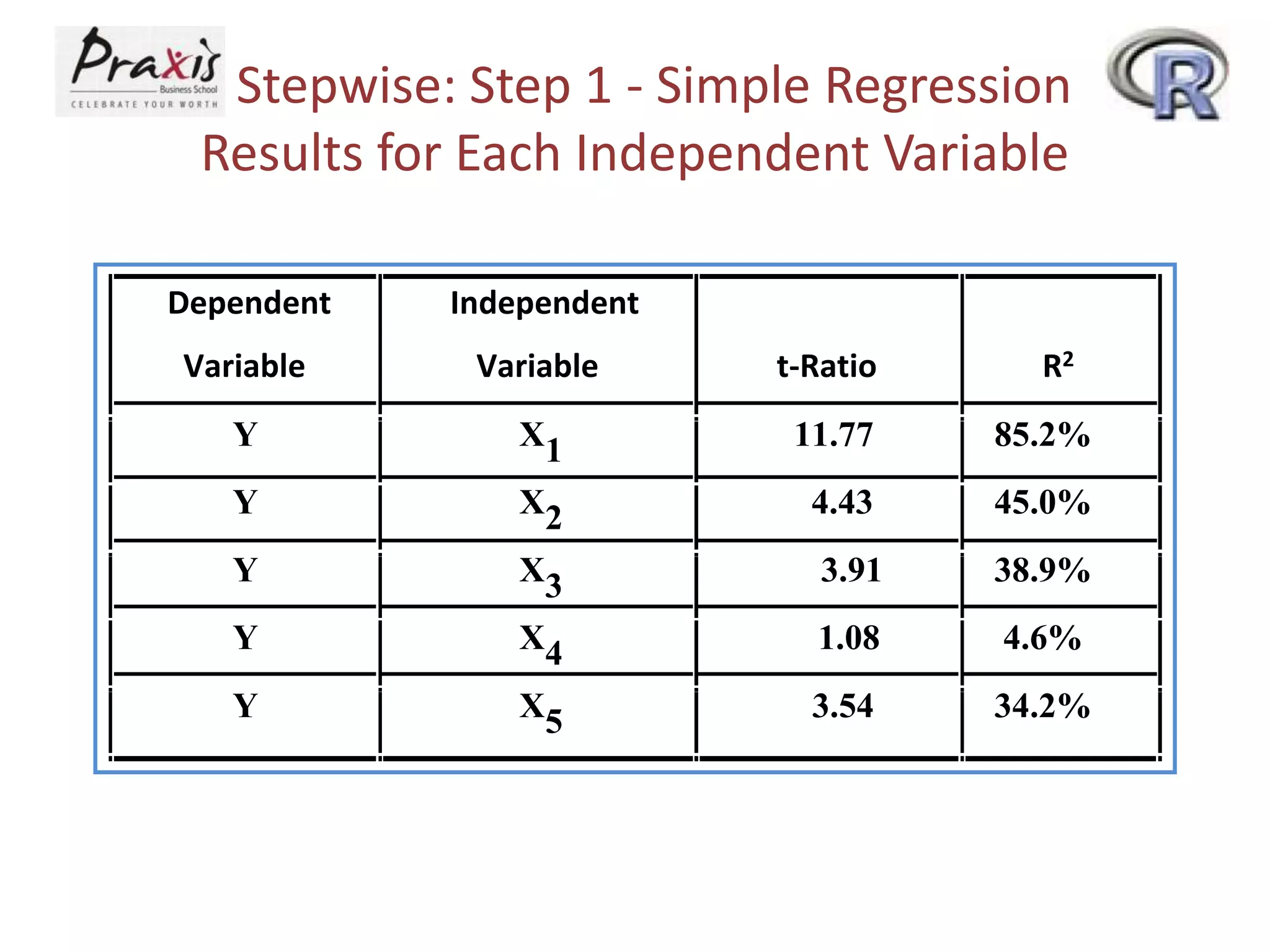
- Estimating regression coefficients and equations for simple and multiple regression models
- Using regression models to predict outcomes based on independent variable values
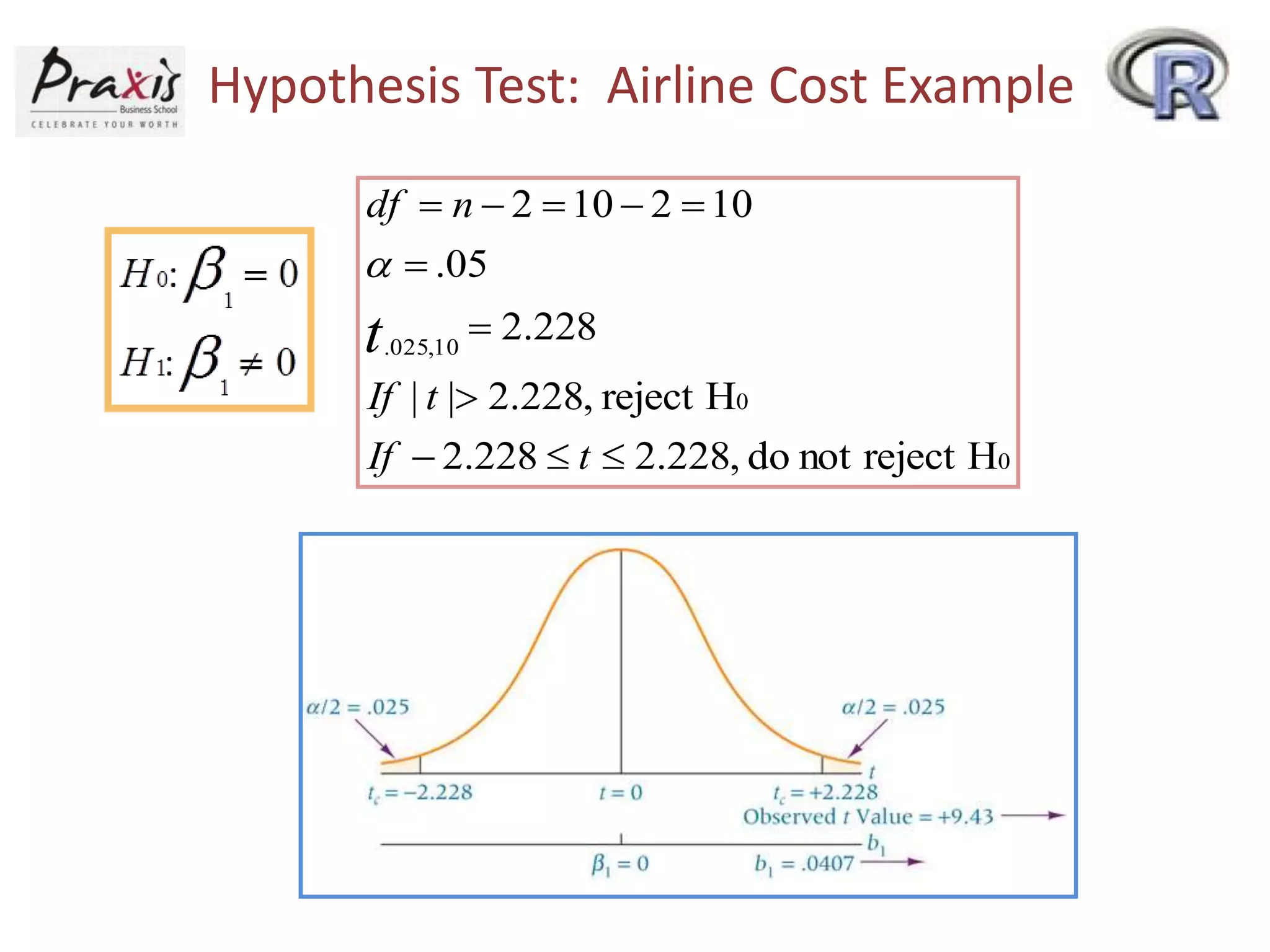
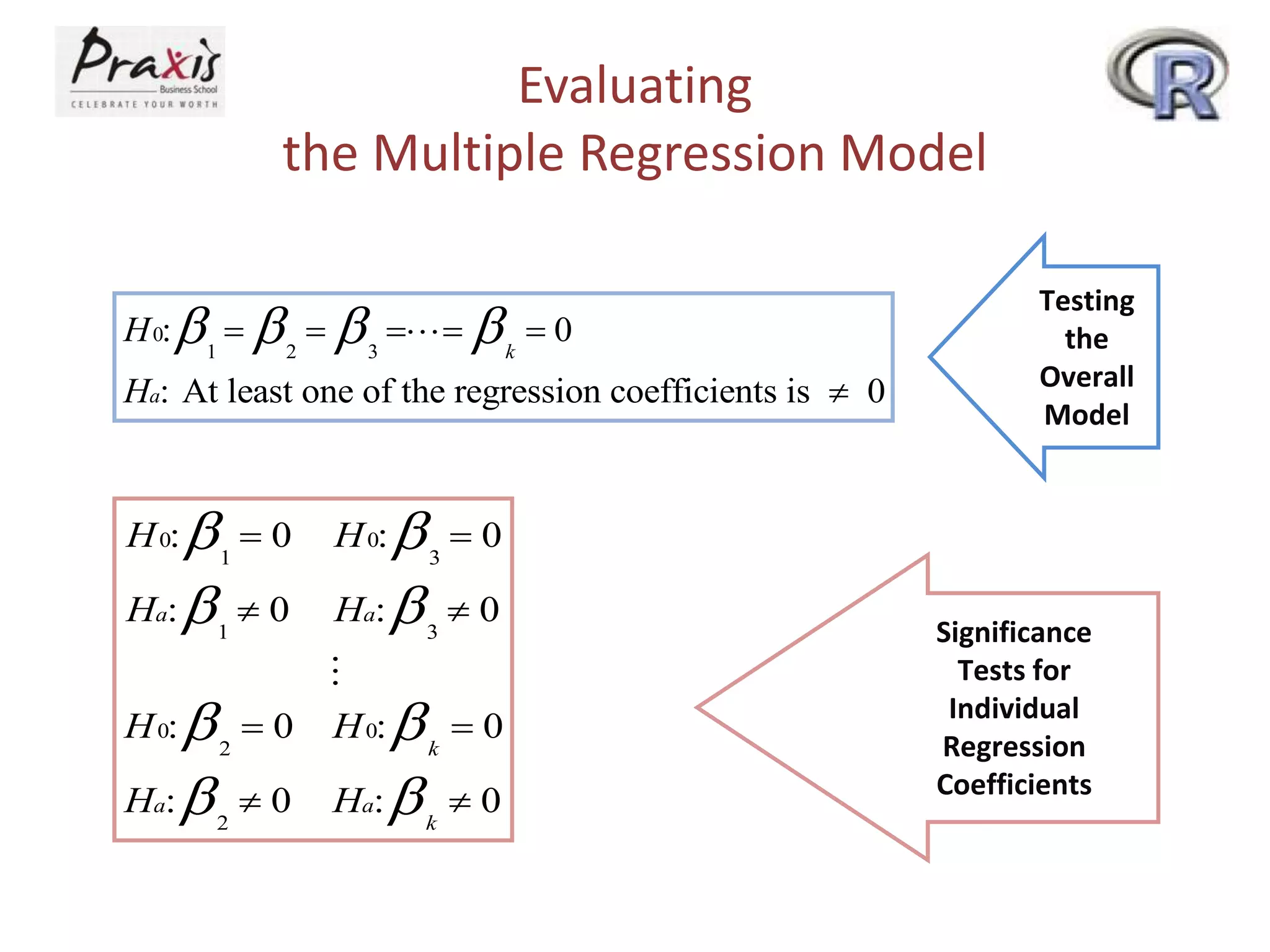
- Conducting statistical tests on overall regression models and individual coefficients