The document provides an introduction to basic operations and functions in R including:
- Creating and manipulating numeric vectors using functions like c(), mean(), max(), and indexing
- Creating and manipulating character vectors
- Using positive and negative indexing to subset vectors
- Appending values to existing vectors
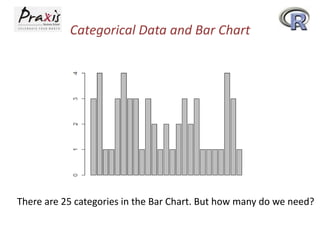
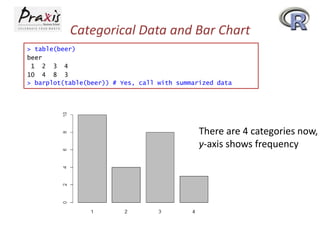
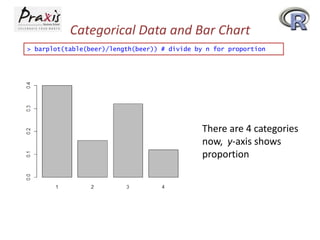
- Creating and summarizing categorical data using factors and functions like table()
- Creating bar plots and pie charts to visualize categorical data
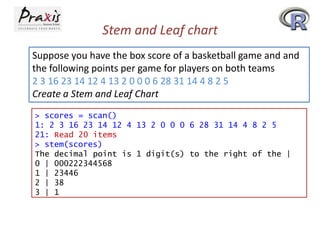
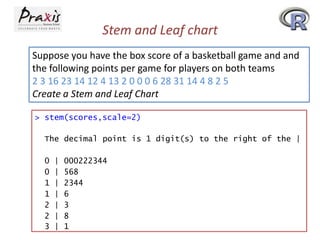
- Creating a stem-and-leaf plot to visualize a distribution
![Let’s start with R
> typos = c(2,3,0,3,1,0,0,1)
> typos
[1] 2 3 0 3 1 0 0 1
> mean(typos)
[1] 1.25
> median(typos)
[1] 1
> var(typos)
[1] 1.642857
•
•
•
•
“typos” represent number of typing errors on different pages
Note that each command is stored in history
You can use UP arrow key to retrieve your previous command
You have started using built-in functions](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-1-320.jpg)
![Let’s start with R
> typos = c(2,3,0,3,1,0,0,1)
> typos
[1] 2 3 0 3 1 0 0 1
> mean(typos)
[1] 1.25
> median(typos)
[1] 1
> var(typos)
[1] 1.642857
•
•
•
•
“typos” represent number of typing errors on different pages
Note that each command is stored in history
You can use UP arrow key to retrieve your previous command
You have started using built-in functions](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/75/R-part-I-1-2048.jpg)
![Let’s start with R
> typos.draft1 = c(2,3,0,3,1,0,0,1)
> typos.draft2 = c(0,3,0,3,1,0,0,1)
> typos.draft1
[1] 2 3 0 3 1 0 0 1
> typos.draft2
[1] 0 3 0 3 1 0 0 1
• Note the two different object names for two drafts
• Period has been used as punctuation in object names
• Both the object names represent a vector](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-2-320.jpg)
![Let’s start with R
> typos.draft1 = c(2,3,0,3,1,0,0,1)
> typos.draft2 = typos.draft1 # make a copy
> typos.draft2[1] = 0 # assign the first page 0 typing error
> typos.draft2
[1] 0 3 0 3 1 0 0 1
• Note how we have created the same typos.draft2
• “#” has been used for comments
• ‘()’ are for functions and ‘*+’ are for vectors](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-3-320.jpg)
![Now try and check ….
> typos.draft2 # print out the value
[1] 0 3 0 3 1 0 0 1
> typos.draft2[2] # print 2nd pages' value
[1] 3
> typos.draft2[4] # 4th page
[1] 3
> typos.draft2[-4] # all but the 4th page
[1] 0 3 0 1 0 0 1
> typos.draft2[c(1,2,3)] # print values for 1st, 2nd and 3rd.
[1] 0 3 0
• Note the output of the last command. This is called Slicing.](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-4-320.jpg)
![Numeric Vector
• Simplest data structure in R
• To set up a numeric vector named x assign values :
> x <- c(23.0,17.0,12.5,11.0,17.0,12.0,14.5,9.0,11.0)
> x
[1] 23.0 17.0 12.5 11.0 17.0 12.0 14.5 9.0 11.0
Or
> assign ("x", c(23.0,17.0,12.5,11.0,17.0,12.0,14.5,9.0,11.0))
> x
[1] 23.0 17.0 12.5 11.0 17.0 12.0 14.5 9.0 11.0](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-5-320.jpg)
![Numeric Vector
or
> rm(x)
> c(23.0,17.0,12.5,11.0,17.0,12.0,14.5,9.0,11.0) -> x
> x
[1] 23.0 17.0 12.5 11.0 17.0 12.0 14.5 9.0 11.0
Look at the next assignment
> y <- c(x,0,1)
> y
[1] 23.0 17.0 12.5 11.0 17.0 12.0 14.5
9.0 11.0
0.0
1.0
A vector y has been created with a copy of x with a zero and one
at the end.](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-6-320.jpg)
![Character Vector
A character vector is a set of text values
> weekdays <- c("Sun","Mon","Tues","Wed","Thurs","Fri","Sat")
> weekdays
[1] "Sun"
"Mon"
"Tues" "Wed"
"Thurs" "Fri"
"Sat"](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-7-320.jpg)
![Positive Index
• A positive index can appended in square brackets to the name
of a vector
• It helps to select subsets of the elements of a vector
> x[2]
[1] 17
> x[1:9]
[1] 23.0 17.0 12.5 11.0 17.0 12.0 14.5
> x[3:7]
[1] 12.5 11.0 17.0 12.0 14.5
> x[c(2,5,7)]
[1] 17.0 17.0 14.5
9.0 11.0
• How do you find the number of elements in a vector?
> X
[1] 23.0 17.0 12.5 11.0 17.0 12.0 14.5
>length(x)
[1] 9
9.0 11.0](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-8-320.jpg)
![Negative Index
• A negative index specifies the element(s) to be excluded
rather than included
> y<-x[-2] #Include all but the second element
> y
[1] 23.0 12.5 11.0 17.0 12.0 14.5 9.0 11.0
> x
[1] 23.0 17.0 12.5 11.0 17.0 12.0 14.5 9.0 11.0
• How do you exclude more than one element?
> X
[1] 23.0 17.0 12.5 11.0 17.0 12.0 14.5 9.0 11.0
> y<-x[-(2:4)]
> y
[1] 23.0 17.0 12.0 14.5 9.0 11.0
> y<-x[-(c((2:4),9))] #exclude 2nd to 4th, and 9th elements
> y
[1] 23.0 17.0 12.0 14.5 9.0](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-9-320.jpg)
![Now try and check ….
> typos.draft2
# show all the values
[1] 0 3 0 3 1 0 0 1
> max(typos.draft2) # what are worst pages?
[1] 3
> typos.draft2 == 3 # Where are they?
[1] FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE
• Note the use of ‘==‘ for comparing
• But how do we get the indices (pages) having 3 typos?
> which(typos.draft2 == 3)
[1] 2 4
• You only get the index of the elements](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-10-320.jpg)
![Now try and check ….
> n = length(typos.draft2) # how many pages
> pages = 1:n # how we get the page numbers
> pages # pages is simply 1 to number of pages
[1] 1 2 3 4 5 6 7 8
> pages[typos.draft2 == 3] # logical extraction. Very useful
[1] 2 4
The idea is to create a new vector 1, 2, 3, …. keeping track of page
numbers and then slicing off ones for which typos.draft2===3](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-11-320.jpg)
![Now try and check ….
> sum(typos.draft2) # How many typos?
[1] 8
> sum(typos.draft2>0) # How many pages with typos?
[1] 4
> typos.draft1 - typos.draft2 # difference between the two
[1] 2 0 0 0 0 0 0 0
Well Done … Great!!](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-12-320.jpg)
![Now try and check ….
Suppose the daily closing price of your favourite stock for two weeks is
45,43,46,48,51,46,50,47,46,45
How do you keep track of this?
> x = c(45,43,46,48,51,46,50,47,46,45)
> x
[1] 45 43 46 48 51 46 50 47 46 45
> mean(x) # the mean
[1] 46.7
> median(x) # the median
[1] 46
> max(x) # the maximum or largest value
[1] 51
> min(x) # the minimum value
[1] 43
Hope you are enjoying many interesting functions ………](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-13-320.jpg)
![Now try and check ….
Let’s add the next two weeks worth of data to x. This was
48,49,51,50,49,41,40,38,35,40
> x = c(x,48,49,51,50,49) #
> length(x) # how long is x
[1] 15
> x[16] = 41 # add value to
> x[17:20] = c(40,38,35,40)
> x
[1] 45 43 46 48 51 46 50 47
append values to x
now (it was 10)
a specified index which is 16
# add to many specified indices
46 45 48 49 51 50 49 41 40 38 35 40
We did three different things to add to a vector.
• We used the c (combine) operator to combine the previous
value of x with the next week's numbers.
• We then assigned directly to the 16th index.
• Finally, we assigned to a slice of indices.](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-14-320.jpg)
![Now try and check ….
Suppose we want a 5-day moving average
> day<-5
> mean(x[day:(day+4)])
[1] 48
> day:(day+4)
[1] 5 6 7 8 9
How do you get running maximum or minimum till date?
> cummax(x) # running
[1] 45 45 46 48 51 51
> cummin(x) # running
[1] 45 43 43 43 43 43
maximum
51 51 51 51 51 51 51 51 51 51 51 51 51 51
minimum
43 43 43 43 43 43 43 43 43 41 40 38 35 35](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-15-320.jpg)



![Categorical Data : Factor
Categorical data is often used to classify data into various levels
or factors. To make a factor is easy with the command factor or
as.factor.
> x #Print the values in x
[1] "Yes" "No" "No" "Yes" "Yes"
> factor(x) # print out value in factor(x)
[1] Yes No No Yes Yes
Levels: No Yes
Note that levels have been printed.](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-19-320.jpg)




![Making numeric data categorical
Suppose, CEO yearly compensations are sampled and the
following are found (in millions).
12 0.4 5 2 50 8 3 1 4 0.25
And we want to break that data into the intervals [0; 1]; (1; 5];
(5; 50] and name the same.
> sals = c(12, .4, 5, 2, 50, 8, 3, 1, 4, .25) # enter data
> cats = cut(sals,breaks=c(0,1,5,max(sals))) # specify the breaks
> cats # view the values
[1] (5,50] (0,1] (1,5] (1,5] (5,50] (5,50] (1,5] (0,1] (1,5]
Levels: (0,1] (1,5] (5,50]
> levels(cats) = c("poor","rich","rolling in it") # change labels
> table(cats)
cats
poor
rich rolling in it
3
4
3
(0,1]](https://image.slidesharecdn.com/rparti-131119003530-phpapp02/85/R-part-I-29-320.jpg)





















![[1062BPY12001] Data analysis with R / week 3](https://cdn.slidesharecdn.com/ss_thumbnails/dataanalyzer02-180314152330-thumbnail.jpg?width=640&height=640&fit=bounds)






![[1062BPY12001] Data analysis with R / week 2](https://cdn.slidesharecdn.com/ss_thumbnails/dataanalyzer01-180307063046-thumbnail.jpg?width=640&height=640&fit=bounds)

























































