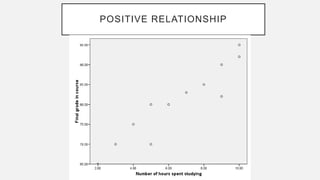
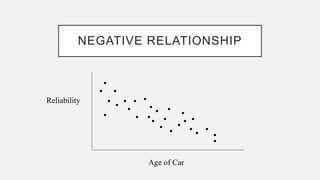
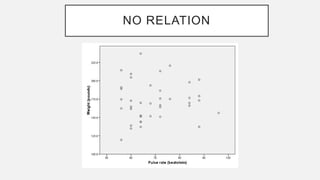
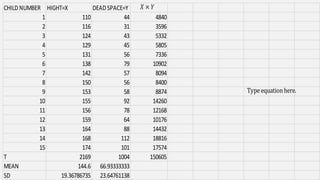
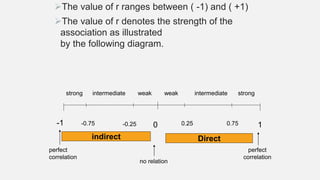
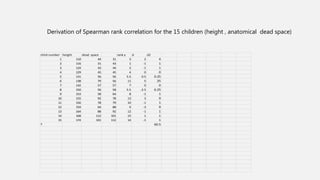
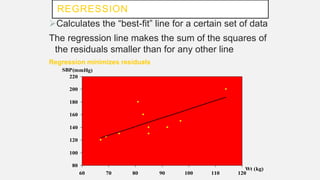
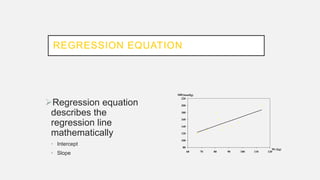
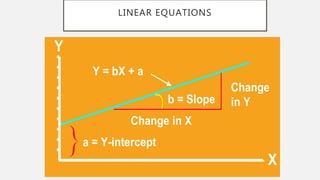
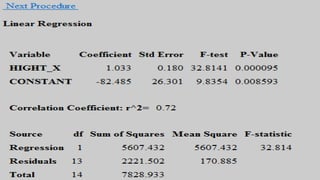
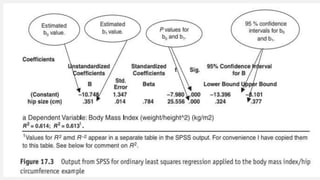
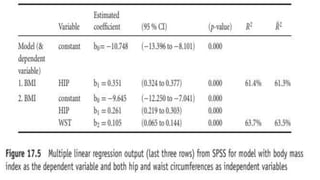
The document discusses correlation and regression analysis in statistical methods, detailing the relationships between categorical and continuous variables. It explains the correlation coefficient, scatter diagrams, and the calculation of regression equations, emphasizing that correlation does not imply causation. The author also covers Spearman rank correlation and multiple regression analysis, outlining their differences and uses in modeling relationships among continuous variables.