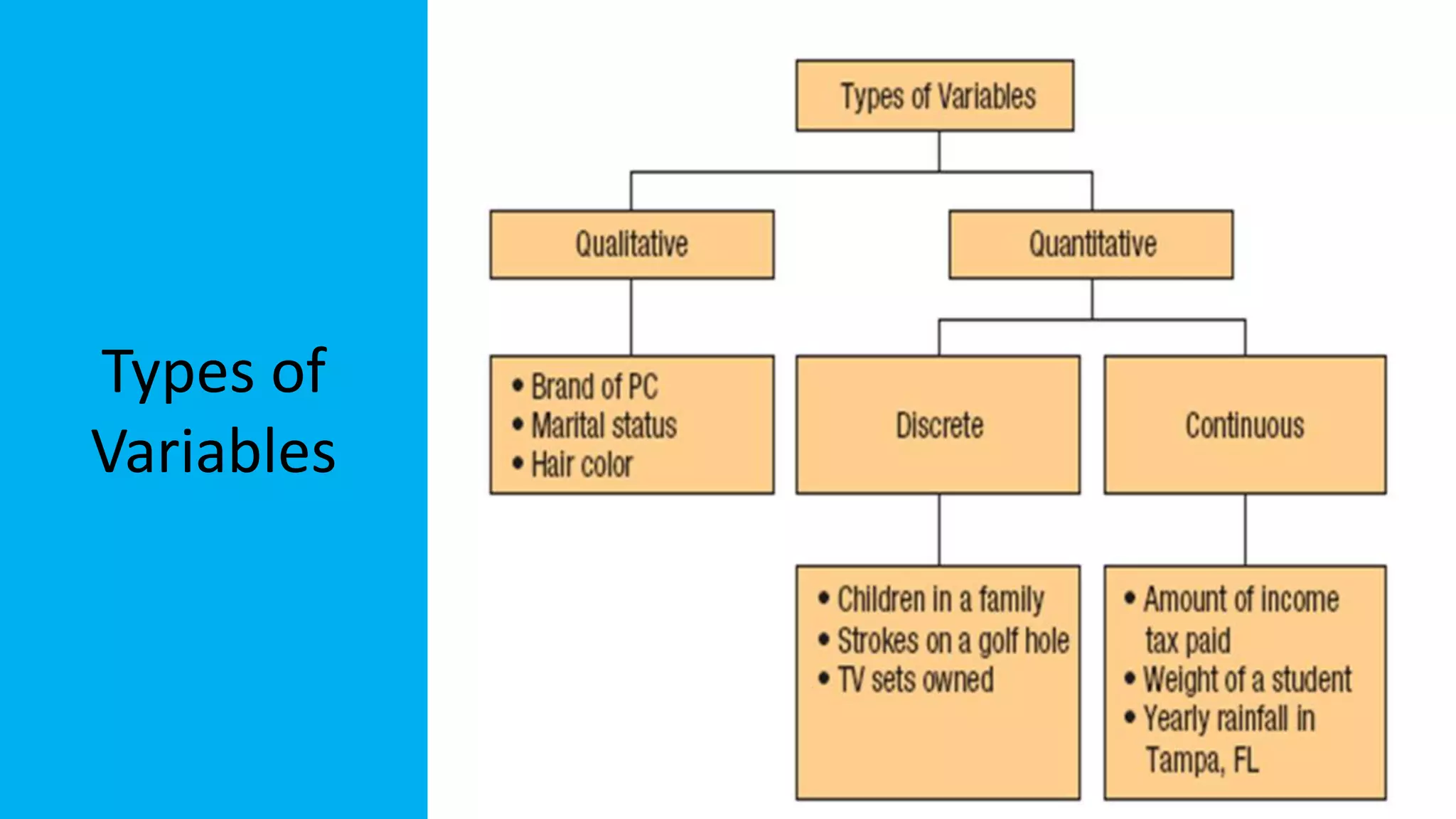
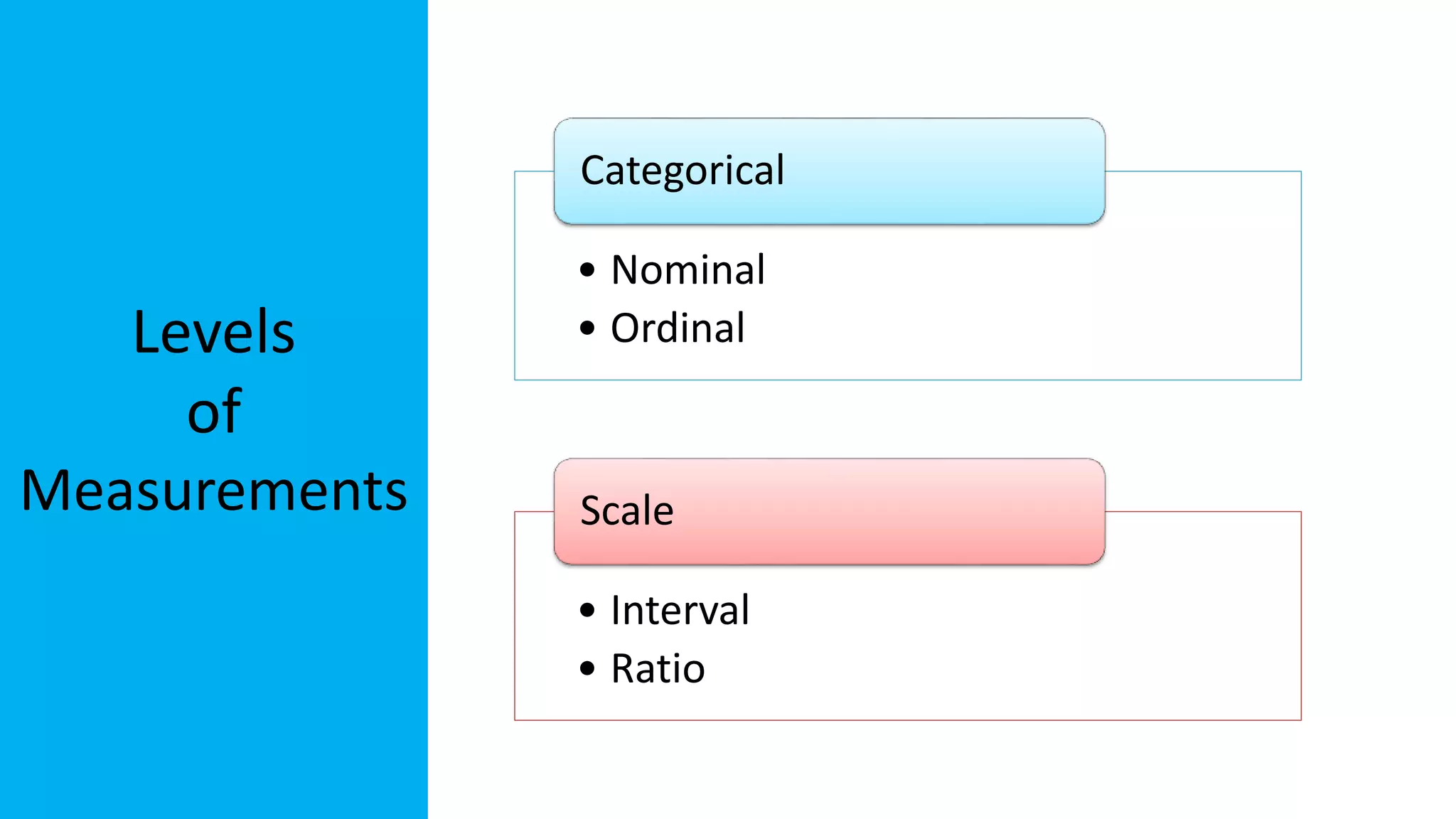
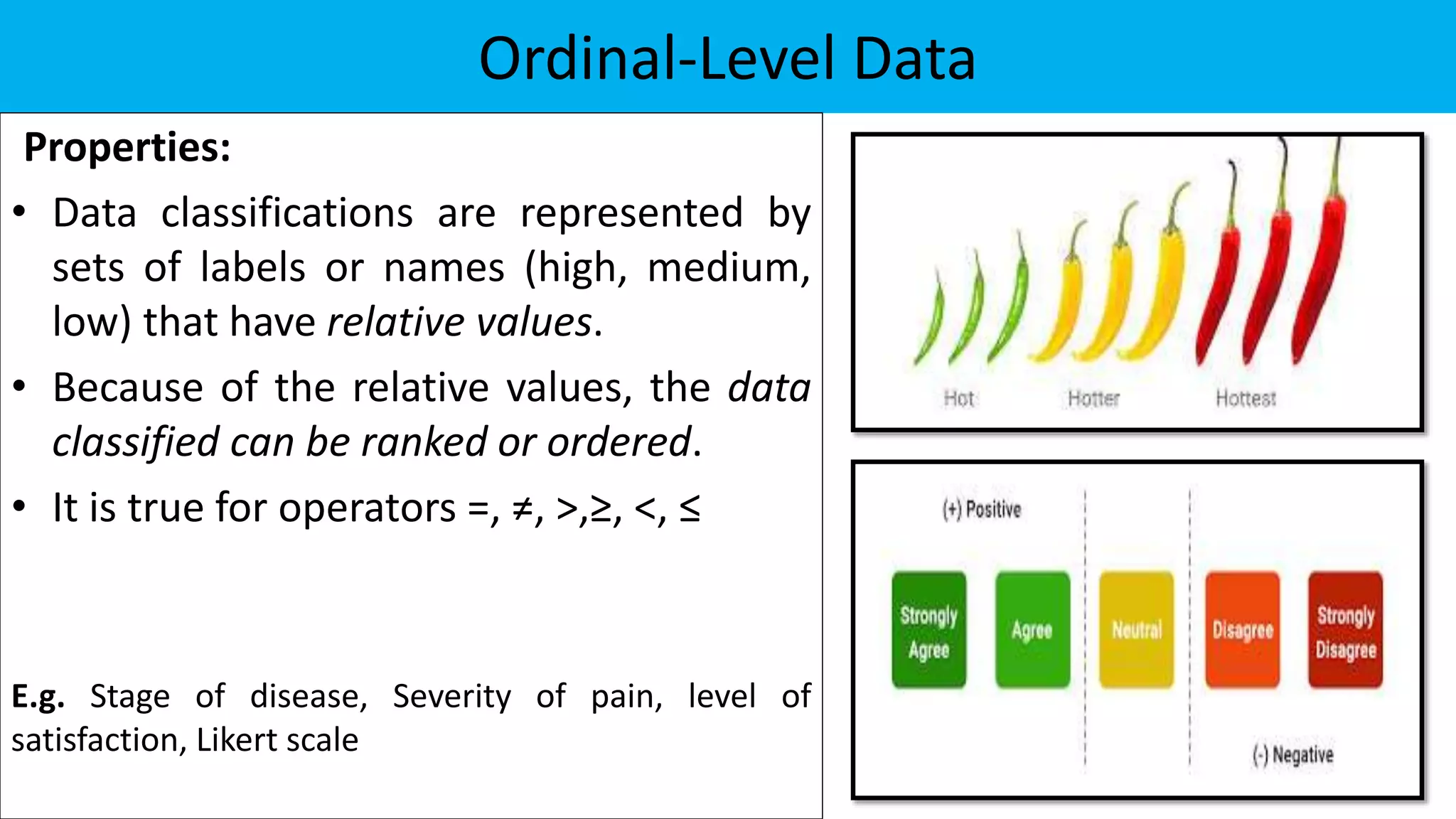
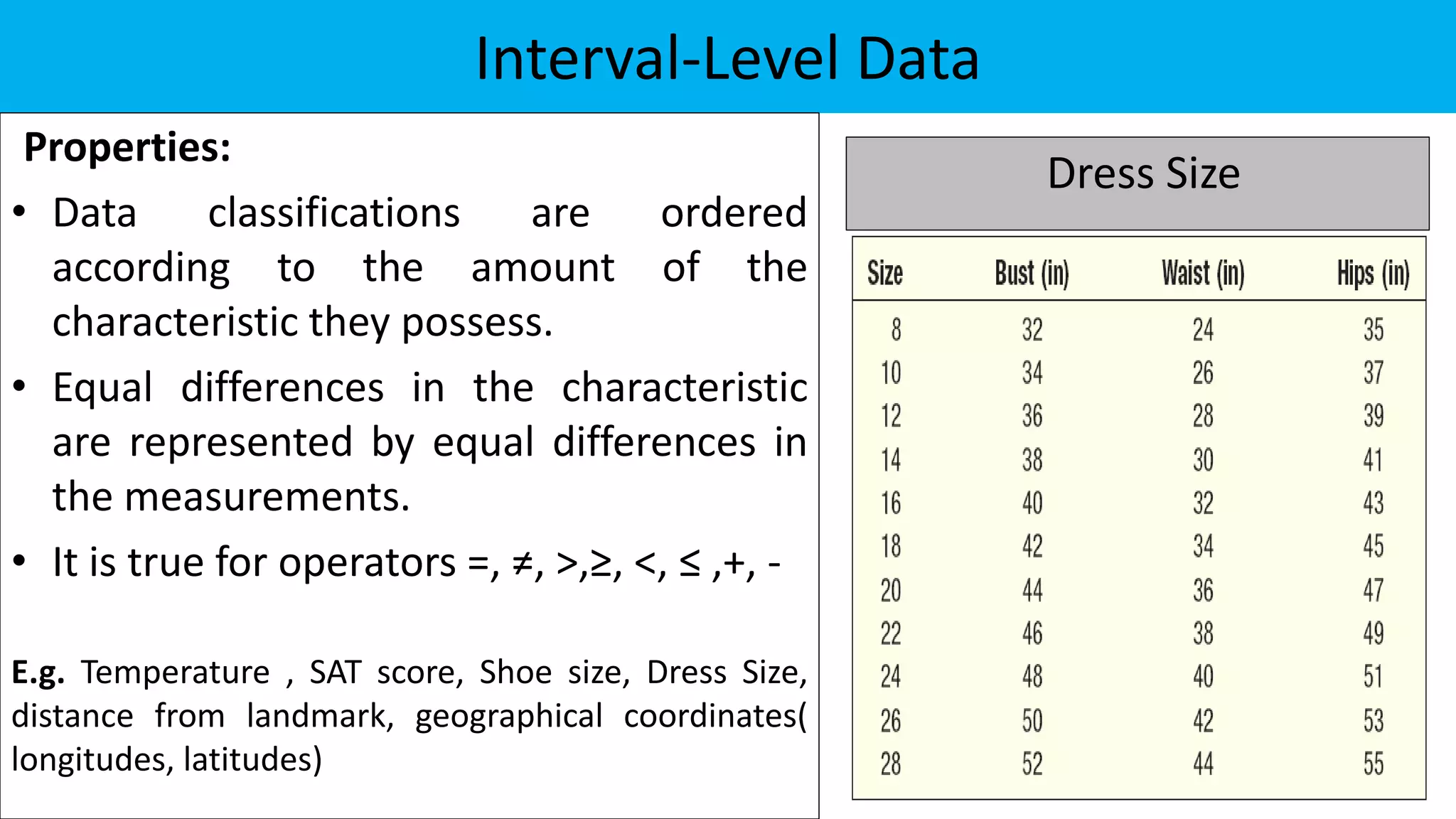
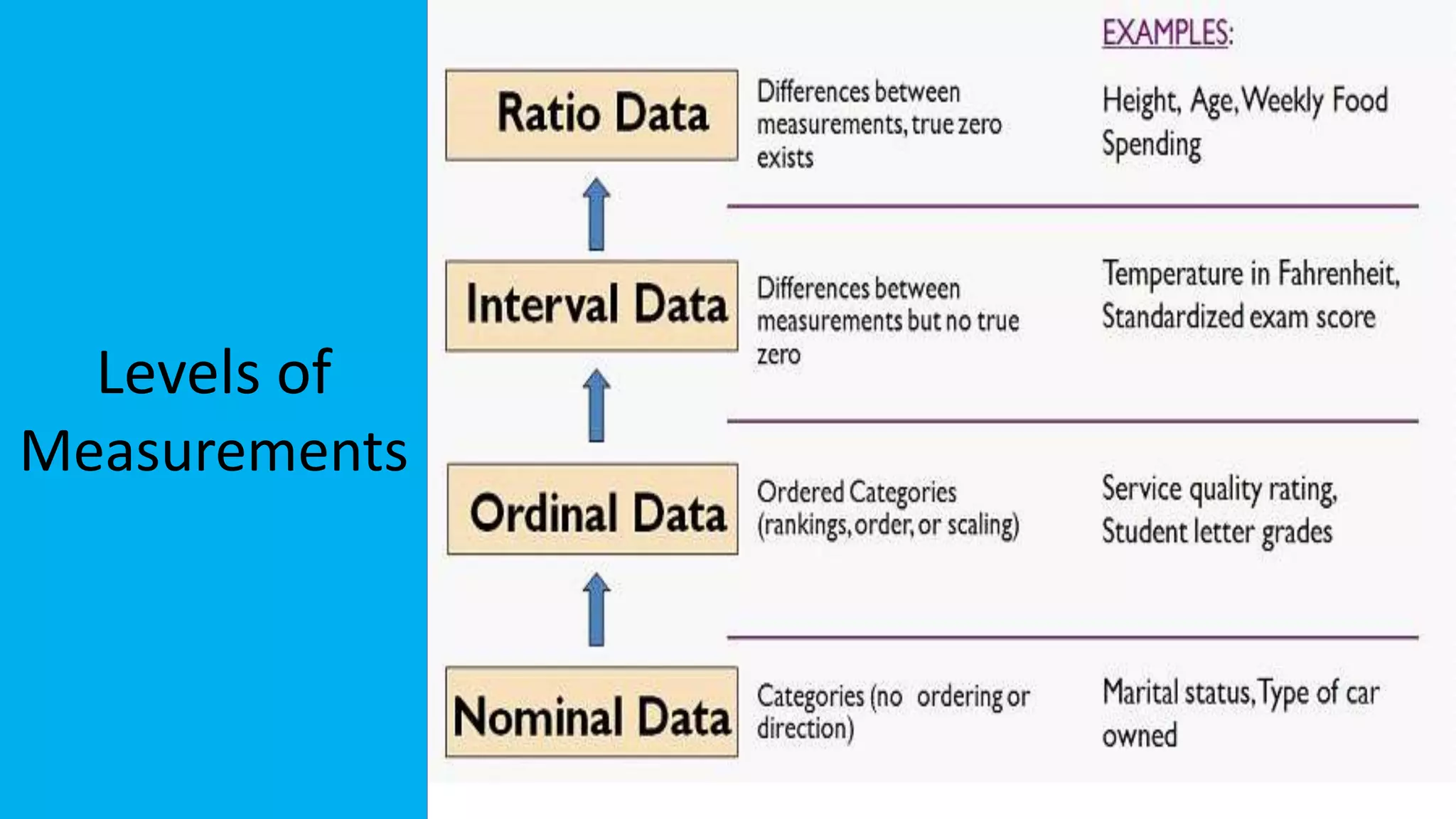
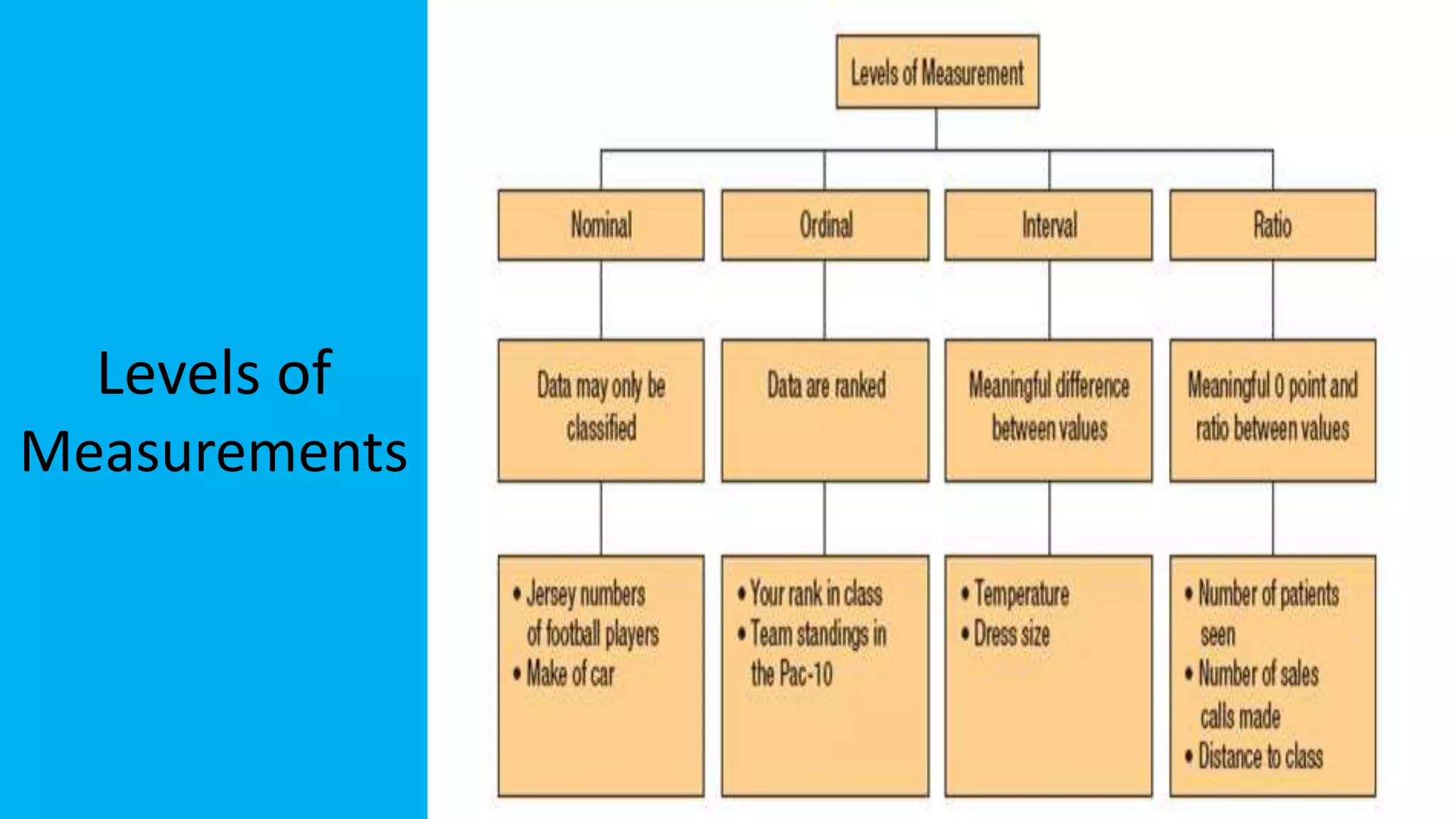
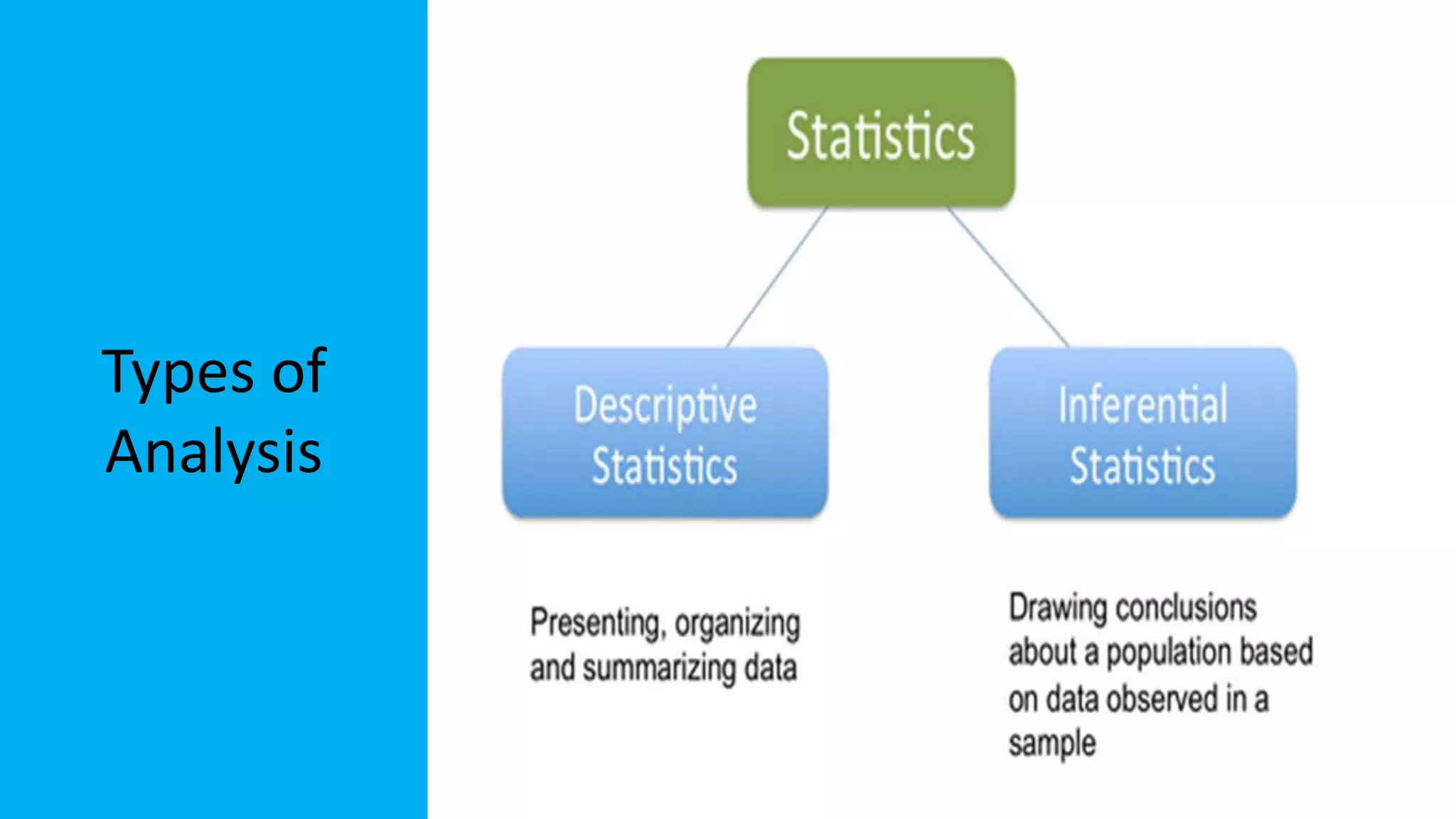
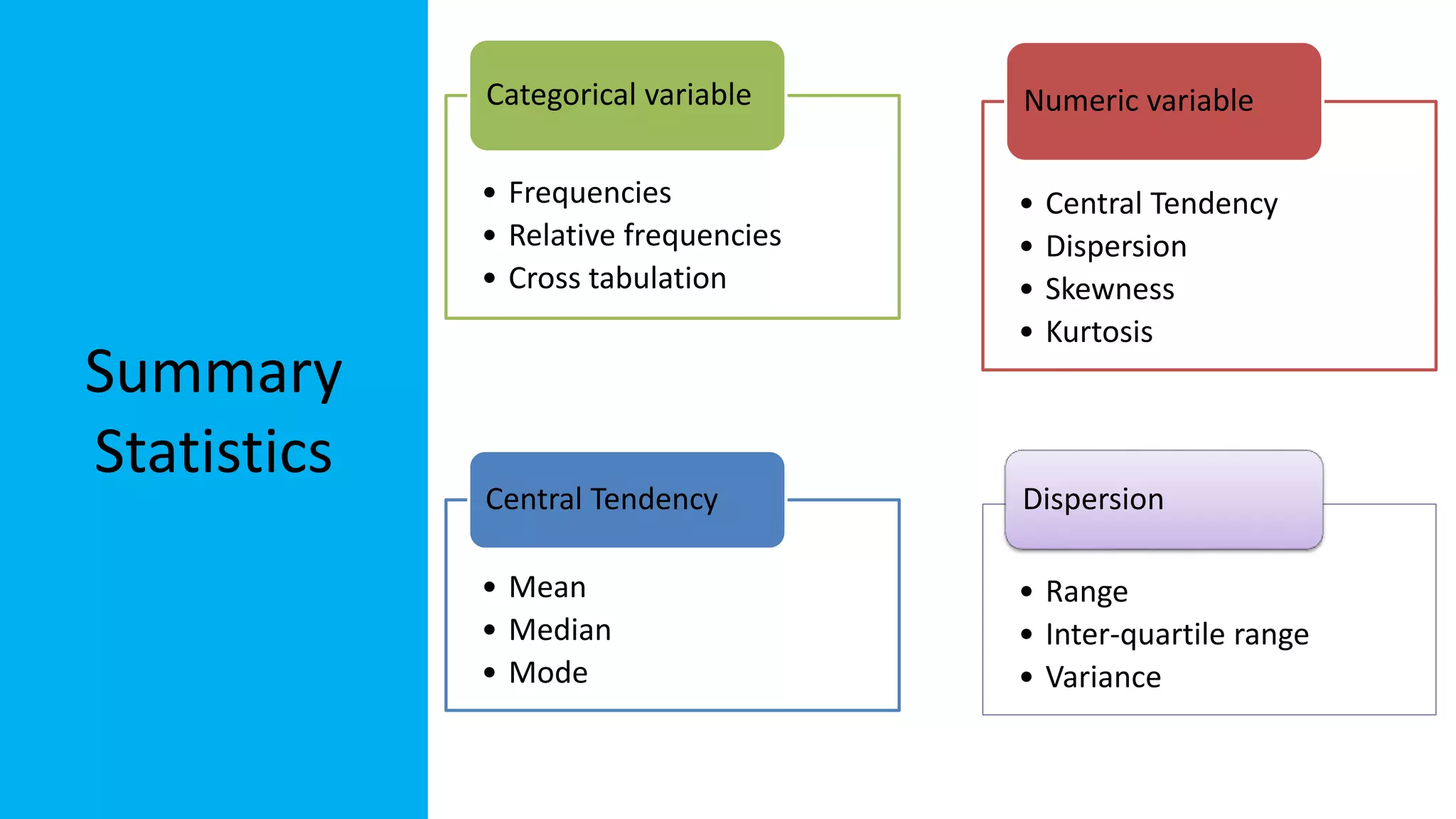
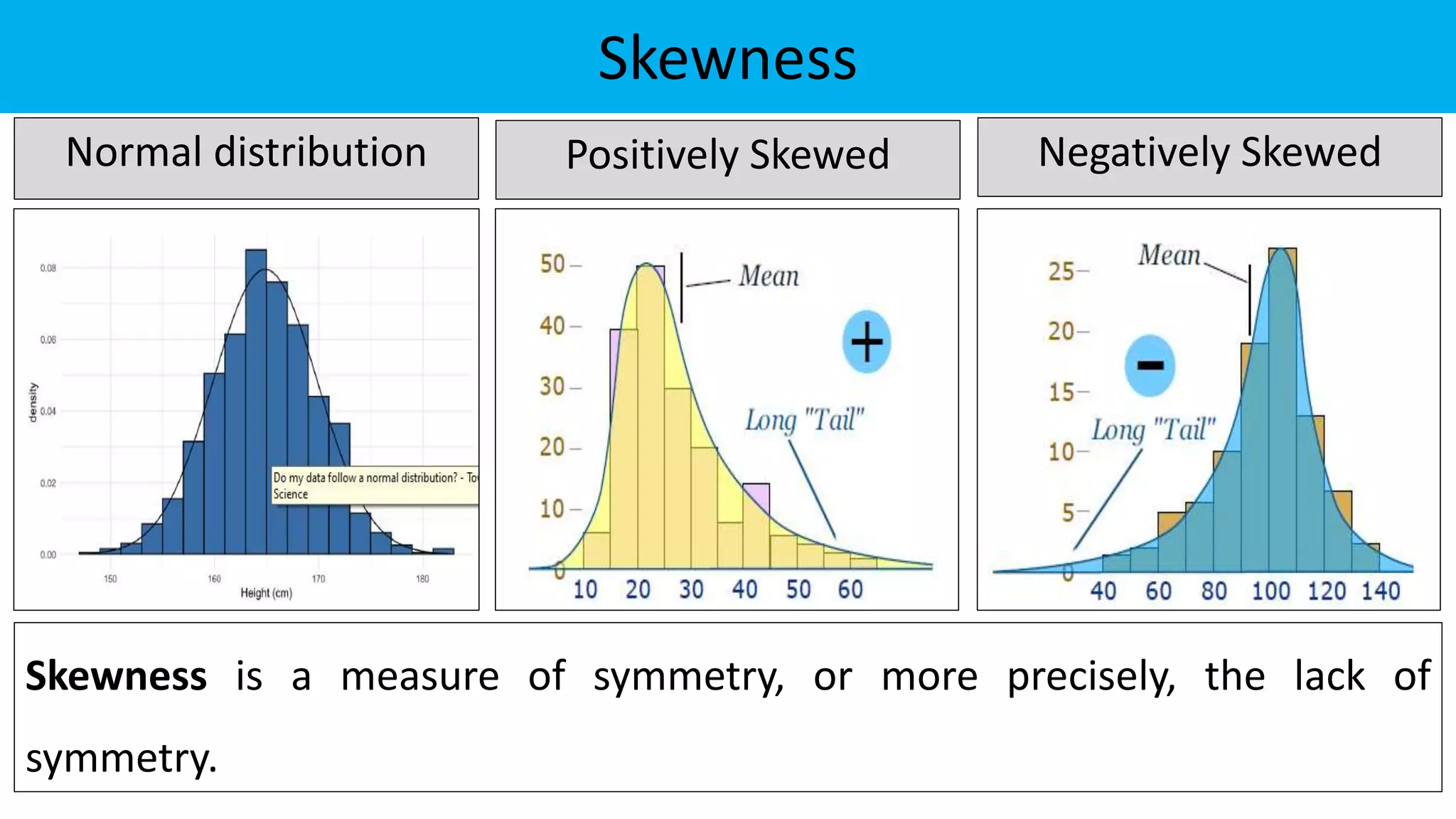
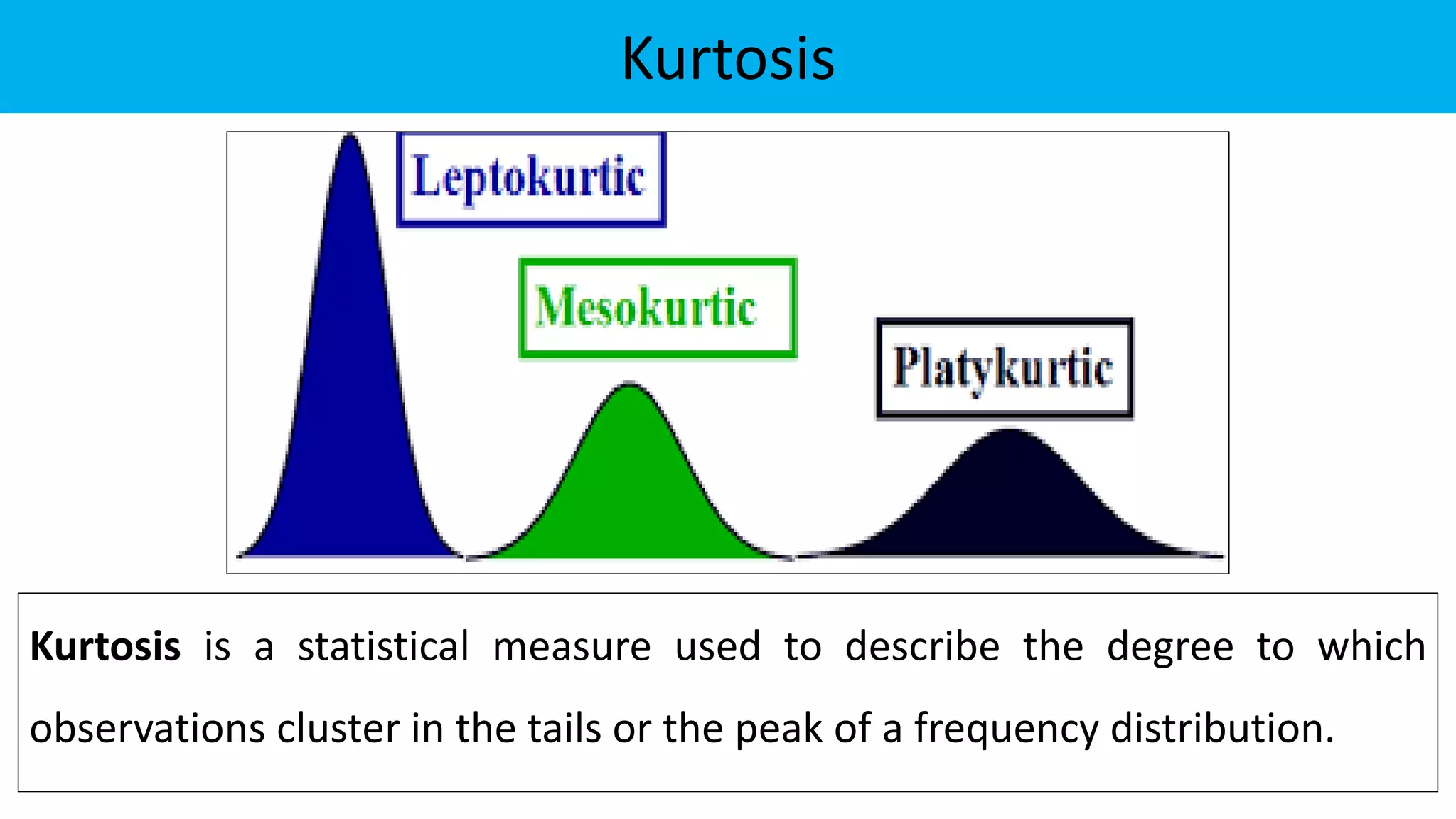
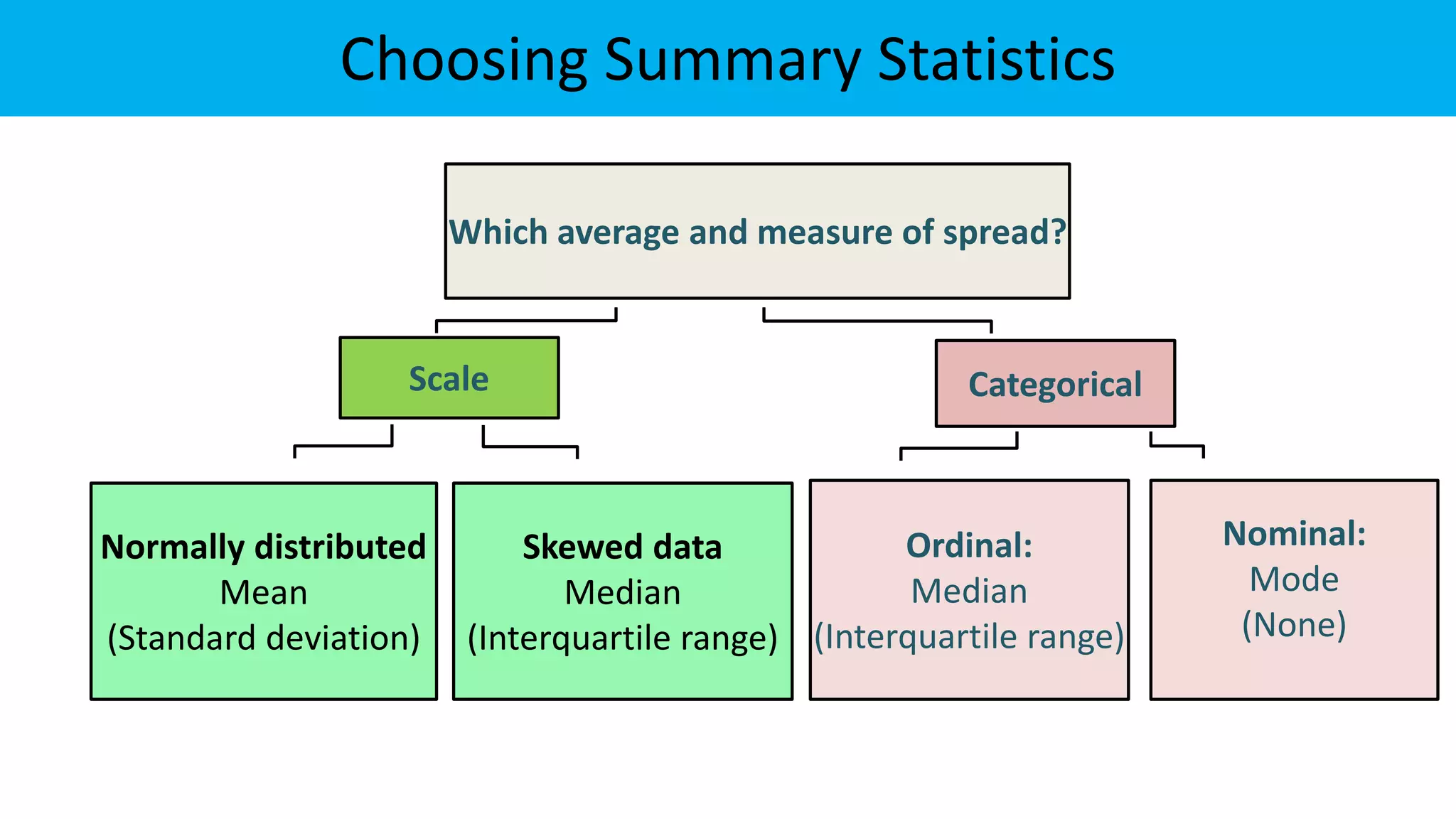
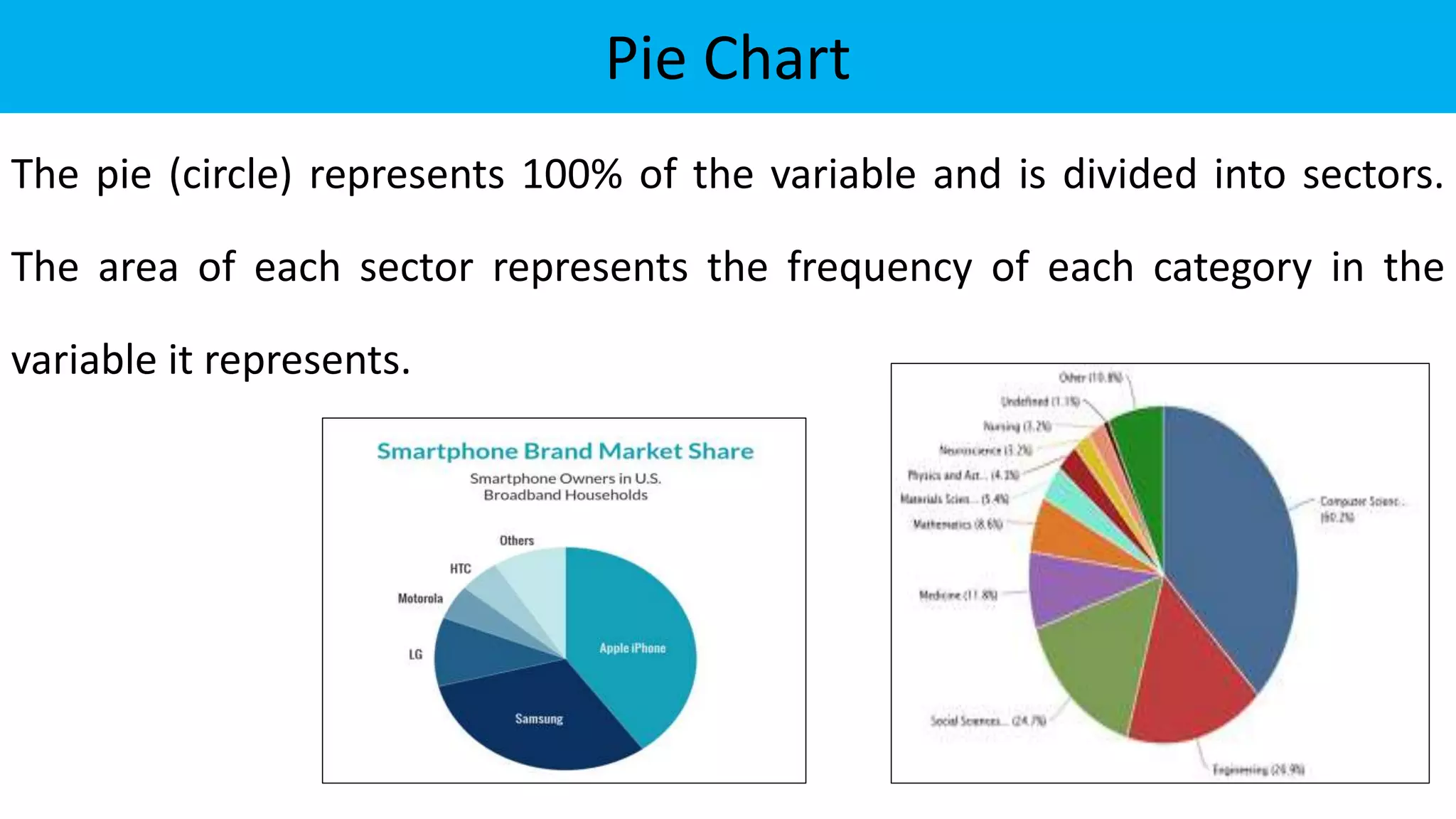
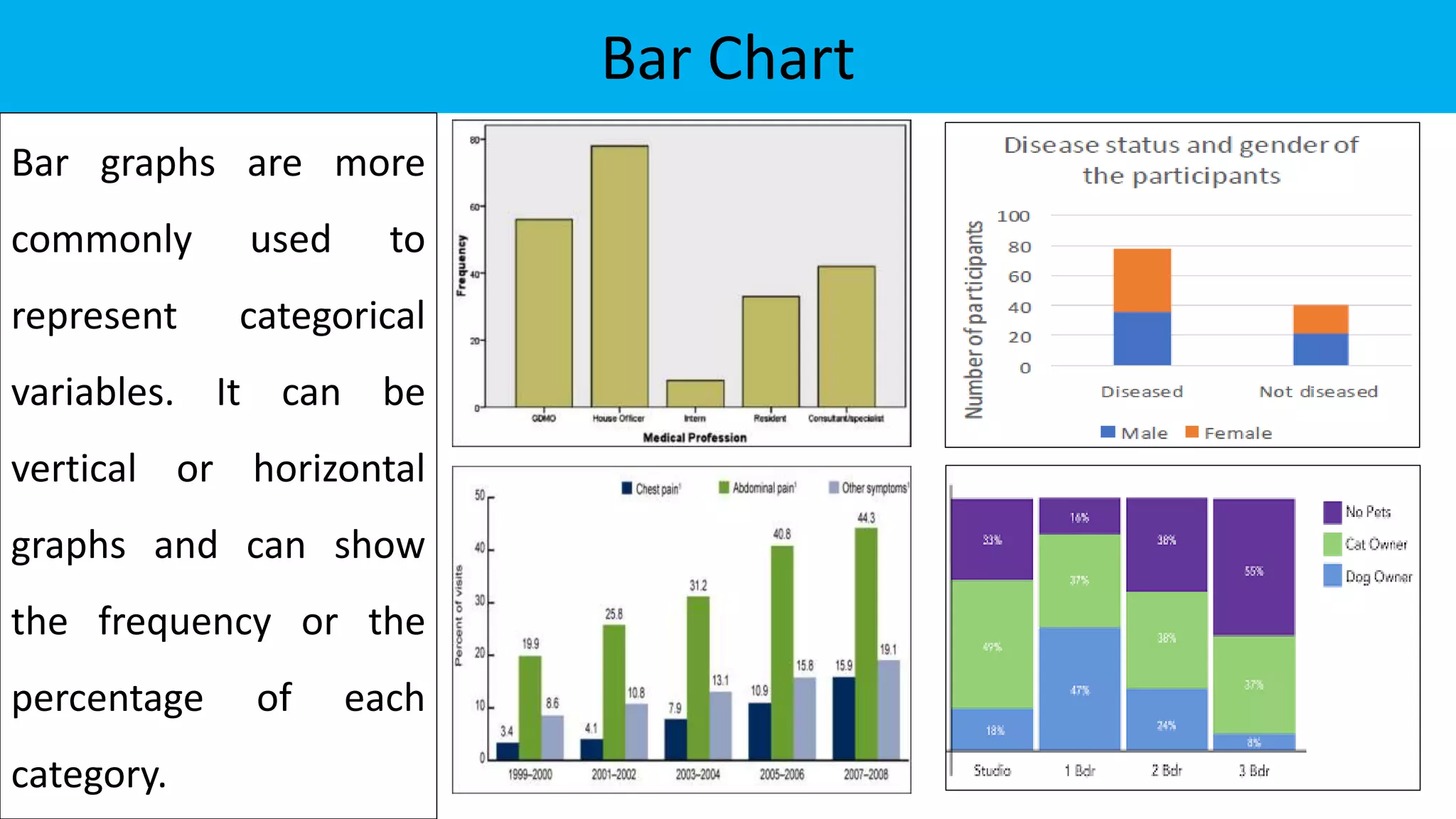
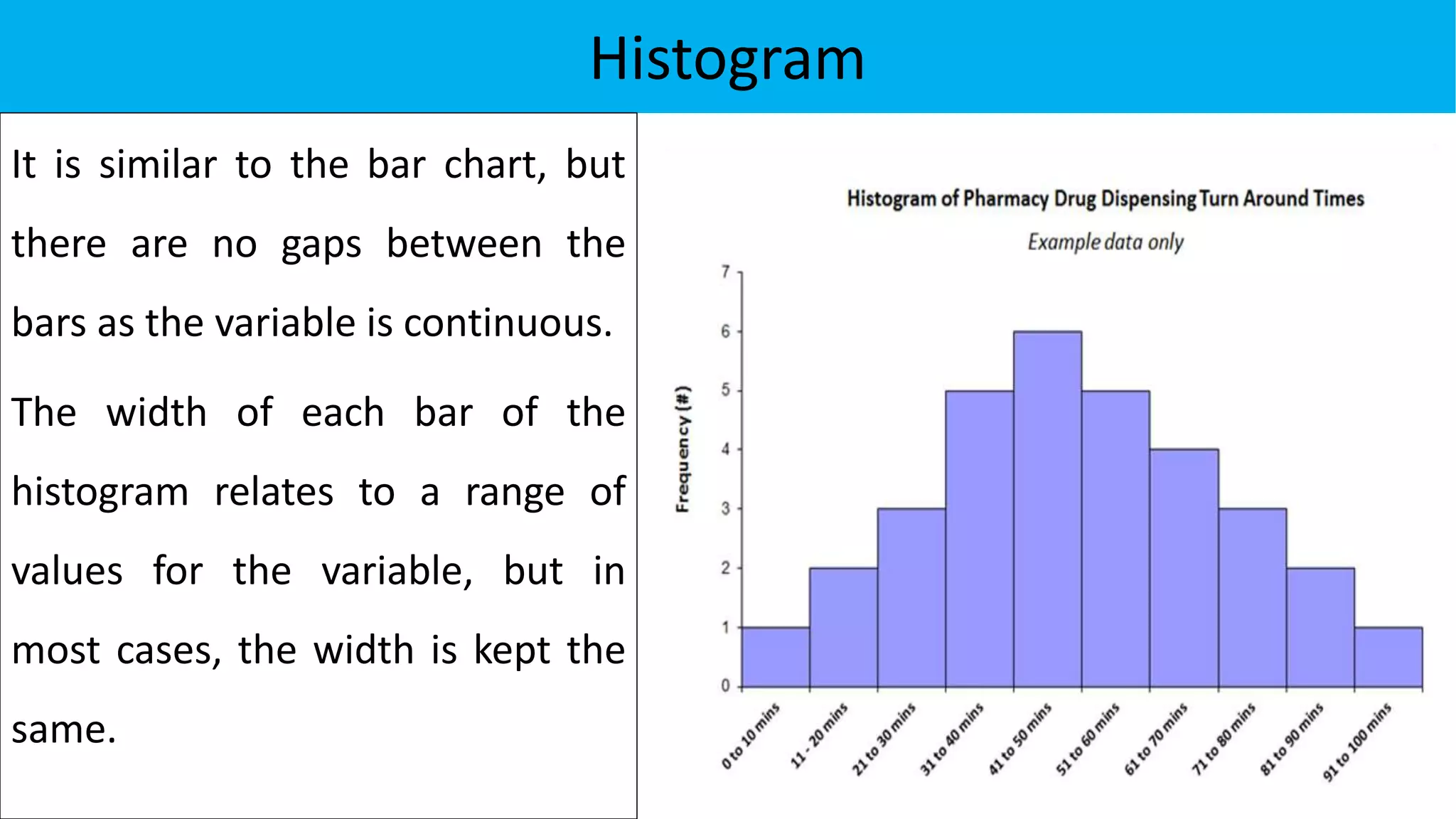
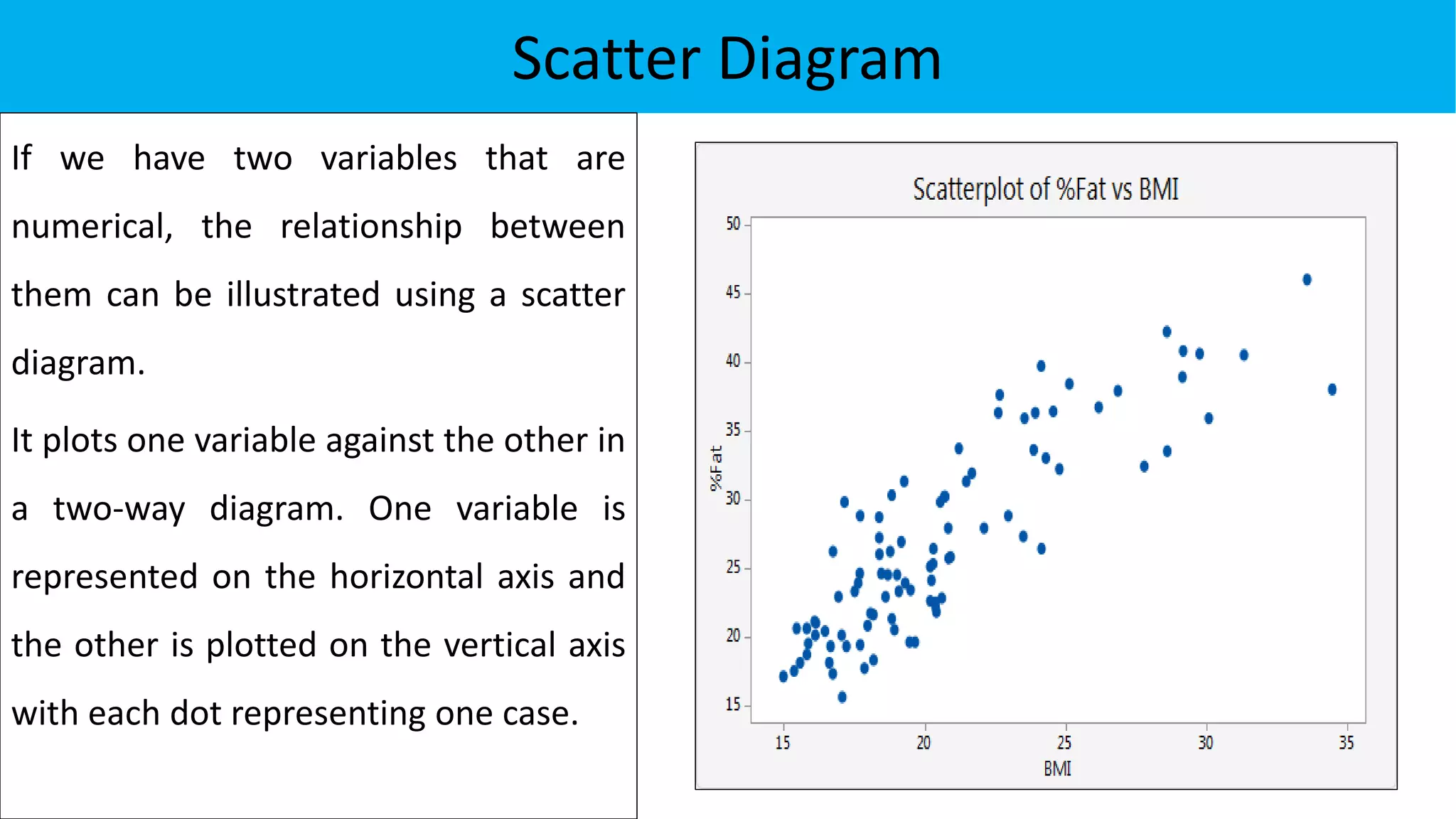
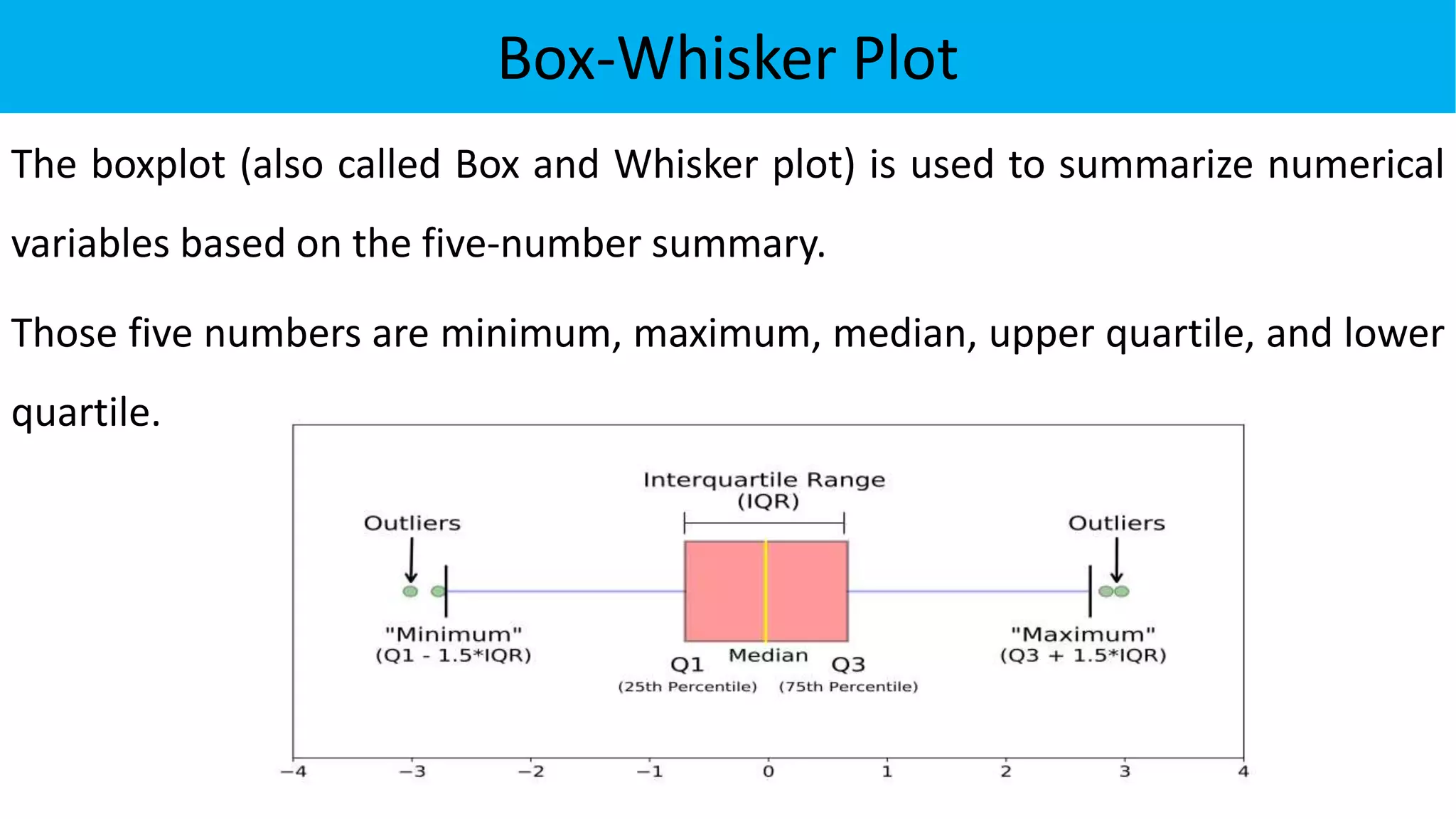
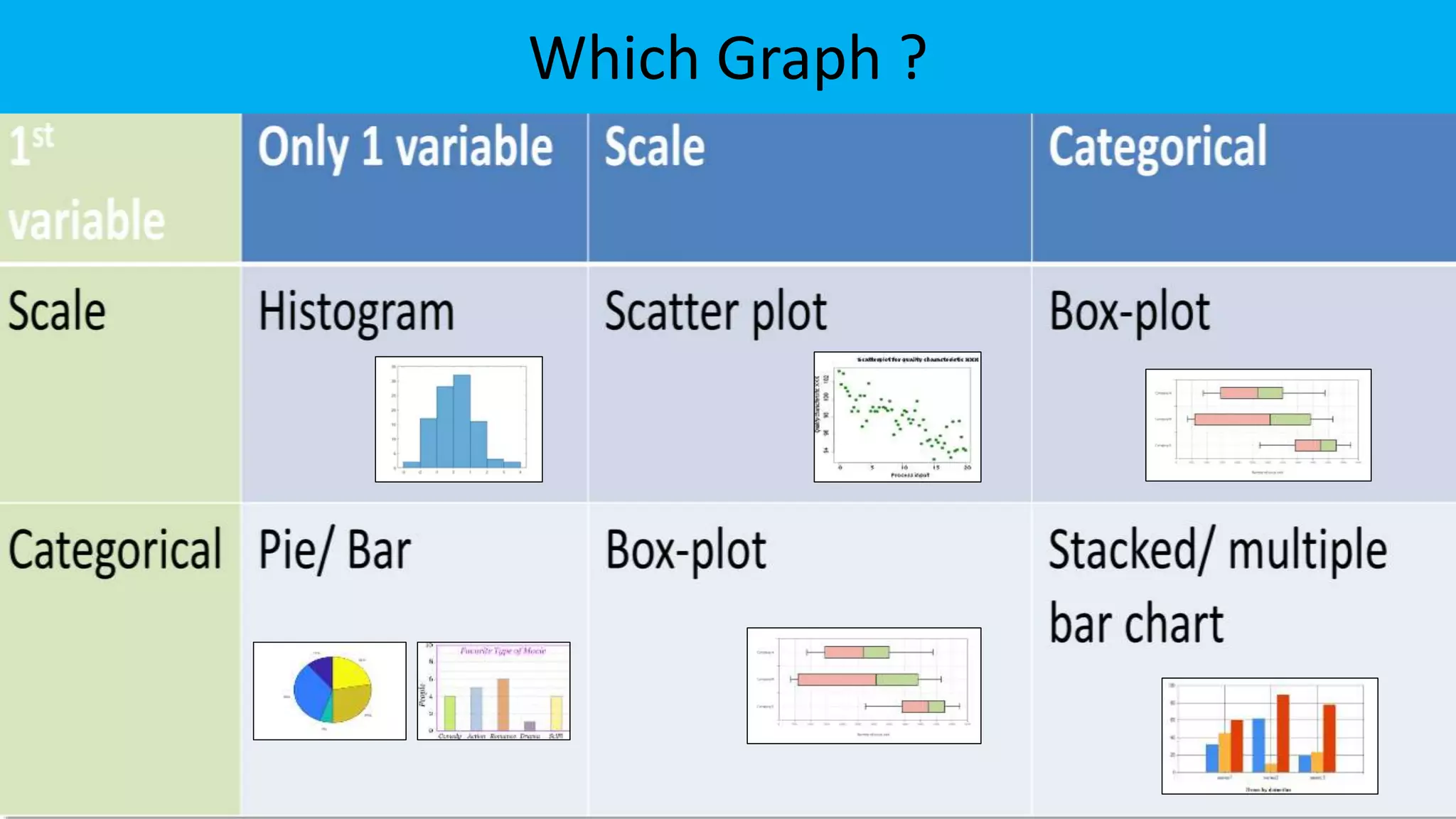
The document discusses exploratory data analysis in the context of biotechnology and pharmaceutical sciences, detailing types of data (qualitative and quantitative) and levels of measurement (nominal, ordinal, interval, ratio). It explains the importance of understanding these concepts for accurate data presentation and selection of appropriate statistical tests, as well as covering descriptive and inferential statistics. Additionally, it highlights various data visualization methods, such as pie charts, bar charts, and scatter diagrams, for effectively conveying data insights.














































































![[DSC Europe 25] Jean Del Rosario - How to Reduce GenAI Costs up to 73.45%.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zjehcwqsiwjisav1znml-5-251217093201-eae4440a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Djordjevic - AI can help Agriculture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/c0huq0ztiubmgccem2hc-marko-djordjevic-ai-can-help-agriculture-251218125253-7606f036-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mathias Halkjær Petersen - The AI workforce revolution.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/3xviexv7q5gojhdsyvat-the-ai-workforce-revolution-251218084820-f3c286ed-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dobrica Cosic - From Electrons to Innovation: How Granular Da...](https://cdn.slidesharecdn.com/ss_thumbnails/h4qk69zereaumbceubgr-dobrica-cosic-from-electrons-to-innovation-how-granular-data-and-analytics-are--251218085301-b982fb14-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)


