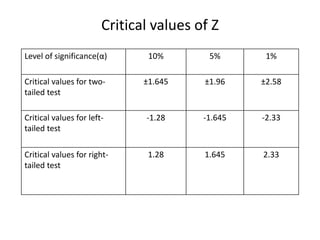
This document provides an overview of statistical inference. It discusses descriptive statistics, which summarize data, and inferential statistics, which are used to generalize from samples to populations. Key concepts covered include estimation, hypothesis testing, parameters, statistics, confidence intervals, significance levels, types of errors. Examples are given of how to calculate confidence intervals for means and proportions and how to perform hypothesis tests using z-tests and t-tests. Steps for conducting hypothesis tests are outlined.