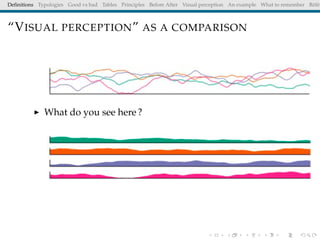
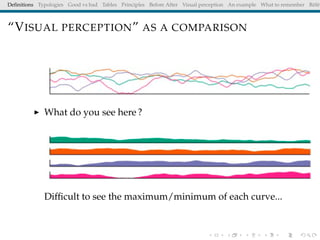
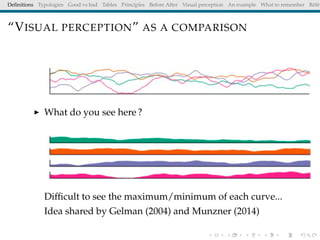
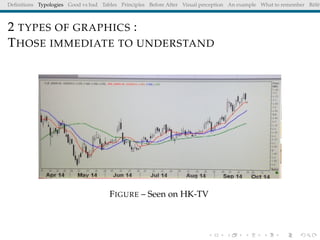
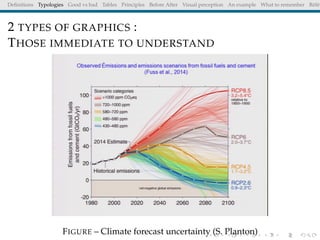
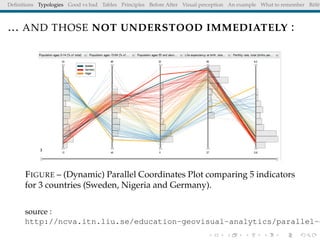
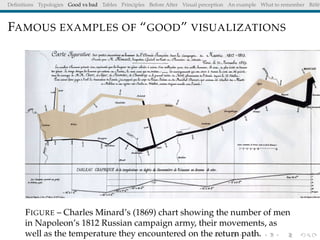
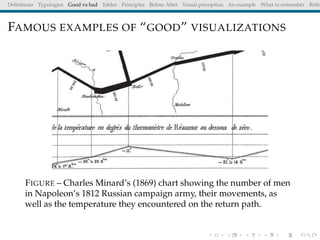
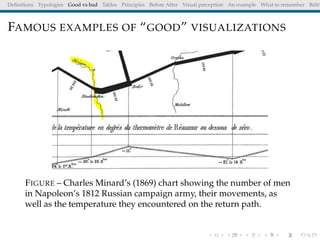
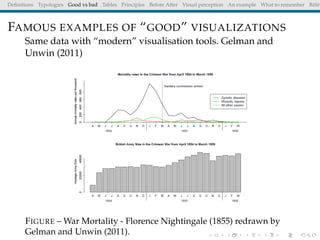
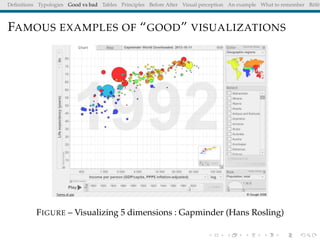
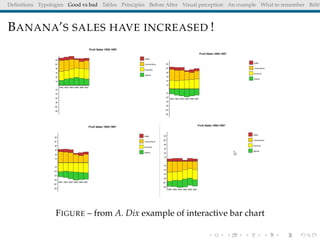
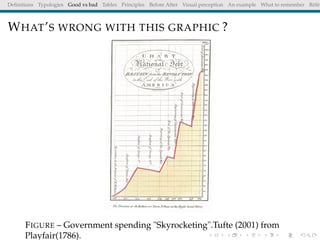
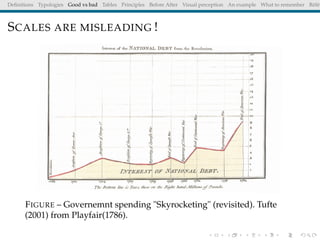
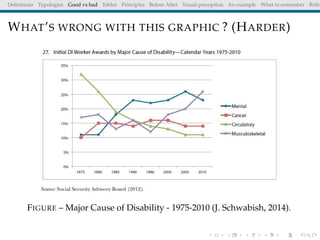
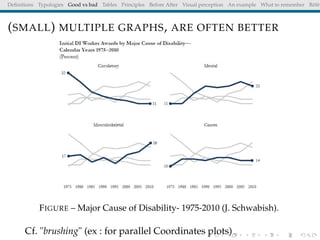
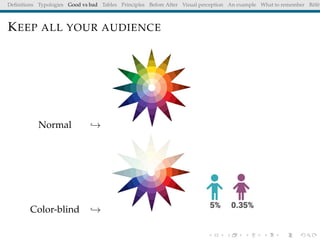
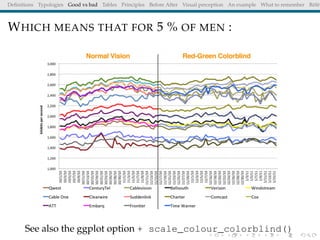
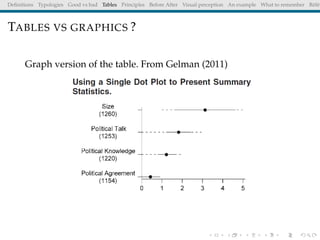
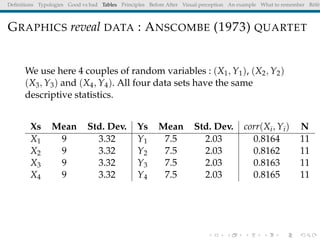
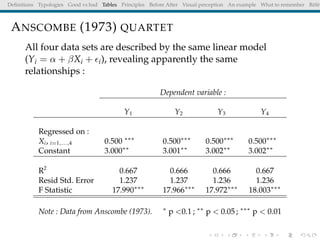
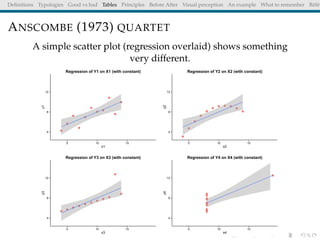
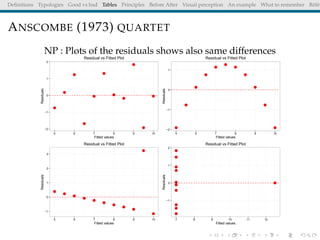
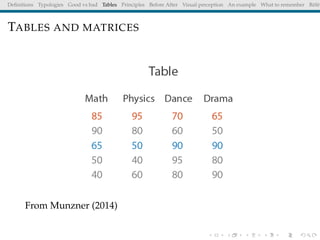
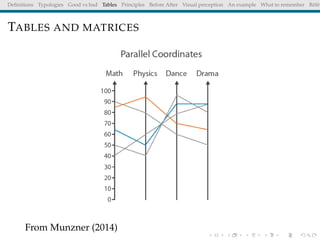
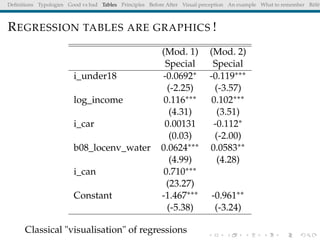
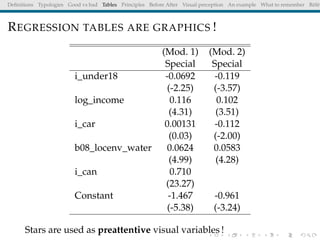
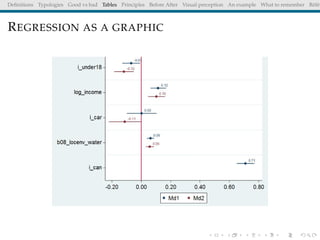
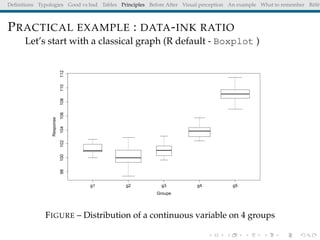
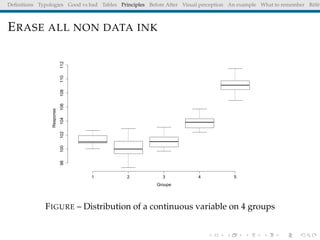
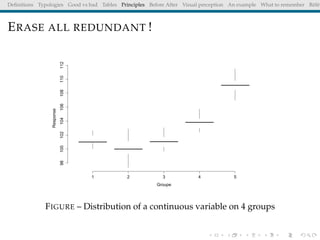
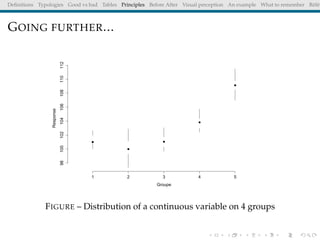
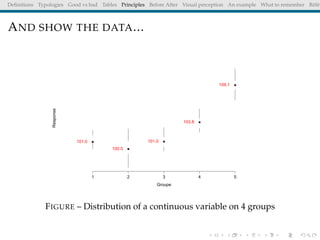
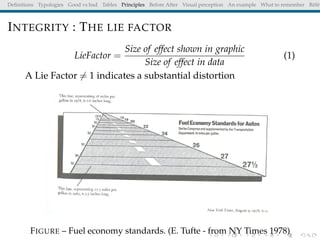
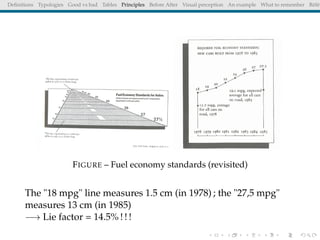
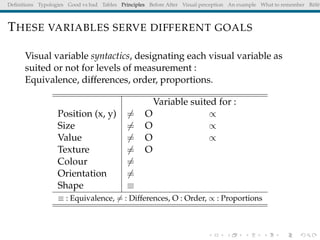
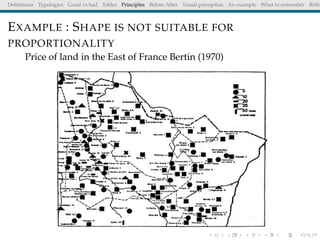
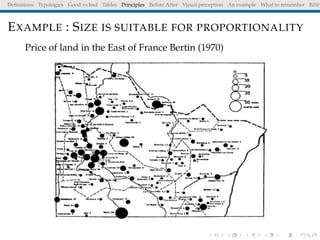
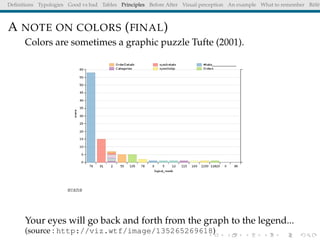
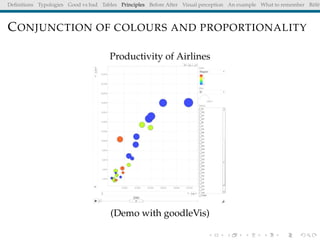
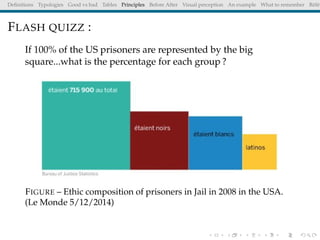
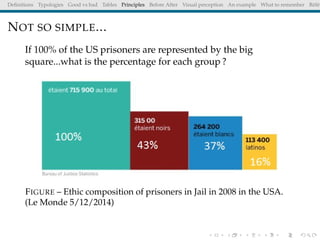
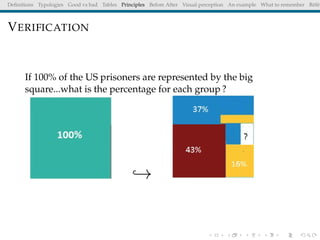
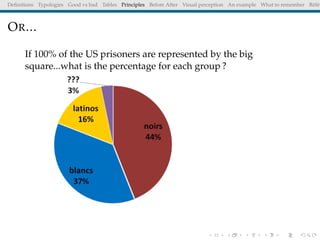
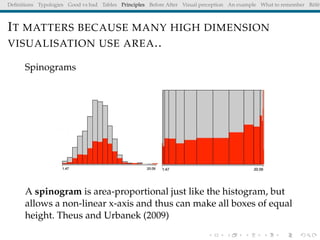
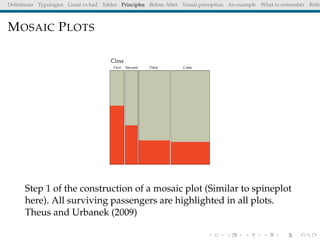
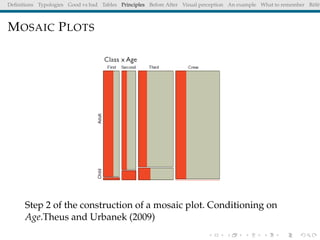
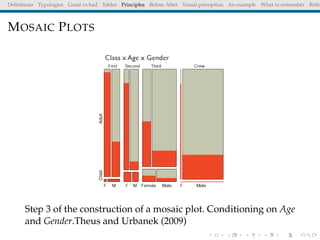
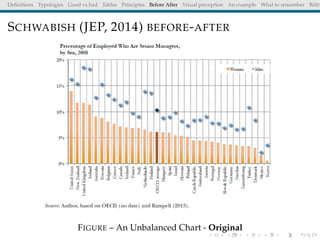
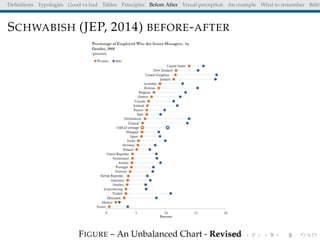
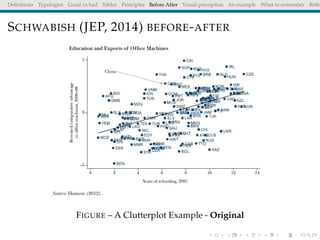
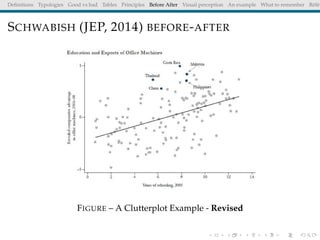
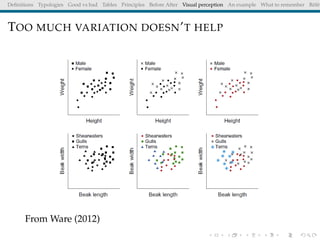
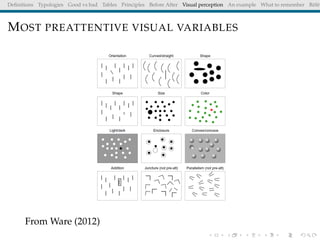
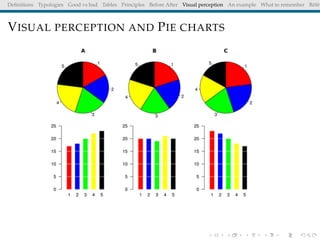
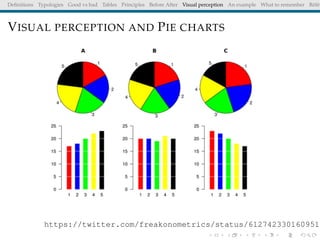
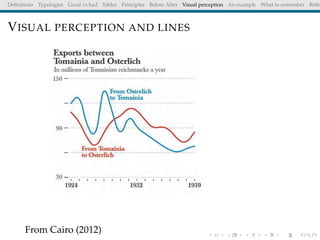
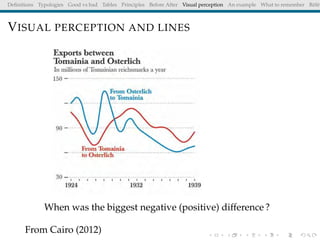
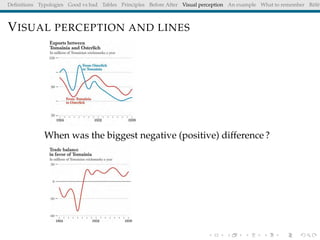
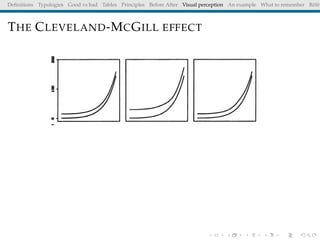
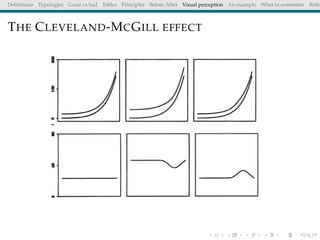
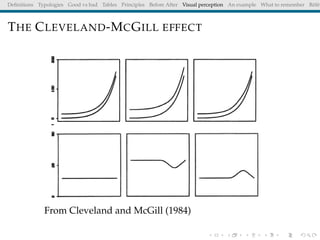
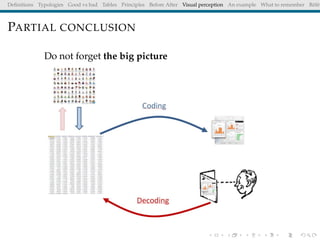
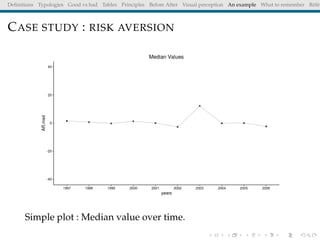
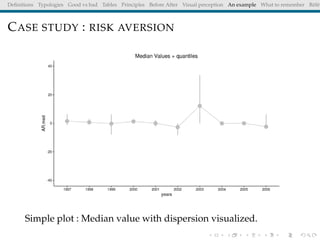
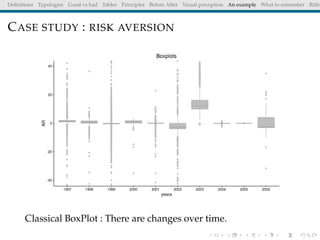
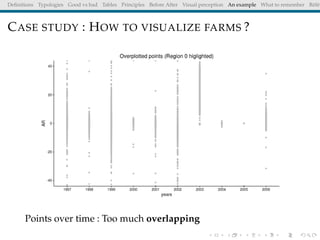
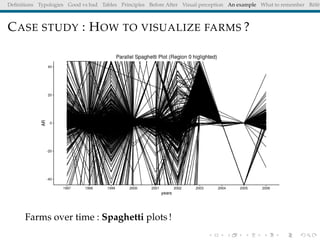
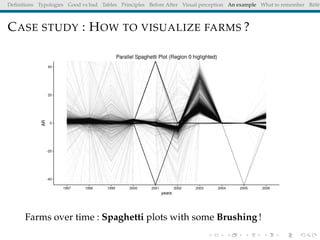
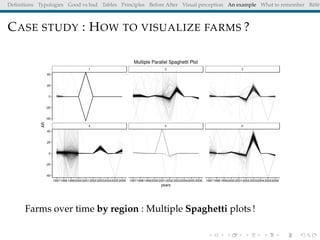
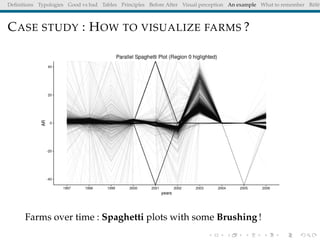
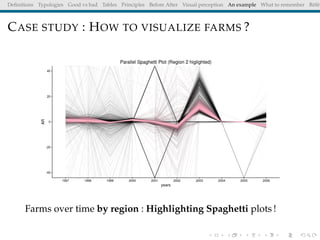
The document discusses principles and definitions of data visualization, emphasizing its role as a representation and function of data that aids in statistical analysis and communication. It outlines characteristics of effective visuals, compares 'good' vs. 'bad' graphics, and highlights the importance of graphic clarity and context. Key definitions from renowned authors such as Tukey, Cleveland, and Bertin underscore the value of visuals in revealing data insights.