Downloaded 404 times






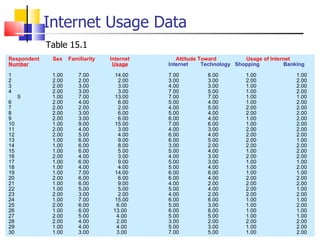

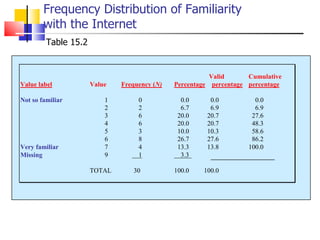
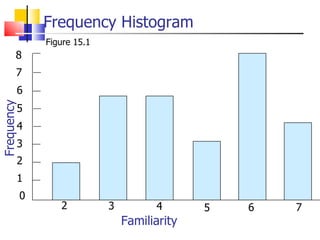
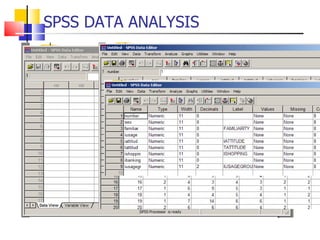





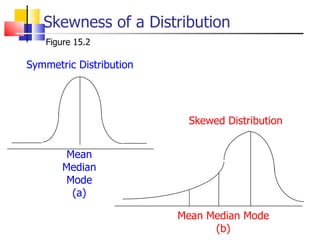
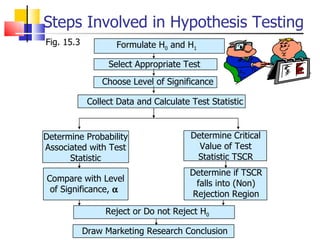






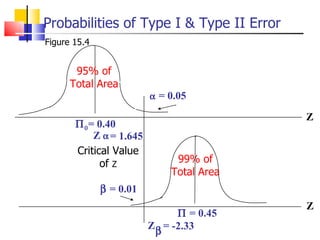
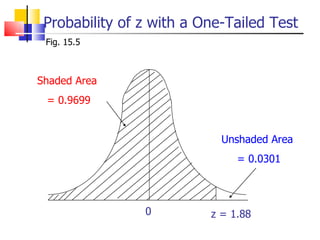






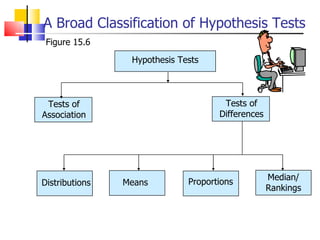

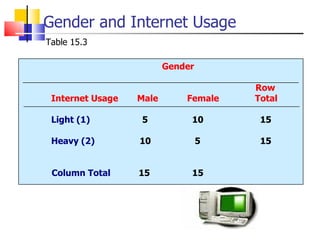


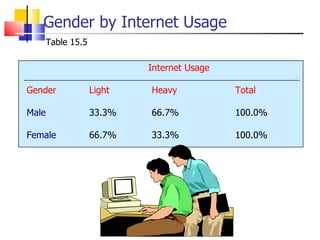
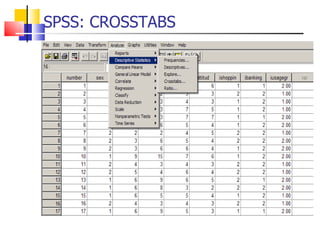
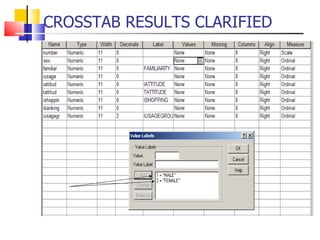
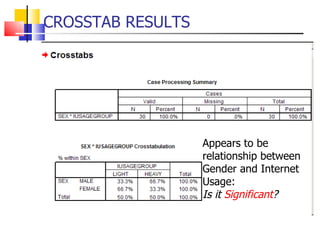
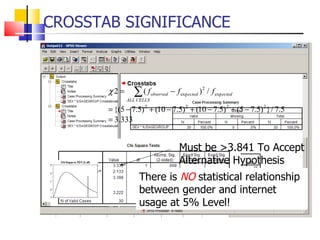
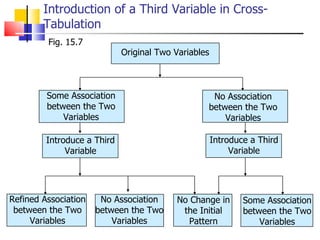







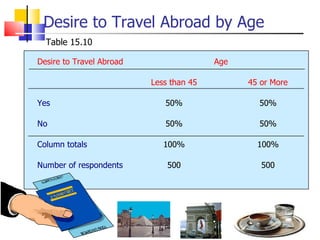
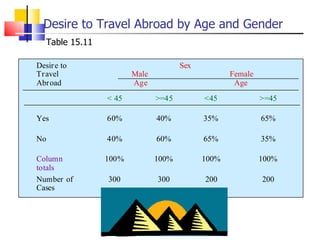

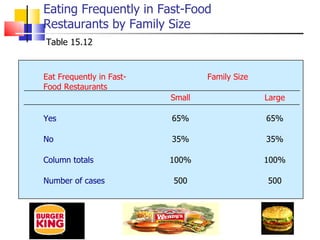
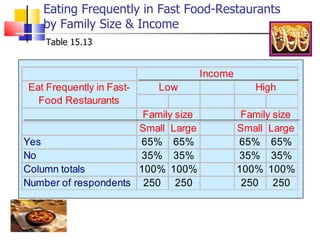

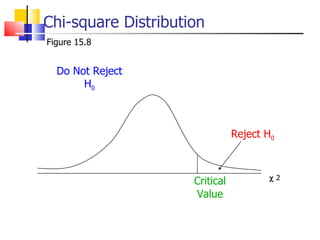


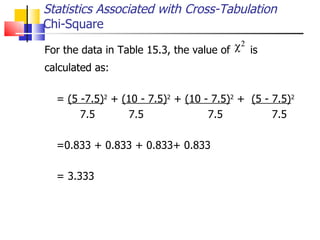













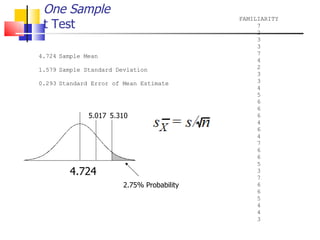
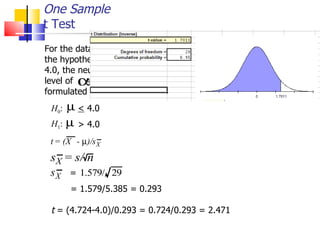









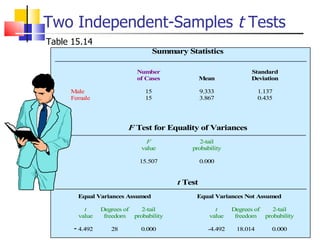






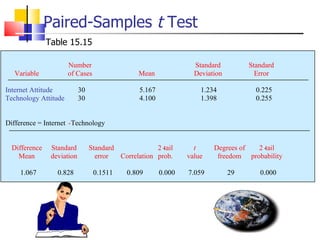



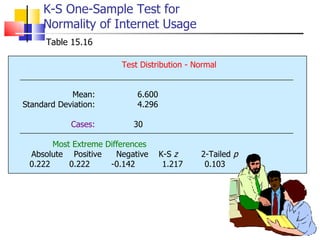

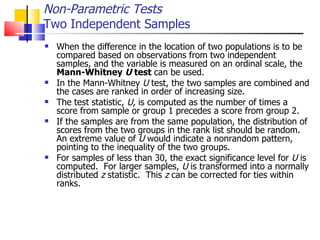




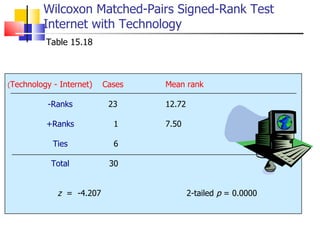

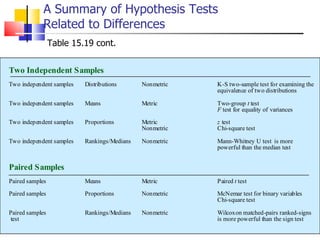





The document outlines the steps for conducting frequency distribution, cross-tabulation, and hypothesis testing analyses. It discusses measuring location, variability, and shape in frequency distributions. Cross-tabulation involves analyzing two or more variables simultaneously through tables. Hypothesis testing follows general steps including formulating hypotheses, selecting a test, determining significance levels, collecting data, and making conclusions.















































![Working and functions_of_rbi[1]](https://cdn.slidesharecdn.com/ss_thumbnails/workingandfunctionsofrbi1-110522002449-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













![Csac10[1].p](https://cdn.slidesharecdn.com/ss_thumbnails/csac101-p-110520054545-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![Csac08[1].p](https://cdn.slidesharecdn.com/ss_thumbnails/csac081-p-110520054521-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![Csac05[1].p](https://cdn.slidesharecdn.com/ss_thumbnails/csac051-p-110520054504-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![Csac14[1].p](https://cdn.slidesharecdn.com/ss_thumbnails/csac141-p-110520054443-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![Csac06[1].p](https://cdn.slidesharecdn.com/ss_thumbnails/csac061-p-110520054419-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















