Download as PDF, PPTX




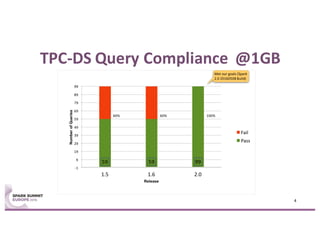
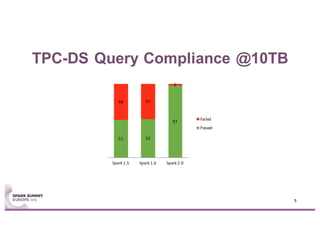
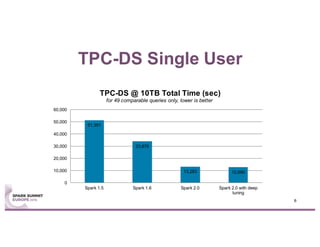
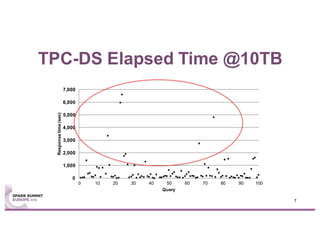










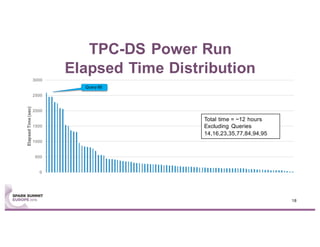

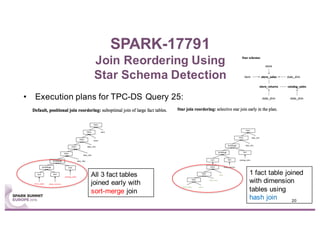


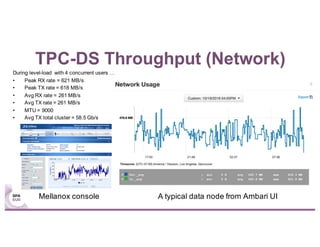
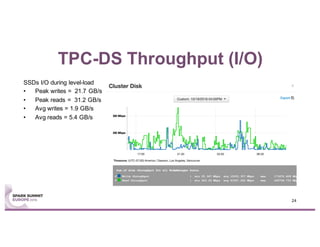








This document summarizes experiences using the TPC-DS benchmark with Spark SQL 2.0 and 2.1 on a large cluster designed for Spark. It describes the configuration of the "F1" cluster including its hardware, operating system, Spark, and network settings. Initial results show that Spark SQL 2.0 provides significant improvements over earlier versions. While most queries completed successfully, some queries failed or ran very slowly, indicating areas for further optimization.




































































































