Download as PDF, PPTX



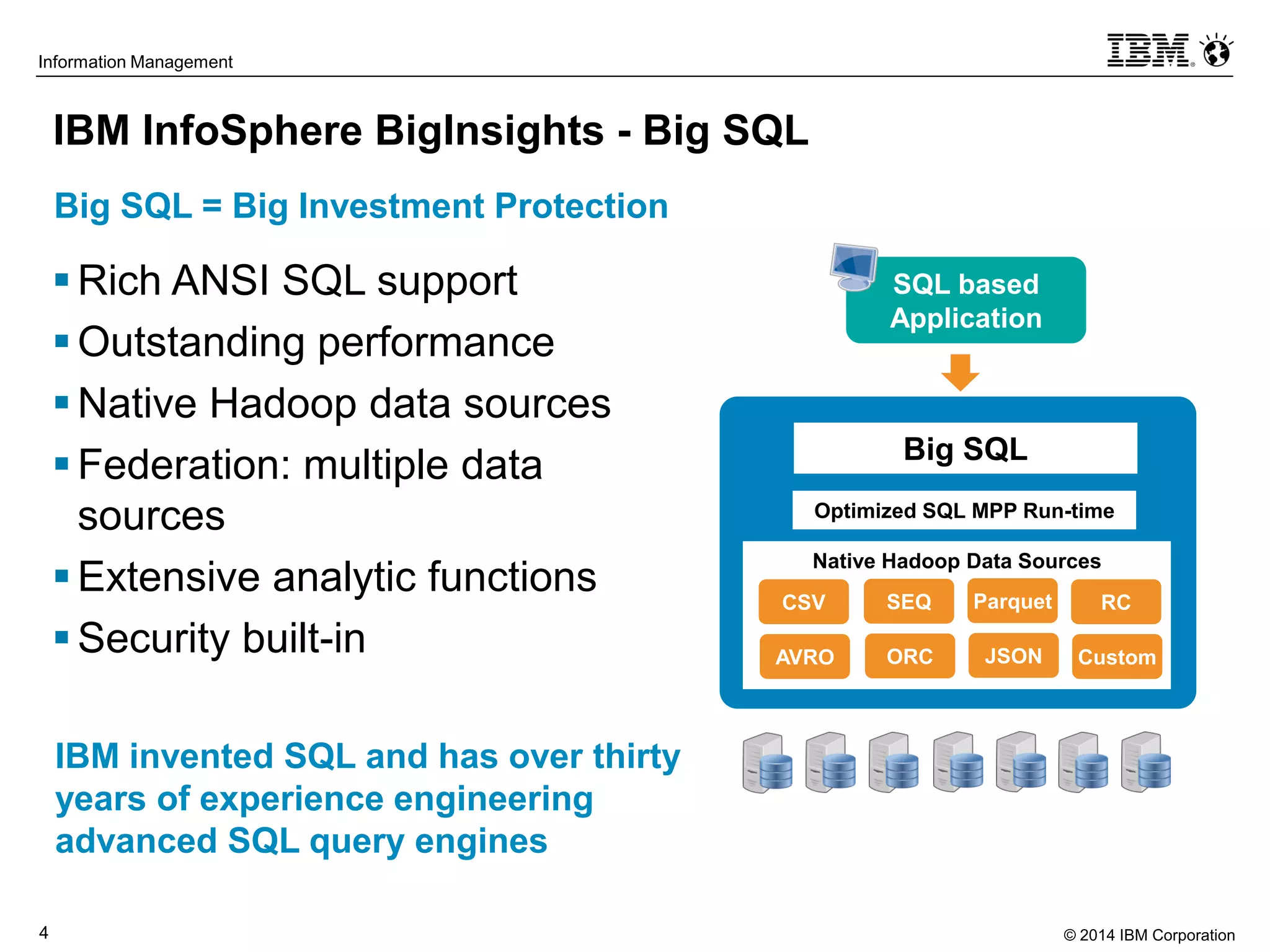
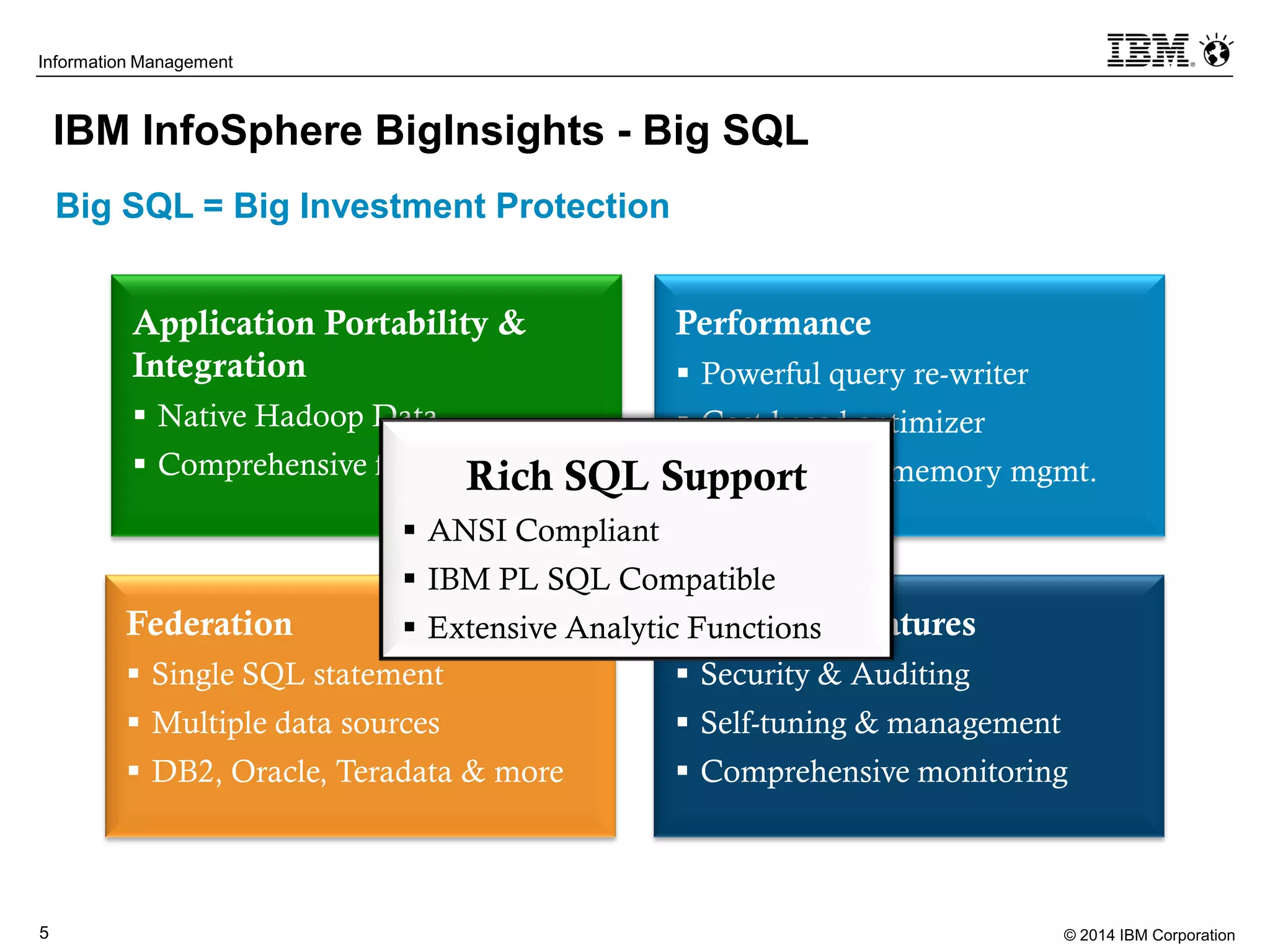






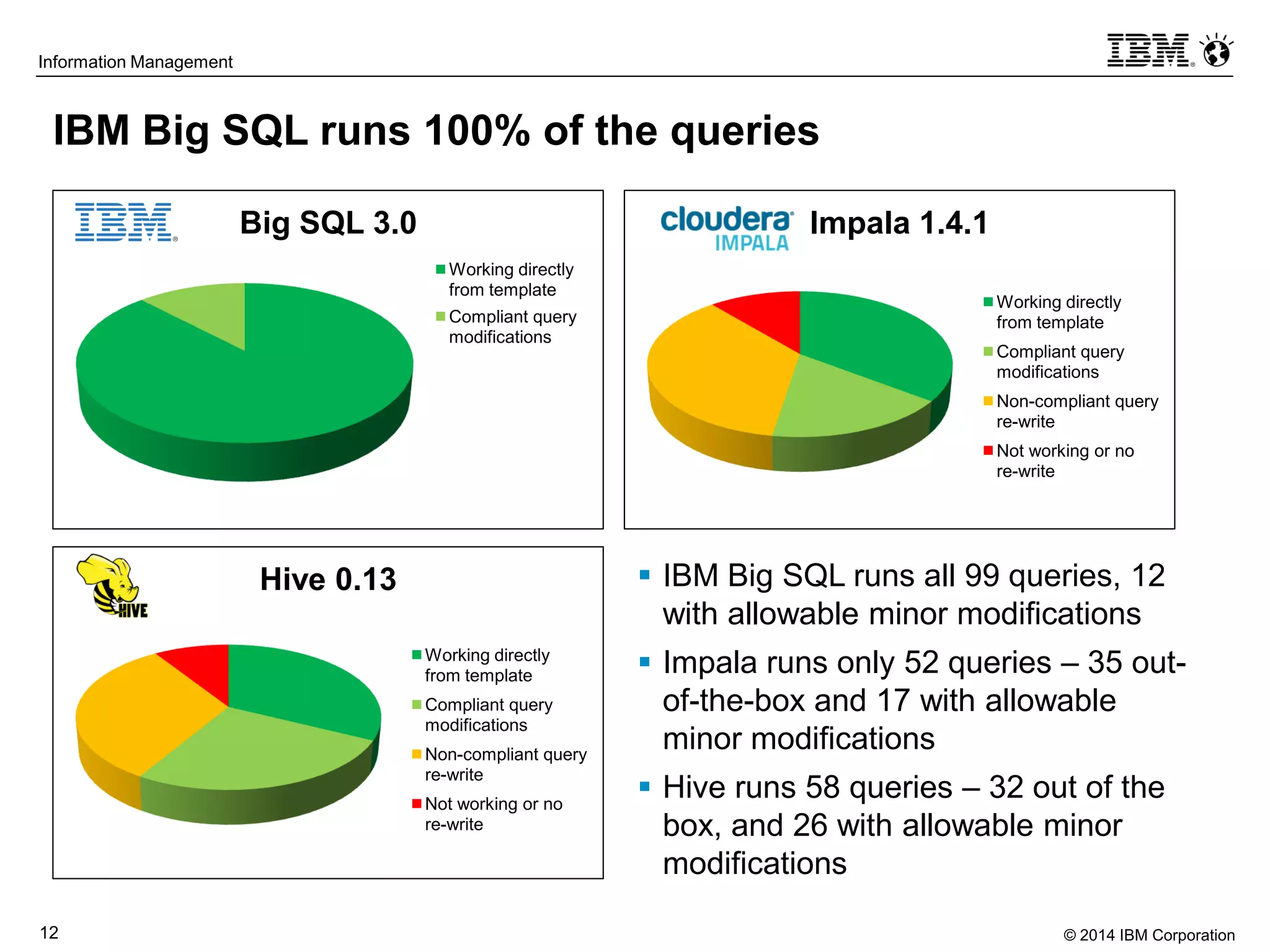
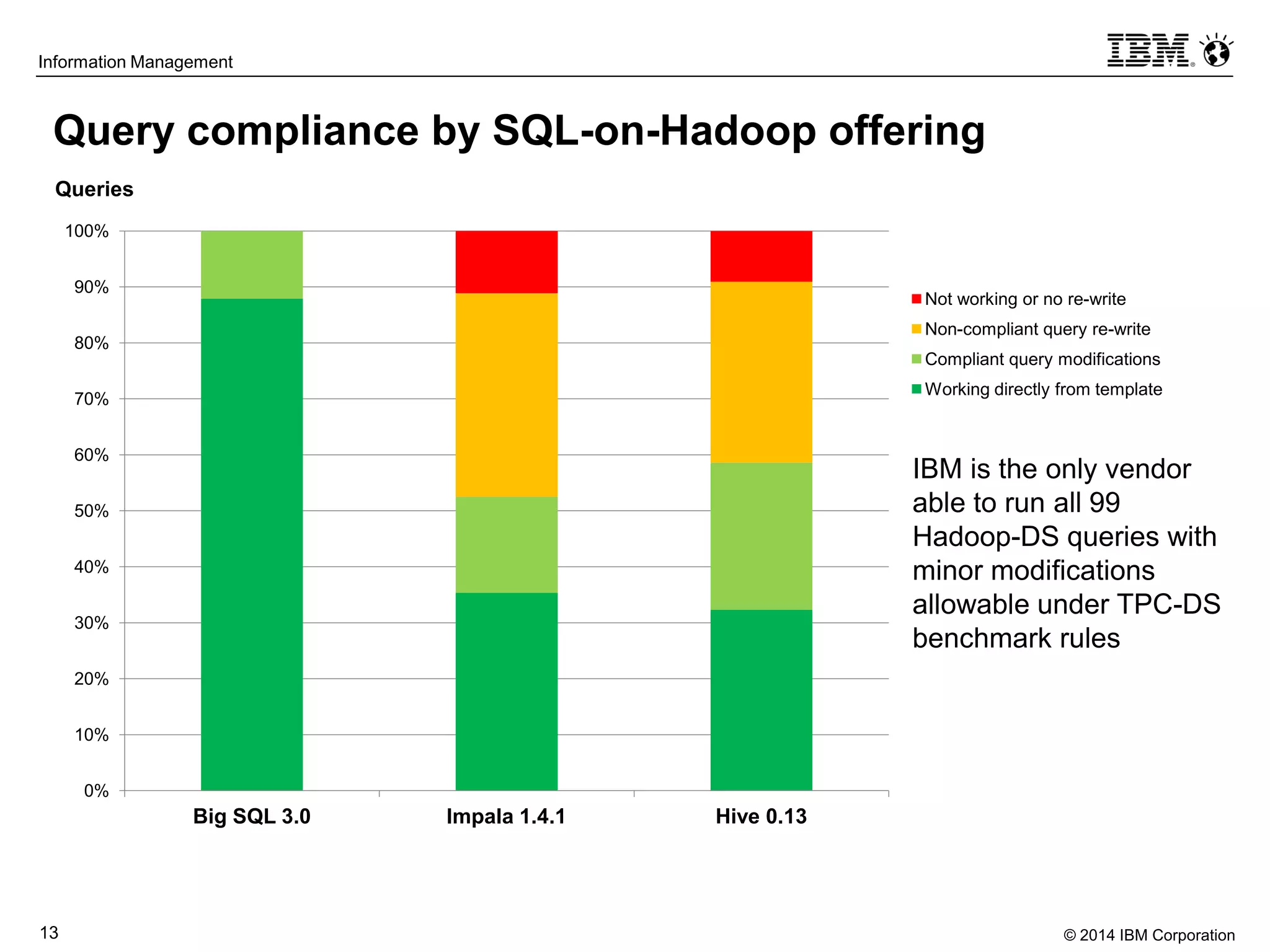
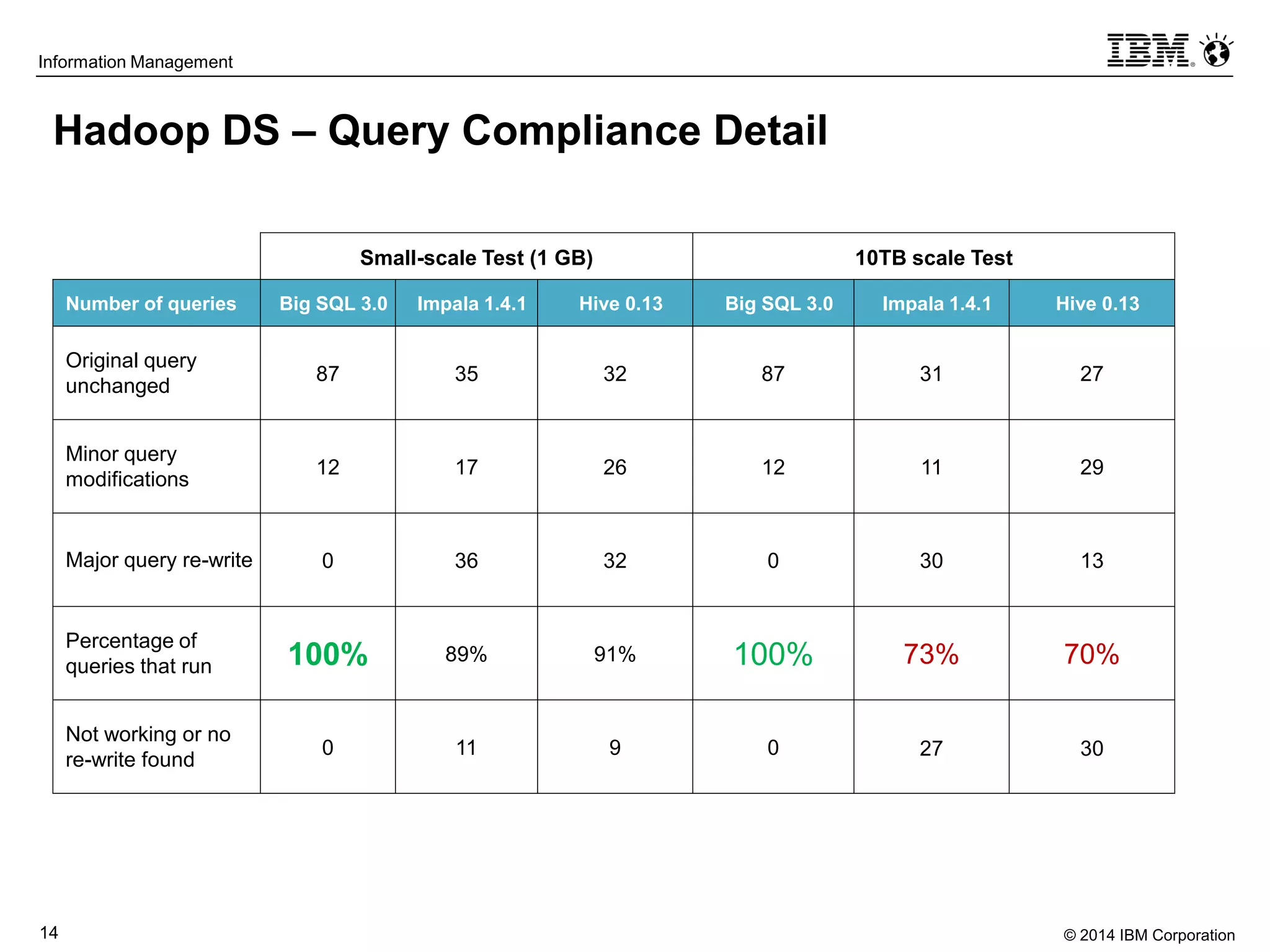

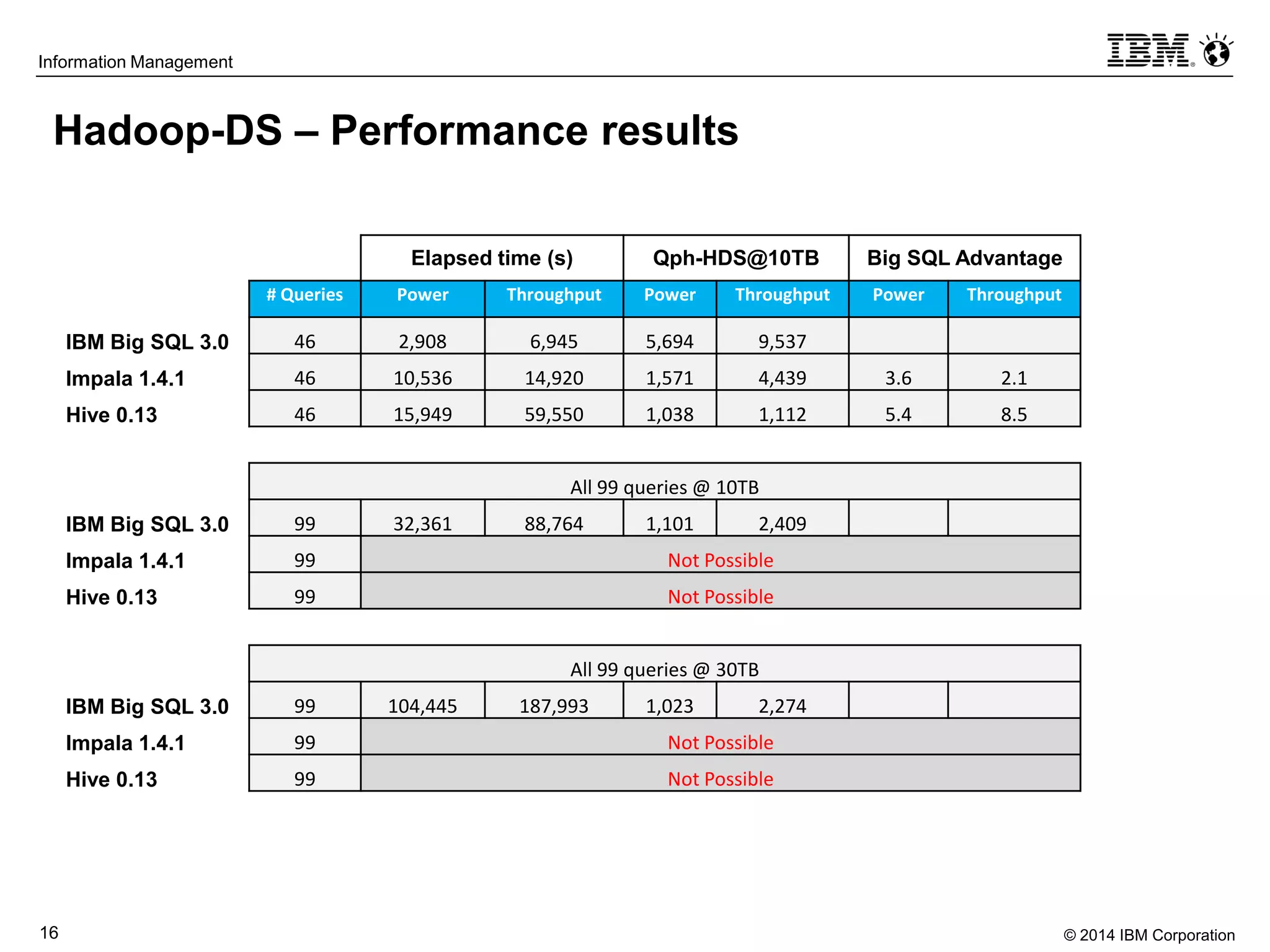
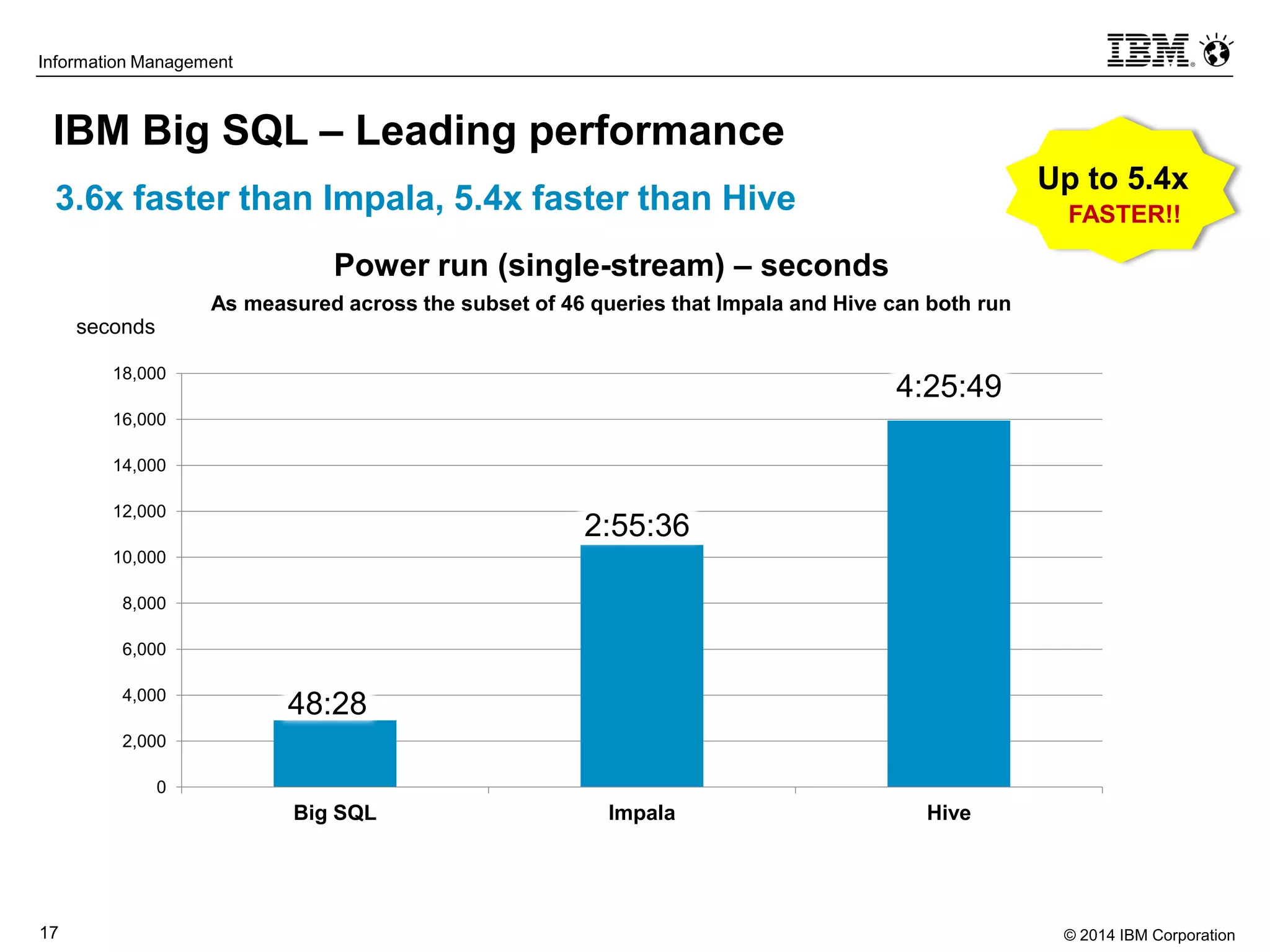
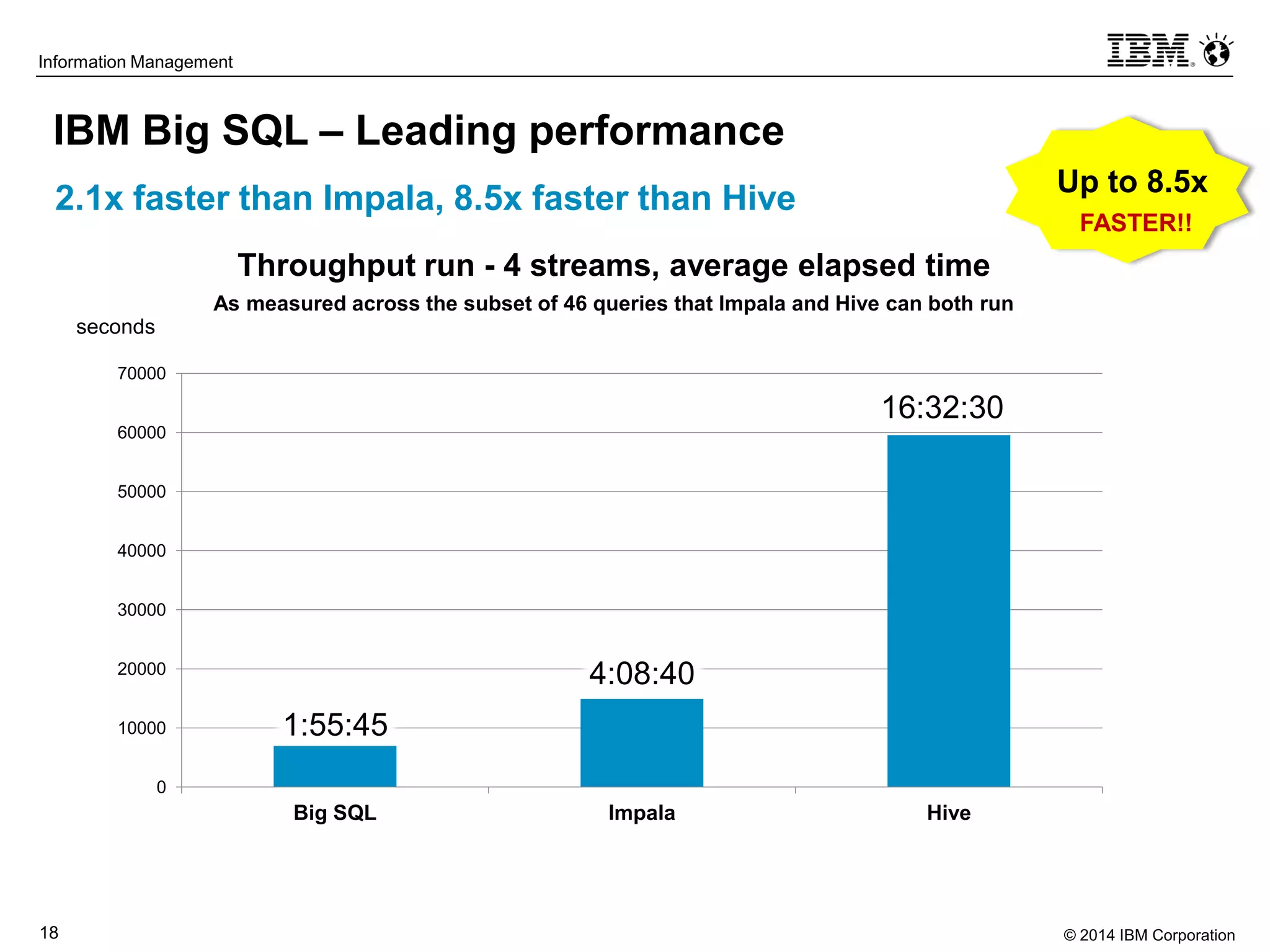

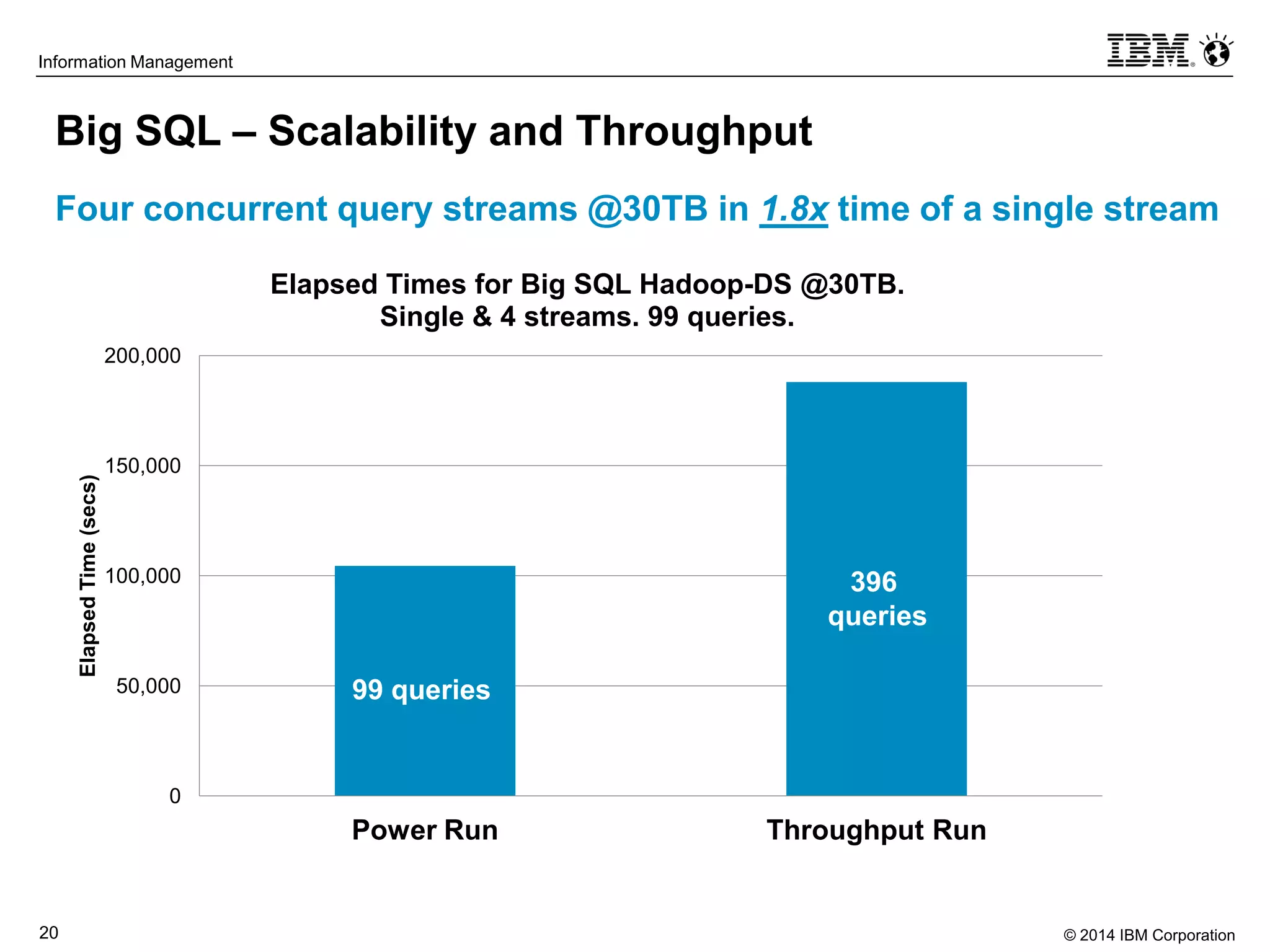
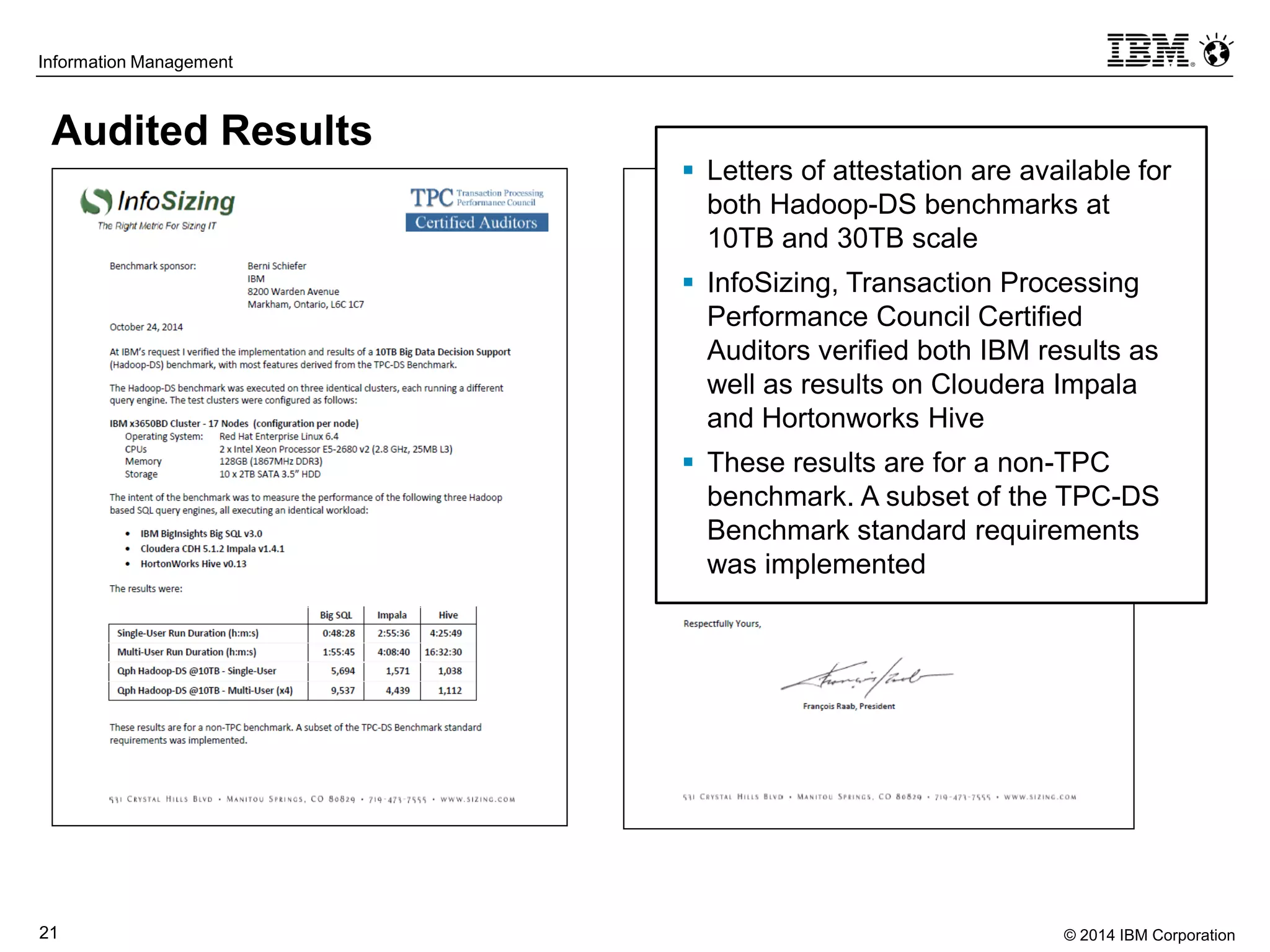



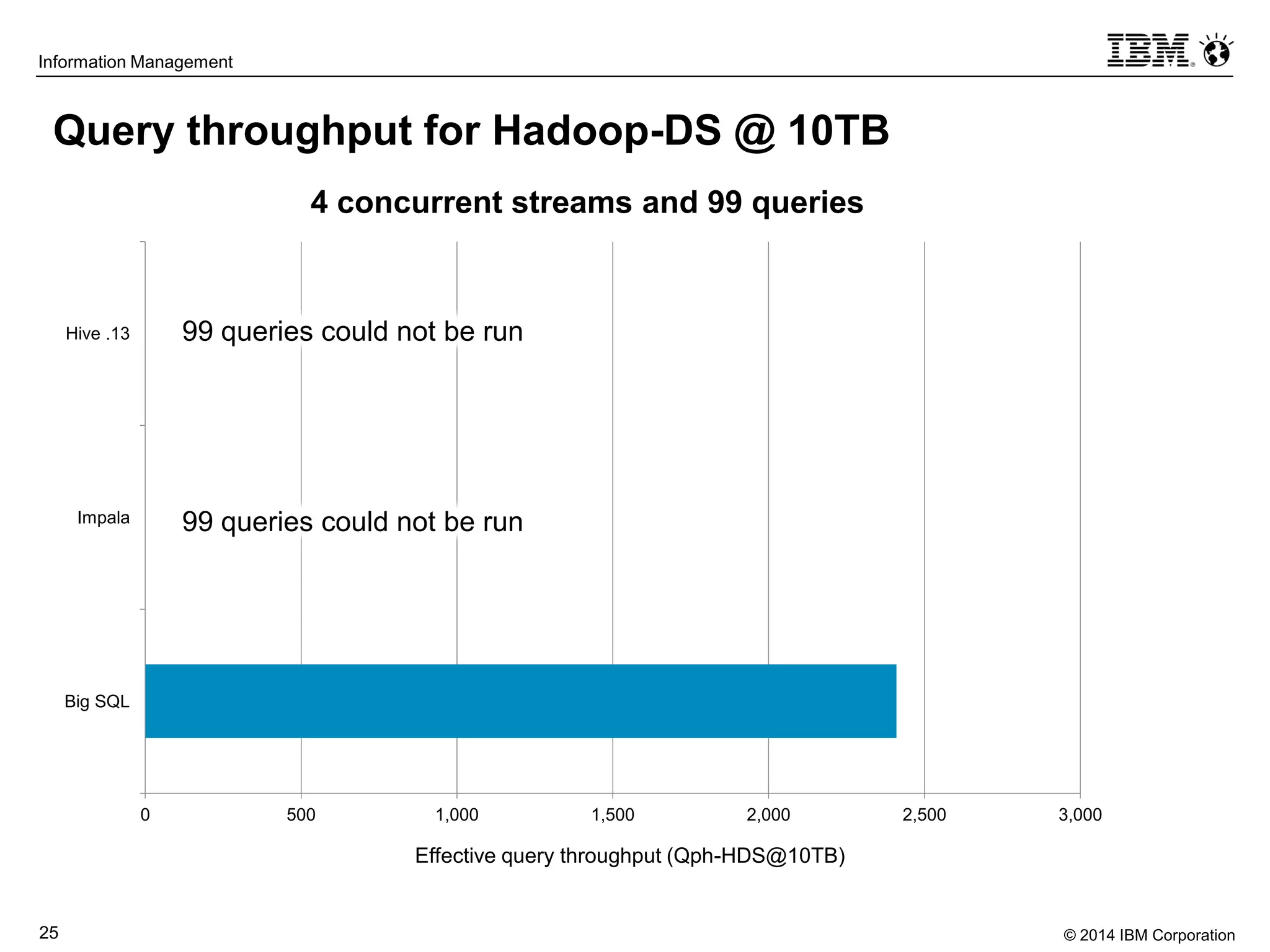
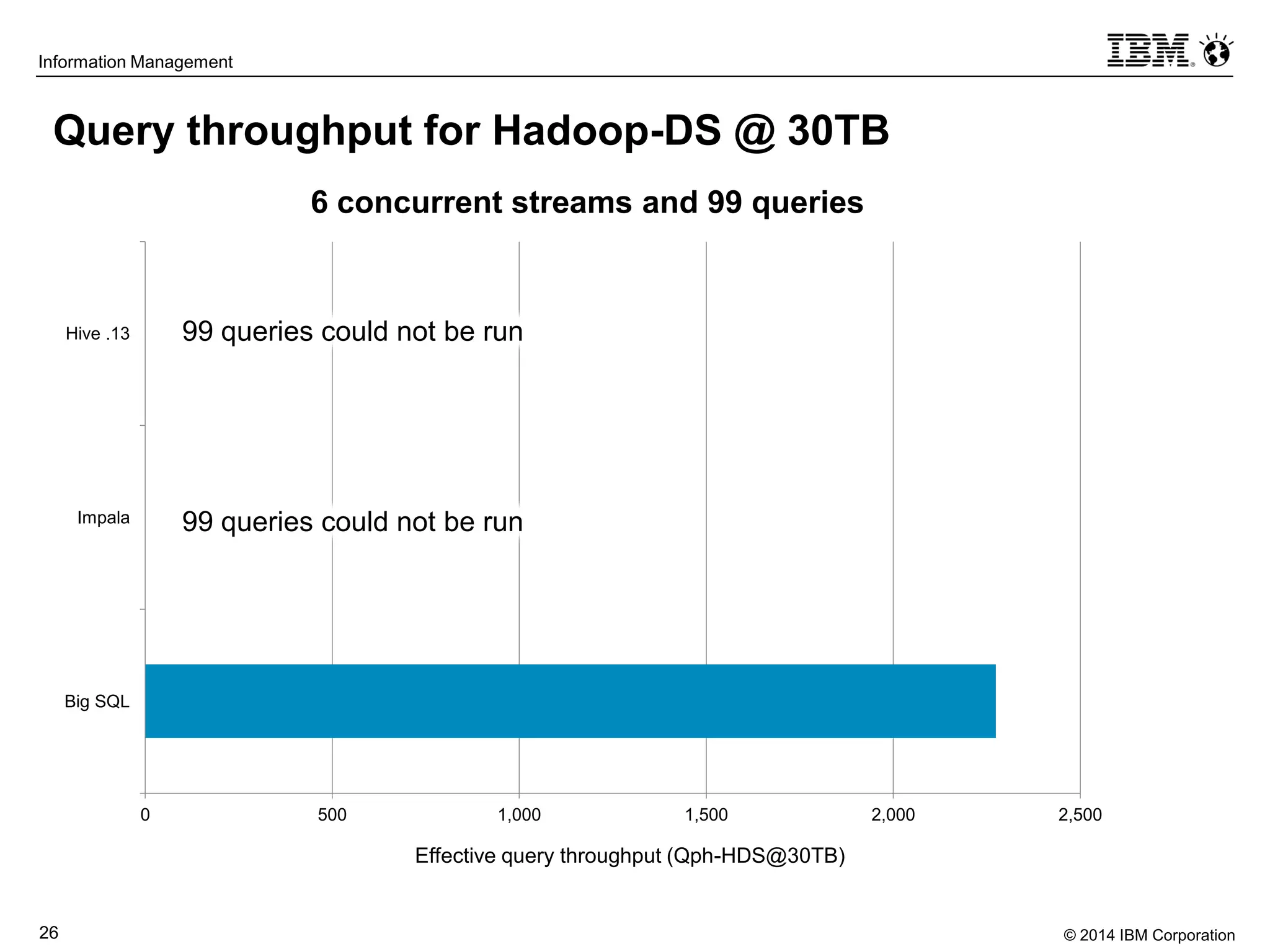


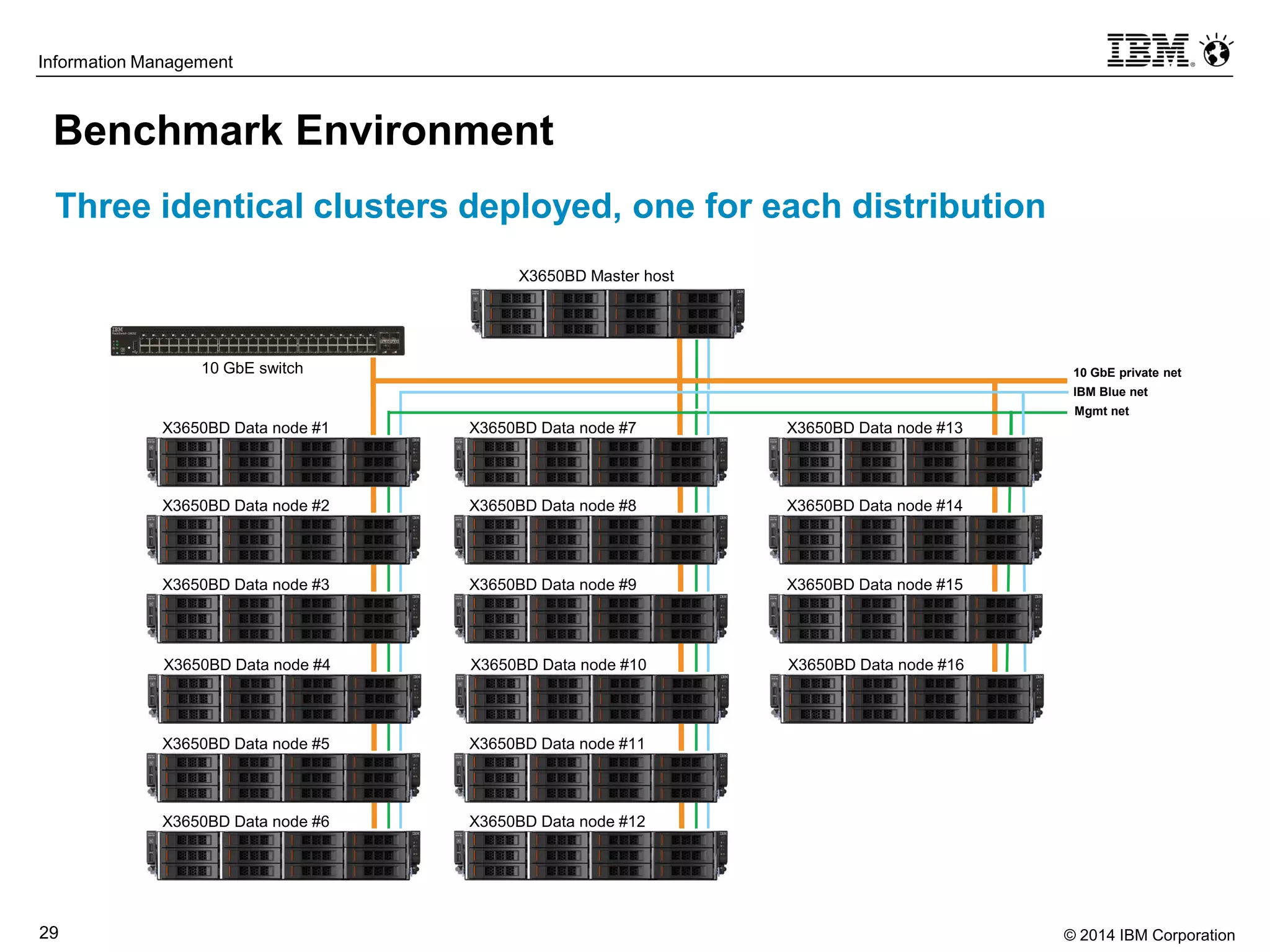

The document evaluates the performance and compatibility of IBM Big SQL in SQL-on-Hadoop environments, using benchmarks such as TPC-DS and the IBM-created Hadoop-DS. It finds Big SQL to outperform both Cloudera Impala and Hortonworks Hive significantly, running all benchmark queries while providing comprehensive support for ANSI SQL. Overall, the results suggest that Big SQL is the most capable and efficient solution for handling large-scale Hadoop data workloads.



















































































