






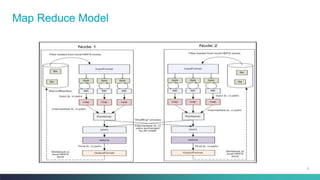






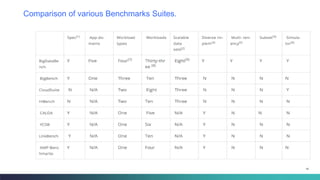
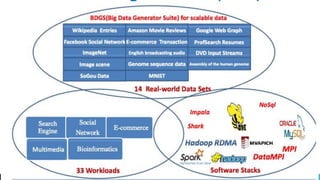
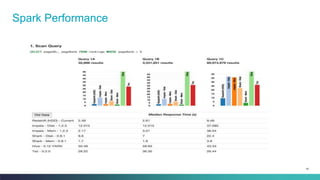
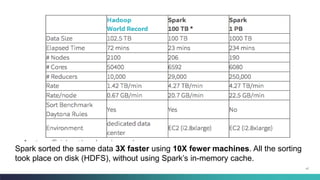


The document discusses various benchmarking methodologies in big data, including industry standard organizations and different types of benchmarks such as micro-benchmarks, component benchmarks, and application-level benchmarks. It highlights tools and frameworks like Hadoop and benchmarking suites including TPCX-HS and HiBench for evaluating performance metrics. Notably, Spark's efficiency in sorting data faster and with fewer resources compared to traditional methods is also mentioned.

































































































