






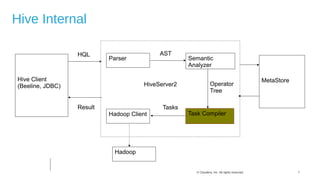
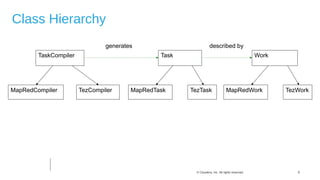
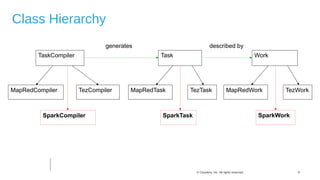



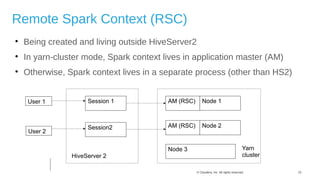


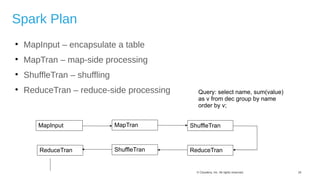










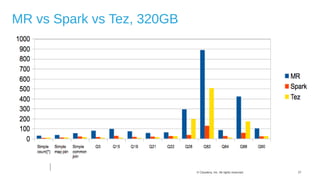
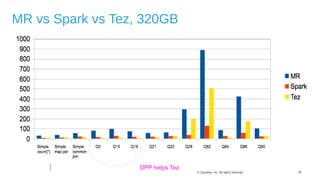

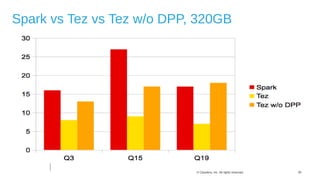
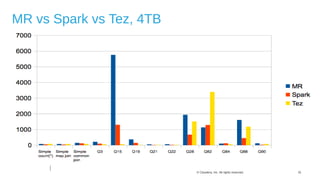
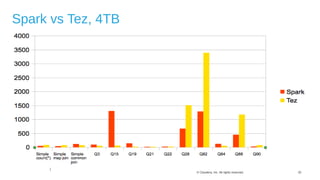
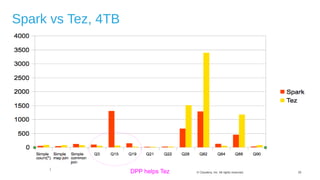
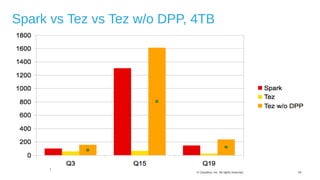
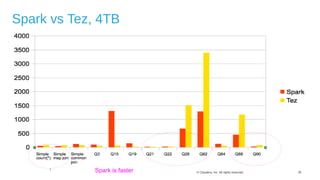
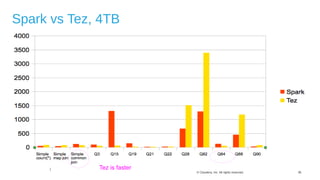



The document discusses Hive on Spark, a project to enable Apache Hive to run queries using Apache Spark. It provides background on Hive and Spark, outlines the architecture and design principles of Hive on Spark, and discusses challenges and optimizations. Benchmark results show that for some queries, Hive on Spark performs as fast as or faster than Hive on Tez, especially on larger datasets, though Tez with dynamic partition pruning is faster for some queries. Overall, the project aims to bring the benefits of Spark's faster processing to Hive users.




























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)













