Downloaded 162 times







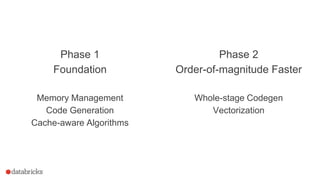















![Phase 1
Spark 1.4 - 1.6
Memory Management
Code Generation
Cache-aware Algorithms
Phase 2
Spark 2.0+
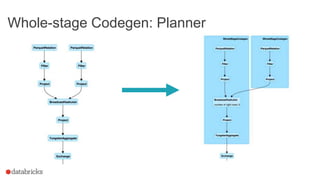
Whole-stage Code Generation
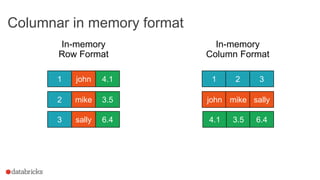
Columnar in Memory Support
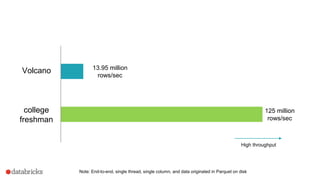
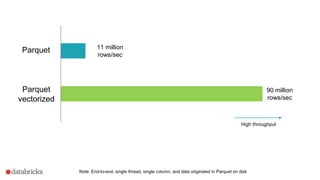
Both whole stage codegen [SPARK-12795] and the vectorized
parquet reader [SPARK-12992] are enabled by default in Spark 2.0+
Demo](https://image.slidesharecdn.com/sparkperf-sparksummiteu16-final-161103182837/85/Spark-Summit-EU-talk-by-Sameer-Agarwal-30-320.jpg)
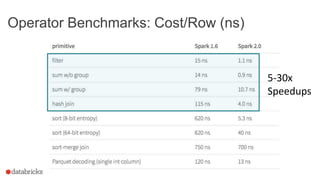
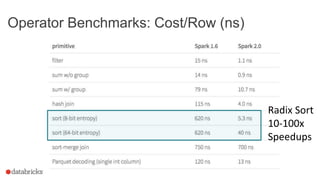
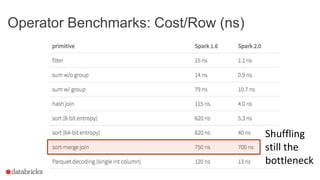
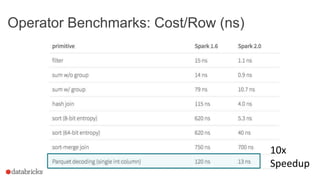
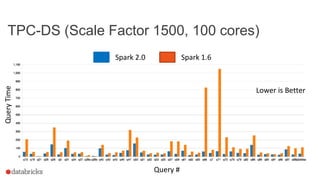





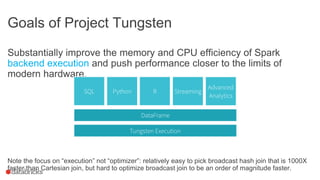
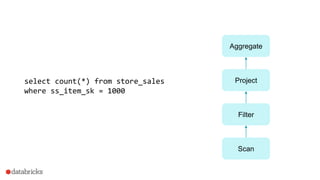
This document discusses Project Tungsten, which aims to substantially improve the memory and CPU efficiency of Spark. It describes how Spark has optimized IO but the CPU has become the bottleneck. Project Tungsten focuses on improving execution performance through techniques like explicit memory management, code generation, cache-aware algorithms, whole-stage code generation, and columnar in-memory data formats. It shows how these techniques provide significant performance improvements, such as 5-30x speedups on operators and 10-100x speedups on radix sort. Future work includes cost-based optimization and improving performance on many-core machines.

















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)





